常见问题及处理
- mysql版本,必须是MYSQL5.1。
查询办法mysqladmin version
在建立hive数据库的时候,最好是:create database hive;
oozie的数据库,同样:create database oozie;
hadoop采集的字符集问题。
修改/etc/sysconfig/i18n 更改字符集为en_US.UTF-8
重启机器生效。
重启机器的指令为:在root下敲入如下指令:sync;sync;init 6
修改mapreduce。
在gateway/性能下修改:MapReduce 子 Java 基础选项 、Map 任务 Java 选项库 、Reduce 任务 Java 选项库 全部配置成 -Xmx4294967296
在TASKTRACKER/性能下修改:MapReduce 子 Java 基础选项 、Map 任务 Java 选项库 、Reduce 任务 Java 选项库 全部配置成 -Xmx4294967296
必须关注各个任务的详细情况
当出现如下的错误的时候,请及时的将下载的进程数调小。
- vi /home/boco/oozie_wy/config/lte/mro/ftp/807101.xml 将max_thread由原来的6个调整为3个,或者协调厂家加大FTP的最大线程数。
- stderr logs:
- org.apache.commons.net.ftp.FTPConnectionClosedException: FTP response 421 received. Server closed connection.
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:363)
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:290)
- at org.apache.commons.net.ftp.FTP.connectAction(FTP.java:396)
- at org.apache.commons.net.ftp.FTPClient.connectAction(FTPClient.java:796)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:172)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:192)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:285)
- at com.boco.wangyou.utils.Ftp.connectServer(Ftp.java:550)
- at com.boco.wangyou.lte.mro.ftp.tools.FindFileThread.run(FindFileThread.java:67)
- 登录ftp服务器【10.140.177.149】失败,FTP服务器无法打开!
- org.apache.commons.net.ftp.FTPConnectionClosedException: FTP response 421 received. Server closed connection.
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:363)
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:290)
- at org.apache.commons.net.ftp.FTP.connectAction(FTP.java:396)
- at org.apache.commons.net.ftp.FTPClient.connectAction(FTPClient.java:796)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:172)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:192)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:285)
- at com.boco.wangyou.utils.Ftp.connectServer(Ftp.java:550)
- at com.boco.wangyou.lte.mro.ftp.tools.FindFileThread.run(FindFileThread.java:67)
- 登录ftp服务器【10.140.177.149】失败,FTP服务器无法打开!
- org.apache.commons.net.ftp.FTPConnectionClosedException: FTP response 421 received. Server closed connection.
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:363)
- at org.apache.commons.net.ftp.FTP.__getReply(FTP.java:290)
- at org.apache.commons.net.ftp.FTP.connectAction(FTP.java:396)
- at org.apache.commons.net.ftp.FTPClient.connectAction(FTPClient.java:796)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:172)
- at org.apache.commons.net.SocketClient.connect(SocketClient.java:192)
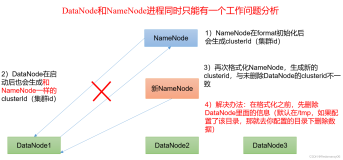
- TASKTRACKER和HDFS组的问题
发现部分地方在安装的时候,将所有的机器分组的问题。
如果分组,需要将每个组的参数都要修改。
目前发现很多的地方,TASKTRACKER和HDFS都分了组,但是只修改一组的参数,造成系统大量出问题。
java heap size以及tasktracker被拉黑名单的问题。
- namenode和datanode的内存配置问题。
建议将使用的内存修改为4G左右。
- 建议将HIVE2服务放到一个辅节点上。
hive2放到辅节点上,经常出现add_partation挂起报错。
- 解决HIVE经常挂死的问题
修改zookeeper的最大客户端连接数,maxClientCnxns修改为3600或者修改成0不限制
自动清空时间间隔,autopurge.purgeInterval 修改为1小时
- 厂家XML配置的问题。
如果厂家是这样的:/data/dataservice/mr/ltemro/huawei/20140815/01/362323/TD-LTE_MRO_HUAWEI_010133150144_362323_20140815011500.xml.gz
建议配置成这样的:
路径:/data/dataservice/mr/ltemro/huawei/$TIME$/$ENODEB$
时间格式:yymmdd/hh
- 在/home/boco/oozie_wy/config/lte/mro/ftp下禁止存放.bak文件
有一个省份的mapper数超多,导致解析很长时间没有完成。
进一步发现FTP在合并文件的时候报错,再进一步发现同一个IP地址,同一个OMC启动了三个mapper进程去下载数据导致文件合并失败。
发现是修改了ftp.xml文件,没有删除原来的文件,而是以一个bak文件存放。
删除这些bak文件,mapper数量正常。
原mapper数1731个,删除之后mapper数41个,采集正常。
打开50030看FTP的日志,存在如下的报错:
- java.io.FileNotFoundException: File does not exist: /user/boco/cache/wy/ltemro/1411032293348/xml/155/2014-09-18_11/TD-LTE_MRO_ERICSSON_OMC1_303024_20140918111500.xml.zip
- at org.apache.hadoop.hdfs.server.namenode.INodeFile.valueOf(INodeFile.java:39)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocationsUpdateTimes(FSNamesystem.java:1341)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocationsInt(FSNamesystem.java:1293)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocations(FSNamesystem.java:1269)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocations(FSNamesystem.java:1242)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getBlockLocations(NameNodeRpcServer.java:392)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getBlockLocations(ClientNamenodeProtocolServerSideTranslatorPB.java:172)
- at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java:44938)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:453)
- at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1002)
- at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1701)
- at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1697)
- at java.security.AccessController.doPrivileged(Native Method)
- 或者:
- org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException):
- Lease mismatch on /user/boco/cache/wy/ltemro/1411032293348/xml/155/2014-09-18_11/TD-LTE_MRO_ERICSSON_OMC1_3030_20140918.xml owned by DFSClient_NONMAPREDUCE_
- -1274827212_1 but is accessed by DFSClient_NONMAPREDUCE_-216613905_1
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2459)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2437)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.completeFileInternal(FSNamesystem.java:2503)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.completeFile(FSNamesystem.java:2480)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.complete(NameNodeRpcServer.java:535)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.complete(ClientNamenodeProtocolServerSideTranslatorPB.java:337)
- at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java:44958)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:453)
- at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1002)
- REDIS故障
解析时候报错,错误如下:
- redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
- at redis.clients.util.Pool.getResource(Pool.java:22)
- at com.boco.wangyou.utils.JedisUtils.getJedis(JedisUtils.java:47)
- at com.boco.wangyou.utils.JedisUtils.getTableValues(JedisUtils.java:119)
- at com.boco.wangyou.lte.mro.tdl.tools.LteMroXMLParser.
此问题一般是因为REDIS没有启动导致。
- 克隆机器安装的问题
把一个节点的第二步都装好了,把它克隆到其它主机上,再把克隆到的主机的IP
(注意在修改IP配置文件的时候,将HWaddr也改了,一般是这种格式:00:50:56:80:4E:D6,
否则在连接时会找不到硬盘)和主机名改下。
此种情况主要出现在使用vmvare vsphere克隆导致的。
注意:
克隆之后的机器要修改IP地址,主机名,MAC地址。
- redis挂死,导致无法采集
- #现象
redis.clients.jedis.exceptions.JedisDataException:
- MISCONF Redis is configured to save RDB snapshots,
- but is currently not able to persist on disk.
启动客户端:
- /usr/local/redis/redis-cli
输入:
- config set stop-writes-on-bgsave-error no
- 主节点7180无法访问
1)检查主节点是不是日志空间满了,如果满了,需要删除/var/log/hive下面日志
2)删除浏览器的cookie访问记录
hadoop相关服务启动命令:
- sudo service cloudera-scm-server stop
- sudo service cloudera-scm-server-db stop
- sudo service cloudera-scm-server start
- sudo service cloudera-scm-server-db start
- LTEMRO采集报错
主要是在这一步报错:CREATE_EXTERNAL_TABLE_NODE
有效的采样点数据,是如下的八个字段必须有值:
- MR.LteScEarfcn 主小区频点
- MR.LteScPci 主小区PCI
- MR.LteScRSRP 主小区的RSRP
- MR.LteScRSRQ 主小区RSRQ
- MR.LteNcEarfcn 邻小区频点
- MR.LteNcPci 邻小区PCI
- MR.LteNcRSRP 邻小区的RSRP
- MR.LteNcRSRQ 邻小区RSRQ
只要有有效数据,就不会报这个错。
- 查看日志
HIVE的日志主要是在:/var/log/hive/
oozie的日志主要在: /var/log/oozie/
HDFS的日志主要在: /var/log/hadoop-hdfs/
zookeeper的日志主要在:/var/log/zookeeper/
在出现问题的时候,可以看看这些日志。
- zookeeper无法启动。
处理办法:到master主机的/var/lib/zookeeper,删除所有的文件,重启zookeeper即可。
sudo mkdir version-2
sudo chown -R zookeeper:zookeeper version-2
- loudera-manager-installer.bin安装报错。
报错如下:
- Loaded plugins: aliases, changelog, downloadonly, fastestmirror, kabi, presto,
- : refresh-packagekit, security, tmprepo, verify, versionlock
- Loading support for CentOS kernel ABI
- Loading mirror speeds from cached hostfile
- http://10.233.9.63/cdh4.3.0/cdh4.3/repodata/repomd.xml: [Errno 14] PYCURL ERROR 22 - "The requested URL returned error: 403"
- Trying other mirror.
- Error: Cannot retrieve repository metadata (repomd.xml) for repository: cloudera-cdh4. Please verify its path and try again
处理办法:
删除集群中每一台机器上原有的repo文件,rm -rf /etc/yum.repos.d/*
然后修改cloudera-chd4.repo、cloudera-impala.repo和 cloudera-manager.repo文件,将文件中的地址换成主节点的地址。
将cloudera-chd4.repo、cloudera-impala.repo和 cloudera-manager.repo文件上传到集群中每一台机器的/etc/yum.repos.d/目录下。
本文作者:佚名
来源:51CTO