基于 HBase 做 Storm 实时计算指标存储
HBase 实时指标存储是我入职乐视云后对原有的实时系统改造的
一部分。部分分享内容其实还处于实施阶段。架构方案设计的话应该是仁者见仁智者见智,也会有很多考虑不周的地方,欢迎大家批评指正。说不定大家听完分享后好的提议我们会用到工程上,也为后面的实际课程做好准备。
HBase 存储设计
Storm 结果如何存储到 HBase
HBase 写入性能优化
与传统方案 (Redis/MySQL) 对比
乐视云内部用 Storm 做 CDN,点播,直播流量的计算,同时还有慢速比,卡顿比等统计指标。相应的指标会由指标名称,业务类型,客户,地域,ISP 等多个维度组成。指标计算一个比较大的问题是 Key 的集合很大。
举个例子,假设我们有客户 10w,计算指标假设 100 个,5 个 ISP,30 个地域,这样就有亿级以上的 Key 了,我们还要统计分钟级别,小时级别,天级别,月级别。所以写入量和存储量都不小。
如果采用 Redis/Memcached 写入速度是没有问题的,毕竟完全的内存操作。但是 key 集合太大,其实压力也蛮大的,我去的时候因为加了指标,结果导致 Memcache 被写爆了,所以紧急做了扩容。
首先是 Redis 查起来的太麻烦。客户端为了某个查询,需要汇总成千上万个 Key。。。业务方表示很蛋疼,我们也表示很蛋疼
其次,内存是有限的,只能存当天的。以前的数据需要转存。
第三,你还是绕不过持久化存储,于是引入 MySQL,现在是每天一张表。那 Redis 导入到 MySQL 本身就麻烦。所以工作量多了,查询也麻烦,查一个月半年的数据就吐血了。
鉴于以上原因,我们就想着有没有更合适的方案。
我们首先就想到了 HBase,因为 HBase 还是具有蛮强悍的写入性功能以及优秀的可扩展性。而事实上经过调研,我们发现 HBase 还是非常适合指标查询的,可以有效的通过列来减少 key 的数量。
举个例子,我现在想绘制某一个视频昨天每一分钟的播放量的曲线图。如果是 Redis,你很可能需要查询 1440 个 Key。如果是 HBase,只要一条记录就搞定。
我们现在上图:
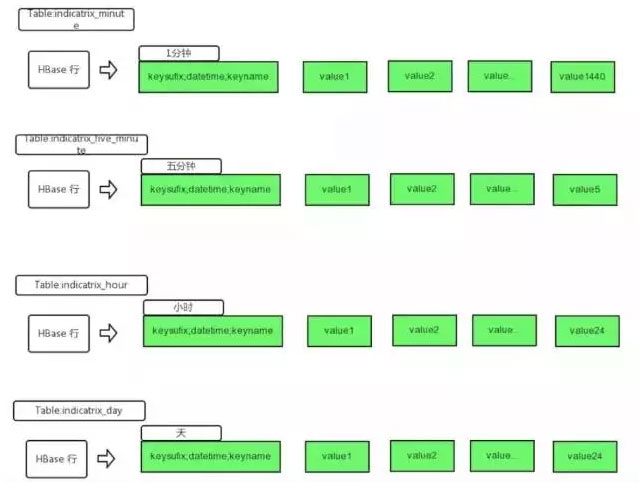
这里,我们一行可以追踪某个指标一天的情况。如果加再加个维度,无非增加一条记录。而如果是 redis,可能就多了一倍,也就是 2880 个 key 了。
假设该视频是 A,已经在线上 100 天了。我们会记录这个视频所有的 1 分钟播放数,用 Redis 可能有 100*1440 个 key,但是 HBase只要获取 100 条记录就可以找出来,我们把时间粒度转化为了 hbase 的列,从而减少行 (Key)。
我们知道 HBase 是可以多列族,多 Column,Schemaless 的。所以这里,我们建了一个列族,在该列族上,直接建了 1440 个 Column。Column 的数目和时间粒度有关。如果是一分钟粒度,会有 1440 个,如果是五分钟粒度的会有 288 个,如果是小时粒度的,会有 24 个。不同的粒度,我们会建不同的表。
写入的时候,我们可以定位到 rowkey,以及对应的 column,这里一般不会存在并发写。当然 HBase 的 increment 已经解决了并发问题,但是会造成一定的性能影响。
查询的时候,可根据天的区间查出一条相应的记录。我们是直接把记录都取出来,Column 只是一个 Int/Long 类型,所以 1440 个 Column 数据也不算大。
Storm 计算这一块,还有一个比较有意思的地方。假设 A 指标是五分钟粒度的,也就是说我们会存储 A 指标每个五分钟的值。但是在实际做存储的时候,他并不是五分钟结束后就往 HBase 里存储,而是每隔(几秒/或者一定条数后)就 increment 到 HBase 中,然后清除重新计数。
这里其实我要强调的是,到 HBase 并不是覆盖某个 Rowkey 特定的 Cloumn 值,而是在它原有的基础上,做加法。这样做可以防止时间周期比较长的指标,其累计值不会因为有拓扑当掉了而丢失数据(其实还是会丢的,但可能损失的计数比较少而已)。
丢数据比如你 kill-9 了。
大家可以想象一下,如果我计算一个五分钟的指标,到第三分钟挂掉了,此时累计值是 1000,接着拓扑重启了,五分钟还没完,剩下的两分钟它会接着累计,此时是 500。如果是覆盖写,就会得到不正确的结果,实际上整个完整的计数是 1500。
防止拓扑当掉并不是这样设计的主要原因,还有一点是计算延时了,比如某个数据片段因为某个原因,延时了十分钟才到 Storm 实时计算集群,这个时候新得到的值还可以加回去,如果是覆盖,数据就错误了。
所以 HBase 存储这块就变成做加法操作而不仅仅是简单的更新了。目前 HBase 添加了计数的功能 (Incrment),但是我发现跨行,没有批量更新的的接口。
而 HBase 的 Client 也是非常的奇特,比如 HTablePool 竟然是对象池而不是链接池,多个 HTable 对象是共享一个 Connection 链接的。当然,这里 HTable 的 Connection 会比较复杂,因为要连 Zookeeper 还有各个 Region。
又没有批量接口,一个 Client 只能有一个 Connection 链接,所以导致客户端的写入量死活上不去。16 台 32G,24 核的服务器,我做了预分区 (60个左右),用了四十个进程,300 个左右的线程去写,也就只能写到 60000/s 而已。
但实际并发应该是只有 40 左右的。300 个线程并没有起到太多作用。
还有就是,HBase 的 incrementColumnValue 的性能确实不高。至少和批量 Put 差距很大。
但在我们的测试中,还是比较平稳的,整个写入状态。抖动不大。
这里要强调一点,HBase 看场景,在我们这个场景下是预分区是非常重要的。否则一开始都集中在一台机器的一个 Regin 上写,估计很快写的进程就都堵住了。上线就会挂。
所以我事先收集了几天的 key,然后预先根据 key 的分布做了分区。我测试过,在我们的集群上,到了 60 个分区就是一个瓶颈,再加分区已经不能提升写入量。
写入我们也做了些优化,因为写的线程和 Storm 是混用的(其实就是 Storm 在写)。我们不能堵住了 Storm。
当用户提交了N条记录进行更新操作,我会做如下操作:
将N条分成10份,每份N/10条。
每个JVM实例会构建一个拥有10个线程的线程池。
线程池中的每个线程都会维护一个Connection(通过ThreadLocal完成)。
线程会对自己的这N/10条数据顺序进行incrementColumnValue。
做这个优化的原因是我上面提到的,HTable 的连接池是共享 Connnection 的。我们这里是为了让每个线程都有一个 Connection。具体分成多少份(我这里采用的是 10),是需要根据 CPU 来考量的。我们的服务器 CPU 并不是很多。值不是越大越好。如果太大,比如我起了 40 个虚拟机。每个虚拟机 10 个线程,那么会有 400 个到 Zookeeper 和 HBase 的连接。值设置的过大,会对 Zookeeper 有一定的压力。
这种方案我测试的结果是:
吞吐量上去了。在 1500w 左右的测试数据中,原有的方式大概平均只有 3w/s 左右的写入量。 通过新的方式,大概可以提高到 5.4w/s,只要 4 分钟左右就能完成 1500w 条数据的写入。
峰值略微提升了一些。之前大约 6.1w/s,现在可以达到 6.6w/s。
因为我用同一集群上的 Spark 模拟的提交,所以可能会对 HBase 的写入有一点影响,如果想要继续提升写入性能,只能重写 HBase 这块客户端的代码。
我们总结下上面的内容:
Redis/Mysql 存储方案存在的一些缺点。
HBase 表结构设计,充分李永乐 HBase 自身的特点,有效的减少Key的数量,提高查询效率。
Storm 写入方案,用以保证出现数据延时或者 Storm 拓扑当掉后不会导致数据不可用。
我们再看看整个存储体系完整的拓扑图。
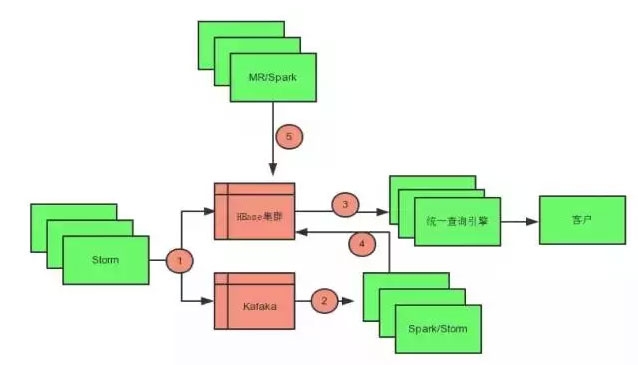
第五个圆圈是为了在实时计算出错时,通过 Spark/MR 进行数据恢复。
第二个圆圈和第四个圆圈是为了做维度复制,比如我计算了五分钟的值,这些值其实可以自动叠加到对应的小时和天上。我们称为分裂程序
第三个圆圈就是对外吐出数据了,由我们的统一查询引擎对外提供支持查询支持了。
我们对查询做一个推演。如果我要给用户绘制流量的一个月曲线图。曲线的最小粒度是小时,小时的值是取 12 个五分钟里最高的值,我们看看需要取多少条记录完成这个查询。
我们需要取 31 条五分钟的记录,每条记录有 288 个点,对这 288 个点分成 24 份(具体就是把分钟去掉 groupBy 一下),求出每份里的最大值(每组 SortBy 一下),这样就得到了 24 个值。
我取过两天的,整个 HTTP 响应时间可以控制 50ms 左右(本机测试)。
上面的整体架构中,分裂程序是为了缓解实时写入 HBase 的压力,同时我们还利用 MR/Spark 做为恢复机制,如果实时计算产生问题,我们可以在小时内完成恢复操作,比如日志的收集程序、分拣程序、以及格式化程序。格式化程序处理完之后是 kafka,Storm 对接的是 Kafka 和 HBase。
上面就是今天分享的内容了。
本文作者:祝海林
来源:51CTO