
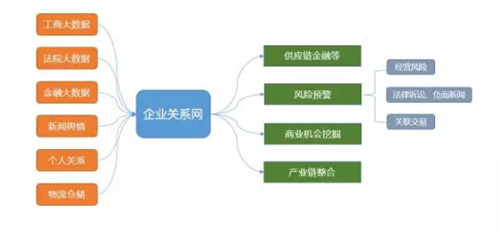
企业关系网络的数据构成
在早期经济发展期间,企业间的业务来往普遍是通过企业经营者与个人的交情或交情的转移发生的,即企业强势关系网的形成大部分依托于个人的人际关系。
随着各种法制法规的建立以及信息透明化步伐的加快,传统的关系网模式发生了一系列变化,以市场为中心的企业关系网逐渐得以发展,包括互联网、电子商务的崛起,使得企业逐渐摆脱了传统人情关系上的束缚,这也使得企业关系网迅速扩张。
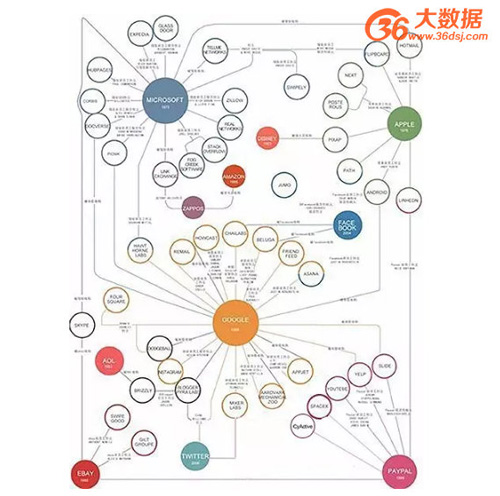
硅谷企业关系网络图
企业关系网络的数据构成如下图表示:
如何通过关系网络分析对企业进行动态评估
玩股票的朋友都知道,传统评估企业经营通过三张会计表:资产负债表、损益表、现金流量表,对个体历史数据竖向分析。但是市场是动态变化的,我们发现相较于对企业单体的分析,对关联企业间、行业间的全局量化评估显得更为重要。
借助大数据,我们可以将个体数据结构化,加之对经典企业评价方法的规则化,提炼出高阶的系统和个体的评估量化指标。通过对关系网络中企业往来交易的分析,我们能动态的分析出关系链条中企业的强壮性、活跃性、流通性。
通过强壮性分析,可以从公司资本实力、现金流稳定性、偿债能力等维度挖掘出关系链中哪些经济实体的抗风险能力强,将来在业务拓展时也可尽力多增加此类“高质量”客户,对于抗风险能力薄弱的企业实行淘汰机制,或者是降低此类公司在交易中的权重,一旦发生问题,也能有效的减少损失的金额。
通过活跃性分析,也就是通过在关系链中交易量、交易频率等的判断,我们得以发现正处于上升势头中的公司。很多中小微企业营业利润可观,发展前景良好,具有很大的融资需求,却经常遭遇融资碰壁。我们通过数据分析企业的发展前景和资金需求,既提高了银行对中小微企业的认知和判断,也缓解双方的信息不对称问题,有利于构筑资金需求方和银行间桥梁。
通过流通性的判断,能挖掘出关系链中较为关键的企业,因为大量的资金流动都会经由这些节点,这些企业也处于关系网中的关键地位。因此金融机构也需要重点关注此类企业,避免此类公司出现问题后整个上下游受到大面积影响,从而蒙受损失。
同时对经营指标的横向纵向比较,还能发现一些在供应链中,隐藏在大企业背后的质优企业,比如那些有着资金活跃度高,周转率快,行业壁垒高的公司。同样的贷款,其周期短、回款快。通过分析,金融机构可以给予这些企业更多的贷款优惠,通过定价优势来锁定获客,达到双赢。
行为评估比资产评估更适合供应链金融
小明同学的创业公司,不到一年就发展到300人,但是产品都卖出去了,货款迟迟未到账,日益紧张的资金链,让他自然而然的想到银行贷款。可是,当小明去银行咨询贷款的时候,银行第一个问题就是:你有房产做抵押吗?
早期的金融贷款模式,银行首先会对企业厂房、各种股票、汽车等资产进行评估,并作为抵押物来进行贷款。那么对于王老板的困境,有什么好的途径和方法能助力他解决资金周转的问题呢?
银行不愿放贷的原因,只不过在目前信用环境和信用氛围非常不理想的情况下,部分企业特别是小微企业报表数据的规范性和真实性欠缺,判断优质的小微客户并不容易,银行不得不谨慎。可见,银行与中小微企业之间的信息不对称是导致融资难和融资贵的重要原因之一。
随着数据化的深入,金融机构可以获取企业间的订单信息,物流信息,开具的票据信息,甚至是对公账户间的交易往来金额、交易频次、交易权重等。上述这些加之于原有的关系网络,进行关系行为的量化,便可以深化出一个更全面的经济体关系视图。每个经济实体的资金活跃性、资金回报率、资本周转时间、经销商的销售数据等,都可以在这张关系网中得以体现。
有了强有力的数据做支撑,针对小微企业的“供应链金融”便有了赖以生存的土壤。
供应链金融开始从交易行为中抽取事件作为评估依据,取代了传统用资产做信用评估的方式,实现了从资产评估到行为属性评估的跨越。
在商业银行的业务实践中,通常认为供应链金融的产品分为应收类(基于应收账款的融资)、预付类(预付款融资)和存货类(现货质押融资)三大类产品。
1 应收类产品主要应用于核心企业的上游融资,如销售已经完成,但尚未收妥货款。
2 预付类产品则主要用于核心企业的下游融资,银行给渠道商融资,预付采购款项给核心企业,核心企业发货给银行指定的物流监管企业,然后物流监管企业按照银行指令逐步放货给借款的渠道商,预付类产品是国内供应链金融业务的主要模式,但银行需要承担企业的销售风险,因而承担的市场风险较大。
3 存货类融资,主要分为现货融资和仓单融资两大类。在涉及货押的融资模式里,目前最大的问题是监管企业的职责边界、风险认定和收益权衡问题。
当上Boss的小明,其上述经历在众多中小企业主中还是比较普遍的。通过大数据对产品流、信息流、资金流的整合,通过对关系网络的深入研究,以供应链中核心企业出发,从根本上解决中小企业和银行间信息不对称的问题,真正做好风控,打破中小企业融资难的瓶颈,这是业内正在走的一条正的道路。
利用关系网络分析实施产业链整合
创业中的小明是一个有情怀的汉子。他的偶像是新晋世界首富阿曼西奥·奥特加。也许这个名字你并不熟悉,但是说到ZARA你一定知道。
是什么使得一家服装生产商的老板成为了世界首富?答案是其高效的供应链系统。其设计、生产、销售全由自己控制的SPA模式,从产品设计到成品运抵店铺,只需要12天左右。Zara对供应链进行高效的垂直整合,实现了对市场的快速反应,并使之成为企业核心竞争力。
Zara的成功让小明看到了产业链整合所能创造的价值。除了这种SPA模式外,大数据时代,还能通过什么别的方式去优化产业链提升企业竞争力?
其实,可以通过对产业链上相同类型企业的约束来提高企业的集中度,扩大市场势力,从而增加对市场价格的控制力,类似于产业联盟、价格联盟,从而获得垄断利润。
其次,通过对上下游企业施加纵向约束,使之接受一体化或准一体化的合约,通过产量或价格控制实现纵向的产业利润最大化。我们也可以通过这种方式实现C2B预售,订单预测的驱动方式降低成本和库存风险 。
再者,产业链上的主导企业可以通过股权并购或控股的方式对产业链上关键环节的企业实施控制, 以构筑通畅、稳定和完整的产业链。就好比新能源汽车产业链下,锂电池企业纷纷去谋求收购上游原材料厂商,以确保稳定的货源来满足源源不断的订单。
企业关系网更是排 “雷” 利器
大数据下的企业关系网,其风险预警,抑或是风控,是其的核心价值之一。没有一家企业乐于见到与自身相关联的上下游企业出现经营异常,我们都希望在风险即将降临前能有所预警,或者说当突发事件来临时我们能及早的获知,从而能够有充裕的时间进行应对。
一般来说,我们对风险信息的获取有如下几个途径:
1、企业自身经营指标分析。我们会结合企业自身同比、环比的数据,以及同地区同行业下的企业平均水平进行分析,得出合理的企业评分,通过评分的上升或下降清晰的获悉经营状况。
2、通过与企业所在供应链中与历史交易方的交易数据进行比较,分析其金额、频次、所占权重等,对其在供应链中的经营指标进行定量打分,及时发现经营异常的苗头。
3、通过法院数据,及时获悉关系网中企业的失信被执行记录 、法院公告、裁判文书、执行公告等,我们能及时了解到诸如拖欠工资,逾期欠款等负面事件,及时发现经营风险。
4、通过法院数据,及时获悉关系网中企业高管的失信被执行记录 、法院公告、裁判文书、执行公告等,我们能对公司管理者的异常行为进行监控,从管理者个人的角度对企业经营风险进行把控。
5、通过对新闻舆情的爬取,关联映射到相关企业及个人,判断对关系网中企业正面、负面影响,相关联的企业可及时采取相应的措施。
6、通过获取关系网中工商变更记录,抵质押情况,分析其对企业经营状况的影响。
7、内外部机构上送的企业逾期信息。
8、国内外行业趋势分析。
9、通过对企业关系网中相关企业的立体全方位信息监控,我们能提前预知风险,或者在风险已经发生时,通过已经搭建的企业关系网迅速的进行布防,将损失降到最低。
后记
在社会经济活动中,大量数据被记录且沉淀,信息化的发展、大数据的出现使得这些数据直接成为了新的生产资料,我们通过模型进行量化、预测,从而得以创造出新的价值。
本文作者:佚名
来源:51CTO
