Q: 现在领域内对于分布式存储的应用场景是否有比较明确的分类?比如冷热,快慢,大文件小文件之类的?
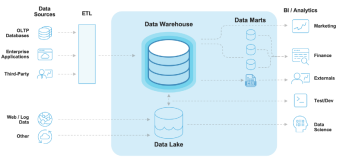
分布式存储的应用场景相对于其存储接口,现在流行分为三种:
1. 对象存储: 也就是通常意义的键值存储,其接口就是简单的GET,PUT,DEL和其他扩展,如七牛、又拍,Swift,S3、
2. 块存储: 这种接口通常以QEMU Driver或者Kernel Module的方式存在,这种接口需要实现Linux的Block Device的接口或者QEMU提供的Block Driver接口,如Sheepdog,AWS的EBS,青云的云硬盘和阿里云的盘古系统,还有Ceph的RBD(RBD是Ceph面向块存储的接口)
3. 文件存储: 通常意义是支持POSIX接口,它跟传统的文件系统如Ext4是一个类型的,但区别在于分布式存储提供了并行化的能力,如Ceph的 CephFS(CephFS是Ceph面向文件存储的接口),但是有时候又会把GFS,HDFS这种非POSIX接口的类文件存储接口归入此类。
按照这三种接口和其应用场景,很容易了解这三种类型的IO特点,括号里代表了它在非分布式情况下的对应:
1. 对象存储(键值数据库): 接口简单,一个对象我们可以看成一个文件,只能全写全读,通常以大文件为主,要求足够的IO带宽。
2. 块存储(硬盘): 它的IO特点与传统的硬盘是一致的,一个硬盘应该是能面向通用需求的,即能应付大文件读写,也能处理好小文件读写。但是硬盘的特点是容量大,热点明显。因此块存储主要可以应付热点问题。另外,块存储要求的延迟是最低的。
3. 文件存储(文件系统): 支持文件存储的接口的系统设计跟传统本地文件系统如Ext4这种的特点和难点是一致的,它比块存储具有更丰富的接口,需要考虑目录、文件属性等支持,实现一个支持并行化的文件存储应该是最困难的。但像HDFS、GFS这种自己定义标准的系统,可以通过根据实现来定义接口,会容易一点。
因此,这三种接口分别以非分布式情况下的键值数据库、硬盘和文件系统的IO特点来对应即可。至于冷热、快慢、大小文件而言更接近于业务。但是因为存储系统是通用化实现,通常来说,需要尽量满足各种需求,而接口定义已经一定意义上就砍去了一些需求,如对象存储会以冷存储更多,大文件为主。
Q: 实现思路方面是否又有一些通用的分类法?
实现上主要有两层区别:
1. 系统的分布式设计: 主从、还是全分布式或者是兼而有之,目前现在存储系统因为一致性的要求,以主从为主。
2. 底层的单机存储: 一种是依赖本地文件系统的接口,如GlusterFS,Swift,Sheepdog,Ceph。一种是依赖块接口的,目前只知道Nutanix是使用这个的(http://stevenpoitras.com/the-nutanix-bible)。最后一种是依赖键值接口的,目前应该只有Ceph是支持(Ceph支持多种单机存储接口)。第一种依赖文件系统是因为分布式存储系统本身已经够复杂,实现者很难从上层一直到底层存储都去实现,而本地文件系统已经是一个通用化并且非常成熟的实现,因此分布式存储系统绝大部分(上述提到的都应该是)都会直接依赖本地文件系统。第二种接口目前只知道Nutanix 是支持的(传统的存储厂商的存储产品一般会使用这种方式),这种接口也就是比第一种去掉了文件系统层,实现一个简单的物理块管理即可。第三种它的主要原因是“存储定义”和对象存储的普及,希望硬盘来提供简单的键值接口即可,如希捷的Kinetic API(https://github.com/Seagate/Kinetic-Preview),FusionIO的 NVMKV(https://github.com/opennvm/nvmkv),这种接口另一方面是闪存厂商非常喜爱的,因为闪存的物理特性使得它支持键值接口比快接口容易得多,目前Ceph是支持这种接口,而希捷和华为最近推出了IP硬盘(http://net.zdnet.com.cn /network_security_zone/2013/1024/2993465.shtml),听说已经实现了Swift上的原型。
(从这里可以发现,分布式存储系统是在传统的单机接口上重新包装了一层,然后实现三种类似的接口)
Q: 另外,对于不同的实现方案,分布式存储系统的性能是可以直接测试的,但理论可用性、数据可靠性的计算方式是不同的。UOS Cloud现在是Ceph方案,你们是怎么做这个计算的?
实际上这个计算是需要依赖于存储系统本身的,Ceph的优势是提供了一个叫CRush算法的实现,可以轻松根据需要来规划数据的副本数和高可用性。参考Ceph提供的模型定义(https://github.com/ceph/ceph-tools/blob/master/models /reliability/README.html)来规划自己的。这是我的同事朱荣泽做的故障计算。这个计算只针对副本策略,并不适合使用EC(擦除码)的情况。
硬盘发生故障的概率是符合泊松分布的。
| fit = failures in time = 1/MTTF ~= 1/MTBF = AFR/(24*365) 事件概率 Pn(λ,t) = (λt)n e-λt / n! |
我们对丢失数据是不能容忍的,所以只计算丢失数据的概率,不计算丢失每个object的概率。
| N代表OSD的个数 R代表副本数 S代表scatter width,关系着recovery时间 我们忽略Non-Recoverable Errors的概率 |
计算1年内任意R个OSD发生相关故障概率的方法是
| 1年内OSD故障的概率。 在recovery时(R-1)个OSD发生故障的概率。 以上概率相乘。假设结果是Pr |
因为任意R个OSD不一定属于Ceph的Copy Sets,则Ceph的丢失Copy Sets的概率是:
| M = Copy Sets Number 在N个OSD中,任意R个OSD的组合数是 C(R,N) 丢失Copy Sets的概率是 Pr * M / C(R, N)。 |
最终公式是:
P = func(N, R, S, AFR)
本文作者:佚名
来源:51CTO