近日,苹果 Siri 团队在苹果机器学习期刊上连发三文《Improving Neural Network Acoustic Models by Cross-bandwidth and Cross-lingual Initialization》、《Inverse Text Normalization as a Labeling Problem》、《Deep Learning for Siri』s Voice: On-device Deep Mixture Density Networks for Hybrid Unit Selection Synthesis》,详实展现了苹果在语音助手 Siri 上的最新进展与成果。其中第一篇文章讨论了一项利用声学模型数据的迁移学习技术,它可以显著提升新语言版本 Siri 的精确度。机器之心随后将奉献上第二篇、第三篇博文,敬请读者期待。
用户希望 Siri 的语音识别功能保持稳定,不受语言、设备、声音环境或者通信信道带宽的影响。正如其他监督式机器学习任务一样,高精度的获取通常需要大量的标注数据。无论何时在 Siri 中部署新的语言,或者扩展 Siri 以支持不同的音频信道带宽,我们都面临着是否有足够数据来训练声学模型的挑战。本文中,我们讨论了使用声学模型数据的迁移学习技术,该技术已经投入使用。我们展示了,表征不仅可跨语言迁移,还可以跨音频信道带宽迁移。作为一个研究案例,我们专注于以新的 Siri 语言识别超过 8 kHz 蓝牙耳机的窄带音频。我们的技术有助于显著提升新语言版本 Siri 的精确度。
任何数量的域数据
即使你只有与训练域相关的有限数据,它也很有价值。绝大多数 Siri 的使用发生在宽带音频信道,只有很少一部分发生在窄带信道(比如,8KHz 蓝牙耳机)。然而,从绝对意义上讲,苹果的大量客户在窄带信道上使用 Siri。在新语言版本的 Siri 发布之前,我们可以搜集的窄带蓝牙音频的数量是有限的。尽管如此,我们的目标仍是在第一天就为客户提供最好的体验。
2014 年年中,Siri 启动了一个使用深度神经网络(DNN)的新语音识别引擎。该引擎首先引入到美式英语的 Siri 中,截至 2015 年年中,我们已经把该引擎扩展到 13 种语言。为了实现成功扩展,我们必须使用发布前可收集的有限数量的转录数据来解决建立高质量声学模型的问题。对于宽带音频情况是这样,例如通过 iPhone 麦克风收集宽带音频,而对于通过蓝牙耳机收集的窄带音频更是如此。
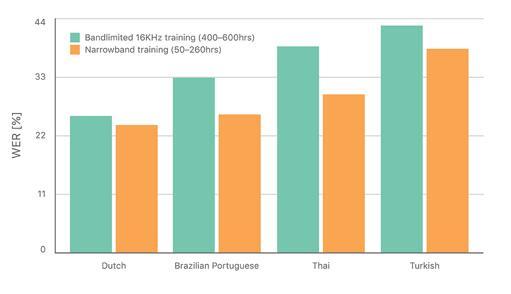
一个可以解决小数量窄带蓝牙音频问题的方法是带限(band-limit)相对较多、更易收集的宽带音频。实际上,我们发现在有限数量的窄带蓝牙音频上训练的声学模型依然优于在更大数量的带限宽带音频上训练的模型,这表明了声学模型训练中域内数据的价值(图 1)。这就要求同时利用大量的宽带音频和有限的窄带音频。在这项工作中,我们在迁移学习框架中调查了神经网络初始化 [1], [2]。
表 1 :窄带蓝牙测试中的词错率(WER)
跨语言初始化
很多研究者认为 [3] [4] [5] 神经网络声学模型的隐藏层可以跨语言共享。背后原理在于隐藏层学习的特征变换(feature transformation)不太指定具体语言,因此可以在多种语言之间泛化。
图 2. 跨语言初始化
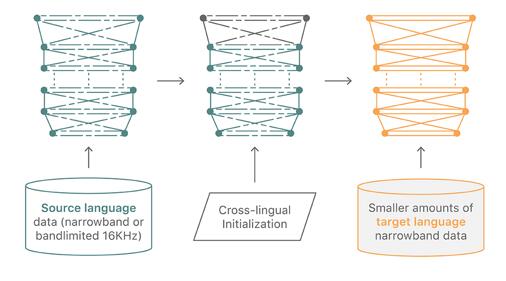
我们将训练好的现有语言窄带 DNN 模型的隐藏层迁移到新的目标语言,并使用目标语言数据重新训练该网络,如图 2 所示。
即使我们用不同的源 DNN 进行尝试,使用所有可用的窄带训练数据进行跨语言初始化训练的效果通常显著优于基线(详见 [6])。即使只有 20 个小时的窄带数据,对大多数语言来说,使用英语窄带模型开始跨语言训练优于使用更多窄带数据的基线。而当我们思考源语言和目标语言之间的语言关系时,我们无法得出结论。
跨带宽初始化
图 3. 跨带宽初始化
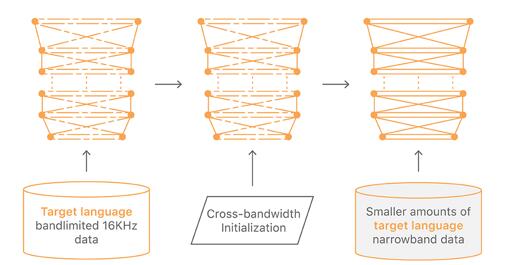
在最初的实验中,我们发现使用较少真实窄带蓝牙音频数据训练的模型优于使用较多带限宽带数据训练的模型。但是,在一种语言中使用带限数据训练的模型作为初始化的起点仍然是有用的。我们在真实窄带蓝牙音频数据上重新训练带限模型。用这种方式,我们能够使用一种语言的宽带和窄带数据来训练窄带模型(见图 3)。
跨语言和跨带宽迁移的结合
看到前两个迁移学习技术的成功之后,我们认为我们可以结合这两种技术,实现更进一步的发展。具体来说,我们在一个新的语言的带限宽带数据上训练 DNN 时,不需要使用随机权重开始,但是可以初始化在已支持的语言的带限数据上训练的 DNN 模型中的隐藏层。
图 4. 跨语言和跨带宽初始化的结合
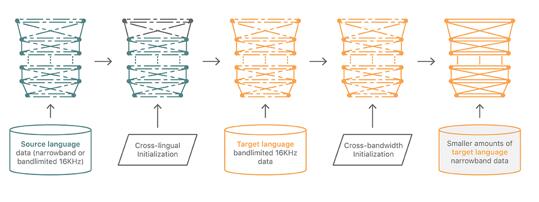
图 5. 跨语言和跨带宽初始化的词错率对比
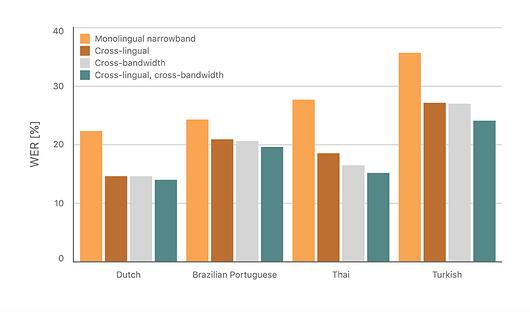
结论
我们利用从其他语音识别任务中获取的知识来改善窄带蓝牙应用的 DNN 声学模型。这类知识通常从 DNN 声学模型初始化中获取,具体来说,就是使用在带限宽带数据上预训练的 DNN 的权重,或者将其用于另一种语言。
对于我们实验中使用的全部语言,这些技术产生的词错率比只在目标语言的蓝牙窄带数据中单独训练的模型低 45%。我们的方法还可以灵活地在训练时间和从可用的多样化数据中学习之间进行权衡,详情见论文 [6]。
除本文论述的蓝牙窄带模型案例研究外,这些方法在很多神经网络声学模型场景中都显示出其高效性,并且帮助我们在 Siri 使用新语言和新音频信道时构建最佳模型。
