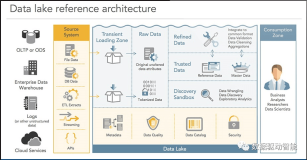
一、美国数据交易的典型模式
美国数据资产交易主要有三种模式。
第一种是数据平台 C2B 分销模式。用户将自己的个人数据贡献给数据平台,数据平台向用户给付一定数额的商品、货币、服务等价物或者优惠、打折、积分等对价利益。
第二种是数据平台 B2B 集中销售模式。数据平台以中间代理人身份为数据提供方和数据购买方提供数据交易撮合服务,数据提供方、数据购买方都是经交易平台审核认证、自愿从事数据买卖的实体公司;数据提供方往往选择一种交易平台支持的交易方式对数据自行定价出售,并按特定交易方式设定数据售卖期限及使用和转让条件。美国微软 Azure、Datamarket、Factual、Infochimps 等数据中间平台代理数据提供方、数据购买方进行的数据买卖活动,大多属于此类模式。
第三种是数据平台 B2B2C 分销集销混合模式。数据平台以数据经纪商(data broker)身份,收集用户个人数据并将其转让、共享与他人,主要以安客诚(Acxiom)、 Corelogic、Datalogix、eBureau、ID Analytics、Intelius、PeekYou、Rapleaf、Recorded Future 等数据经纪商为代表。
美国数据经纪商产业发展现状。在美国数据交易的三种主要模式中,第三种数据平台 B2B2C 分销集销混合模式发展迅速,目前已经形成相当市场规模,塑造了在美国数据产业中占据重要地位的数据经纪产业。
二、美国九大数据经纪商
Acxiom。为市场营销和欺诈侦探提供用户数据和分析服务,数据库中包括了全球范围内7亿用户的个人数据,其中包括涉及几乎每个美国用户的3000条数据段。
Corelogic。向商业和政府机构提供包括财产信息、消费信息和金融信息在内的用户数据及其分析服务,其数据库中包含7.95亿条资产交易历史数据、9300万条抵押贷款申请信息以及涵盖99%以上美国住宅物业的1.47亿条特定资产信息。
Datalogix。向商业机构提供涵盖几乎每个美国家庭、涉及金额超过1万亿美元以上的用户交易信息。2012年9月,Facebook 宣布与 Datalogix 建立合作伙伴关系,以便评测其10亿用户在社交网站上浏览某一产品广告的频次与其在某一实体零售店完成购买交易之间的关联关系。
eBureau。向营销商、金融公司、在线零售商以及其他商业主体提供预测评级和数据分析服务,最早只是分析某人是否可能成为潜在的优质客户或者某笔交易是否存在商业欺诈,后来发展为向其客户提供数以亿计的用户消费记录,而且每月还以300万条新增消费记录的速度在急速增长。
ID Analytics。主要提供以身份认证、交易欺诈检测和认证为目的的数据分析服务,其认证网络中包括了数以百亿计的数据集成点(aggregated data points)、11亿条独特的身份数据元素,涵盖了14亿条用户交易信息。
Intelius。向商业机构和客户提供背景调查和公开记录信息,其数据库中包含了200亿条以上的公开记录信息(public record information)。
PeekYou。拥有能够分析60家社交媒体网站、新闻来源、网站主页、博客平台内容的专利技术,向客户提供详细的用户配置文件(consumer profiles)。
Rapleaf。是一家数据集成商,拥有一个以上能够连接超过80%以上美国用户电子邮件地址的数据点以及30个其他类型的数据点,并且不断在其电子邮件地址列表中增补电子邮件用户年龄、性别、婚姻状况等信息。
Recorded Future。通过互联网捕捉用户和企业的各类历史数据,利用该类历史数据分析用户和企业的未来行为轨迹,截至2014年5月,已经实现对502,591家不同开放互联网站点各类信息的接入和抓取功能。
三、美国数据经纪商从哪采集数据
美国数据经纪商不是直接从用户处收集数据,而是主要通过政府来源、商业来源和其他公开可用来源等三个途径收集数据。由于一个数据经纪商只能提供一个用户行为轨迹所需的很少数据元素,因此数据经纪商必须将其所掌握的数据汇集起来,描绘出用户生活更加复杂的多维图景。
联邦政府数据源。上述9家数据经纪商中的6家直接从联邦政府渠道获得其所需要的数据。
地方政府数据源。有些数据经纪商并非直接从地方政府获取其所需要的数据,而是通过其他数据经纪商获取其所需要的地方政府数据,后者往往通过雇佣人员对地方政府官员展开公关,以便获取对地方政府数据进行编纂和整理的机会;或者与地方政府具有业务往来关系,地方政府同意其在业务往来中自动收集、获取地方政府数据。
公共数据源(包括社交、博客、互联网等)。一半以上数据经纪商表示他们收集通信录、电话本、新闻报道等其他可用公共数据。
商业数据源。除1家数据经纪商外,其余9家数据经纪商都通过广泛的商业渠道来购买其所需要的用户个人数据。例如,数据经纪商从零售商、产品目录公司等渠道购买详细的商品交易信息,部分数据经纪商还从期刊发行商那里购买详细的用户订阅类型。
互为数据源。数据经纪商的绝大多数商业数据源实际上来自上述9家数据经纪商之外的其他数据经纪商。部分数据经纪商共享同一数据源,每一家数据经纪商都能从不同数据源收集到相同或相近的数据。
四、美国数据经纪商的产品类型
数据经纪商通常提供市场营销产品、风险控制产品和人员搜索产品等三类数据应用产品。2012年9家主要数据经纪商的三类主要数据产品全年总收入大约为4.26亿美元。
市场营销产品
有5家数据经纪商面向其客户销售自己的市场营销产品,2012年全年营业总收入大约为1.96亿美元。美国联邦贸易委员会(FTC)将数据经纪商的数据营销产品分为下列几类:
第一类是直销产品。包括邮件、电话营销、电子邮件营销等三类;
第二类是在线营销产品。包括通过互联网向用户进行营销(互联网营销)、通过移动设备向用户营销(移动营销)以及通过有线电视和卫星电视向用户营销(有线电视卫星电视营销)等三类;
第三类是营销分析。所有这三类产品都能使数据经纪商的客户面向其客户量身定制各类市场营销信息。
风险控制产品
接受调查的10家数据经纪商中有4家面向市场销售其自己开发的风险控制产品,2012年的年收入总额为1.77亿美元。美国联邦贸易委员会(FTC)将风险控制产品分为身份认证产品和欺诈侦测产品两类。
人员搜寻产品
上述9家数据经纪商中有3家面向市场销售其自己开发的人员搜寻产品,2012年的年收入总额为0.52亿美元。人员搜寻产品主要提供用户个人数据,这类产品能使用户基于最少的数据元素便能发现最多的用户相关信息。数据经纪商通常会提醒用户不要将上述个人数据用于《公平信用报告法案(FCRA) 》规定以外的其他目的,包括就业资格认定、信用评级、保险费评定、房屋买卖以及其他类似或相同目的。
五、美国数据经纪的产业特征
美国数据经纪商有如下产业特征:
数据经纪商通过多种信源广泛收集用户个人信息,绝大多数情况下用户对此并不知情。
数据经纪产业由多层互为提供数据的数据经纪商所组成。数据经纪商不仅为终端用户提供数据,同时也互相互为提供数据。
数据经纪商收集、存储着海量数据元素,几乎覆盖了每个美国用户。
数据经纪商联结并分析用户数据,以便做出包括潜在敏感推理在内的用户推理。数据经纪商从用户数据中推理用户兴趣,根据用户兴趣结合其他信息对用户进行分类。
数据经纪商将线上线下数据与市场用户的在线数据相结合。数据经纪商依托网站注册功能和浏览器 cookies 抓取跟踪功能来发现用户在线行为轨迹,推理用户离线行为特征并向其推送在线互联网广告。
六、美国数据经纪产业的利弊分析
用户能从数据经纪商收集、使用数据的众多目的中真正获益。数据经纪产品能够预防欺诈、增加产品销量、向用户推送量身定制的广告。
许多数据的收集和使用行为对用户造成一定程度的风险。如果用户因数据经纪商的错误而不能完成一项风险控制产品的交易,用户往往因不知情而使自己受损。
数据经纪商一定程度上会向用户提供其个人数据的选择权,但是这些选择权绝大多数情况下是不完整、不可兑现的。用户通常情况下不知在哪里去行使其选择权或者不知如何行使选择权。
储存用户数据永远都具有不可预知的安全风险。虽然存储数据对于实现未来商业目的是有益的,但是数据存储的安全风险可能要远远大于其商业利益。
七、对我国大数据交易的借鉴意义
参照美国数据经纪产业发展模式,以数据开放共享推动大数据交易资源建设,以交易和产品双足运行推动大数据交易时新发展,可能是我国未来大数据交易产业健康良性发展的可选之路。
一是大力推进公共数据开放共享。坚持政府数据以开放为原则、不开放为例外,坚持政府数据开放先行、公共数据开放跟进,推进落实公共数据开放共享,为数据交易产业提供不竭资源源泉,活跃、繁荣数据交易产业,做大作强数据交易产业量体。
二是夯实大数据交易基本功能。鼓励数据交易机构积极探索实践,推动大数据供需有效对接,搭建大数据讨价议价撮合机制,探索大数据交易交割模式,增强大数据流通变现能力,引导大数据资源以多种价值形态参与社会生产生活活动。
三是构建适用于大数据交易的云端集散中心。鼓励数据交易机构积极申办云存储中心、对象存储空间、可寻址存储空间、云数据多点共享协同中心、集聚式自助管理系统、中央存储平台等云交易系统,通过云平台实现数据集中,形成自主可控且能增值利用的大数据集散中心。逐步面向社会公众开放数据接口,引导第三方数据开发者和社会力量对数据进行社会化开发、汇聚和整合,推动大数据按照等价支付、有序流动的原则在云架构中进行自由流动,带动整个数据价值链的规模化发展。
四是与数据源保持同步更新数据。数据交易机构应当与数据源签署明确的数据更新协议,按照数据源数据升级时间表的频度,与数据源按日、按周、按月、按半年或按年同步升级数据。由于用户本人往往是最原始、最可靠的数据源,为了激发基于用户身份信息(PII)的用户端应用和服务的创新浪潮,用户应当被赋予明确的权利,以便其能够以可行、机器可读的方式接入用户个人数据,使得用户能够表达其政策诉求、使用偏好和缔约要求,推动用户和数据源签约公司共同参与大数据的治理和精用。
五是推动大数据交易和大数据应用连体融通发展。数据交易机构应当瞄准重要行业的重大应用需求,利用前沿性的大数据分析挖掘技术,实施大数据资源价值的深度分析和关联开发,探索富具市场特色、满足市场特需的数据创新应用模式,形成适用于重点行业大数据挖掘技术、分析流程、领域模型等关键应用和产品。
六是打造全国性的大数据交易产业链。数据交易机构应当以推动数据资源开放、流通、应用为宗旨,广泛聚集大数据提供方、数据开发者、大数据交互平台、大数据使用方及数据投资者,推广应用个性化医疗、数字金融、智能交通、精准营销等基于大数据的新型商业模式,在基础设施、数据资源、数据应用等关键环节形成产业合力,打造全国性的大数据流通、开发、应用产业链。
本文作者:佚名
来源:51CTO

![Pycharm一直卡在connecting to console的解决办法[图文步骤]](https://ucc.alicdn.com/pic/developer-ecology/66db32d988034c70b2dd545f72513595.jpg?x-oss-process=image/resize,h_160,m_lfit)