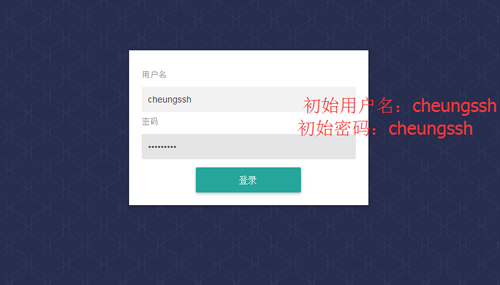
登录CheungSSH Web
温馨提示:
如果登录次数联系超过5次,那么系统会锁定登录IP一天时间。
首次登陆后修改密码,http://您的IP地址:端口/cheungssh/admin/ 。
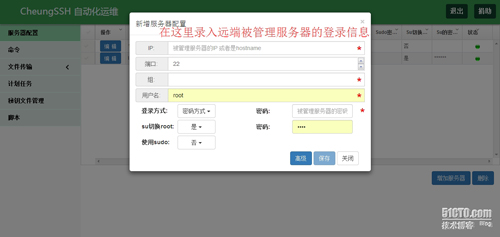
添加被管理主机配置信息
◆点击 “增加服务器”
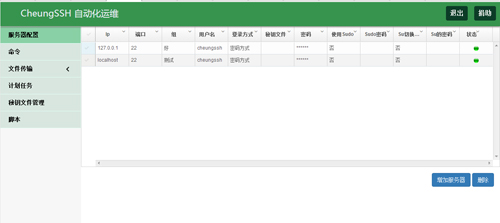
◆添加好以后,如下:
普通配置
这里,我们考虑的是,不需要被管理服务器做任何的配置,哪怕是像某些工具需要SSH-key绑定一样。在CheungSSH中,完全不需要,因为我要做的是简单,再简单!所以,在添加被管理服务器的时候,你只需要填写被管理服务器的登录密码,或者是SSH-key,就是你平时登录服务器的方式,简单易懂!
所以,我根本不需要多做介绍,当你看到界面的时候,你一下就能明白!应该填写什么信息。请相信CheungSSH,我们要做的,就是让用户感觉简单!
高级配置
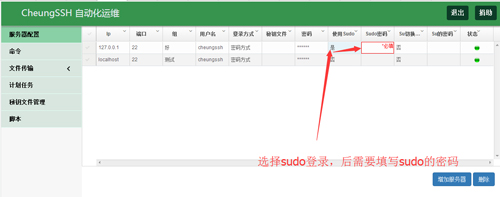
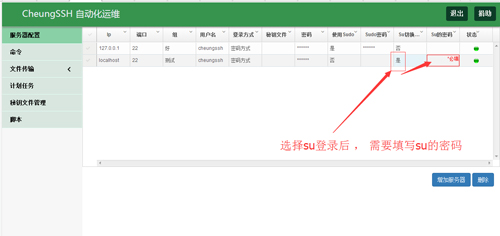
◆sudo登录
您可以选择sudo为“是”表示执行命令的时候,是启用了sudo,并且在执行命令的时候不用输入sudo开头,直接是命令,比如原本是sudo ifconfig,现在只需要 ifconfig,CheungSSH为您自动切换。
su - root
您可以选择su为是; 表示执行命令的时候,是启用了su - root,并且在执行命令的时候不用输入su - root开头, 直接是命令, 比如原本是su - root后,执行 ifconfig,现在只需要 ifconfig,CheungSSH为您自动切换。
◆执行命令
应用场景:执行一个whoami的命令,请记得,这个命令是在被管理的远程服务器上执行的。
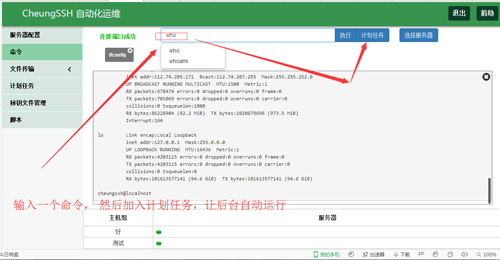
命令回显,功能区域介绍:

- 关于websocket:
- class WebSocketServer(object):
- def __init__(self):
- self.socket = None
- def begin(self):
- print( 'WebSocketServer Start!')
- self.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- self.socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
- self.socket.bind(("0.0.0.0",1337))
- self.socket.listen(50)
- global connectionlist
- while True:
- i=str(random.randint(90000000000000000000,99999999999999999999))
- connection, address = self.socket.accept()
- print '客户端ip',address
- username=address[0]
- ie_key='connection'+i
- path="/"
- newSocket = WebSocket(connection,i,username,address,path,ie_key)
- newSocket.start() #开始线程,执行run函数
- connectionlist[ie_key]=connection
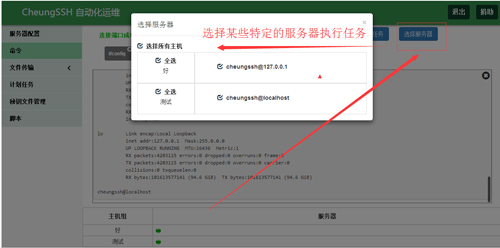
选择服务器
应用场景:假如您现网有一万台服务器,那么本次您只想对其中的一千台服务器进行操作,那么您可以挑选出要执行任务的主机。
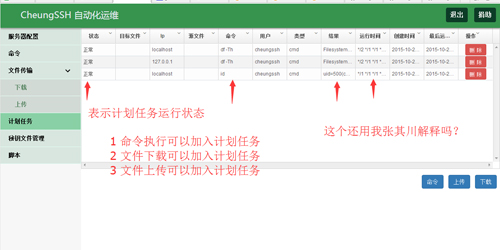
添加计划任务
应用场景:
加入今晚需要对一部分的主机在24:00的时候执行一些命令,用来收集服务器的信息。此时,您使用该功能就不用值夜了,交给CheungSSH的计划任务模块,那么,您就可以安心睡大觉了。

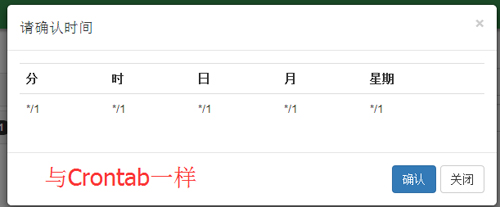
选择计划任务的时间,这里与Linux系统的 分 时 日 月 星期 一一对应:
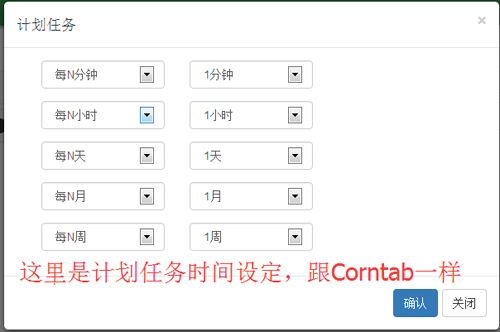
确认计划任务的时间,可以看到这个时间格式跟Linux系统的一模一样,没错,我们就是把它做成了操作系统的crontab功能:
查看计划任务
CheungSSH计划任务查看
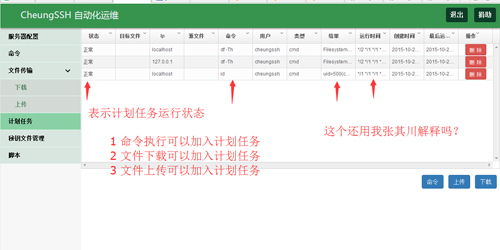
操作系统计划任务查看
- [root@cheungssh bin]# crontab -l
- */1 */1 */1 */1 */1 /home/cheungssh/mysite/mysite/cheungssh/daemon_FileTransfer.py '{"status": "\u672a\u542f\u52a8", "lasttime": "2015-10-25 18:45:20", "cmd": "", "createtime": "2015-10-25 18:45:20", "sfile": "/var/log", "user": "bo", "fid": "92262569677243366214", "runtype": "download", "runtime": "*/1 */1 */1 */1 */1", "id": "99556469106"}' #92262569677243366214
- */1 */1 */1 */1 */1 /home/cheungssh/bin/cheungssh_web.py 94246137977316460425
- */1 */1 */1 */1 */1 /home/cheungssh/bin/cheungssh_web.py 91254503983769069002
- [root@cheungssh bin]#
提示:
CheungSSH还是为了用户考虑,通过以上的计划任务, 您可能知道怎么用, 但是对于计划任务的结果, 运行流程,是感觉不清晰的。在这里,我想我有必要向您解释一下,还是那句话,CheungSSH要做到的是,让用户感觉简单,并且要真正让用户使用起来简单。所以,这个计划任务的原理是:在CheungSSH控制机器上做的计划任务,并没有在被管理的服务器上做计划任务,这样,就能为您降低更多运营成本,重要的是,还不变动您的被管理机器,再一次做到稳定!降低复杂度!
文件下载
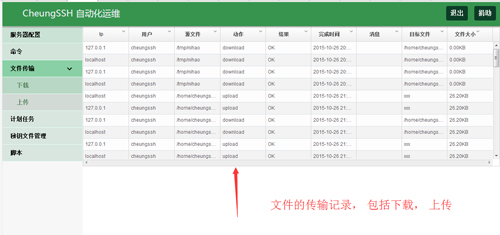
文件传输记录
应用场景:对于所有的上传、下载文件的记录,我们都做了记录,下面是传输的记录:
文件下载
应用场景:在远程被管理的服务器上有一个文件,此时如果您需要获取文件内容,那么,您可以使用我们的下载功能,把远程服务器上的文件下载到CheungSSH服务器上,然后从CheungSSH服务器再下载到您的本地电脑PC机器上,然后神奇的是,这一切过程,都是自动的!
友情提示:不仅支持文件下载,还支持目录下载哦!
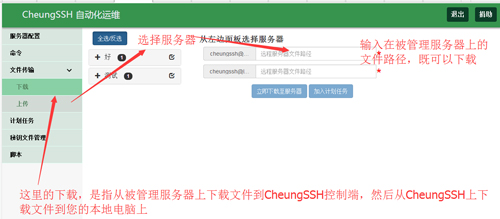

从远程服务器下载文件到CheungSSH上以后,自动弹出下载成功的文件,并且,显示没有下载成功的文件:
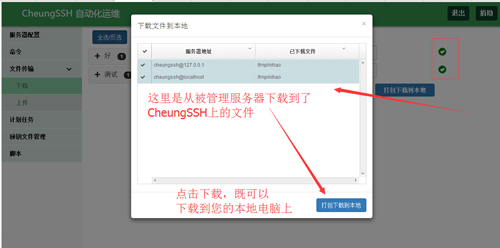
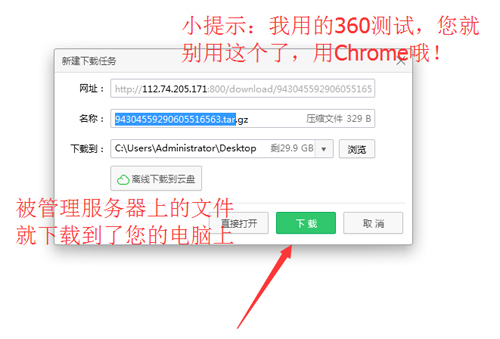
从CheungSSH上下载刚才从远程服务器上下载的文件到您的本地电脑上:
文件上传
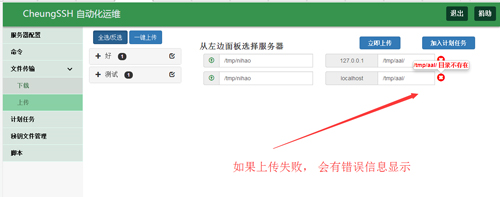
应用场景:假如您需要更新或者上传一些文件到被管理服务器上,那么,这里您可以使用上传功能:
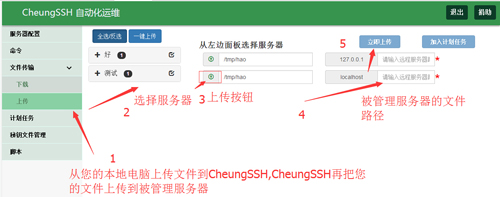
文件上传和下载,都有进度显示的哦!
- 其实我们利用的就是paramiko的SFTP函数实现的:
- def UpdateFile(ip,port,username,password,UseKey,sfile,dfile):
- try:
- t=paramiko.Transport((ip,port))
- if UseKey=="Y":
- KeyPath=os.path.expanduser('~/.ssh/id_rsa')
- key=paramiko.RSAKey.from_private_key_file(KeyPath)
- t.connect(username = username,pkey=key)
- else:
- t.connect(username = username,password = password)
- sftp = paramiko.SFTPClient.from_transport(t)
- ret=sftp.put(sfile,dfile)
温馨提示:您依然可以上传一个文件夹的哦!
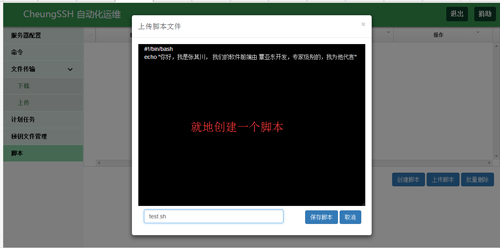
脚本管理
执行脚本

开放API
◆主机信息API
◆服务器运行日志API
◆服务器状态检查API
◆文件传输API
◆命令执行API
◆资产信息API
◆计划任务API
◆更多API .....
◆更多功能
脚本执行
◆计划任务
◆权限审计
◆权限授权
◆安全设置
◆更多功能...
还有堡垒机角色...
这里不做一一介绍,当您看见了CheungSSH Web界面的时候,不需要我多做介绍了,您一眼就能看明白,这个东西应该怎么用!因为我们坚持做到简约!更简约!目前有800个单位和用户,他们很少问我这个功能如何使用,都是一看就明白!
作者介绍:

张其川,2012年参加工作,时年从事IT Linux运维工作;2013年,从事IT系统运维工作;2014年,先后从事运维、python开发工作;2015年,从事自动化运维工作,致力于运维 自动化技术研究。他擅长Linux系列Redhat、Centos操作系统管理、Oracel数据库DBA维护,目前任职python高级运维开发工程师。
