2017年8月23日的Greenplum技术研讨会,TalkingData架构师Max分享了该公司在Greenplum上的一些使用心得,分享给大家~~
一、TalkingData公司简介
一家提供手机端数据分析的厂家。
通过手机端SDK 嵌入,手机用户操作数据,进行分析。
主要产品:
AppAnalytic、GameAnalytic、Ad Tracking
营销云 - Smart Marketing Cloud
二、Data ATM
1. 系统简介:
Data ATM是第一部分所介绍产品的后台支撑平台,主要是用的架构是Greenplum,功能如下:
- 人群定位与分析平台
- 基于多个数据源的不同条件,找出特定人群
- 对特定人群进行分析画像
- 为前端数据应用提供数据支撑
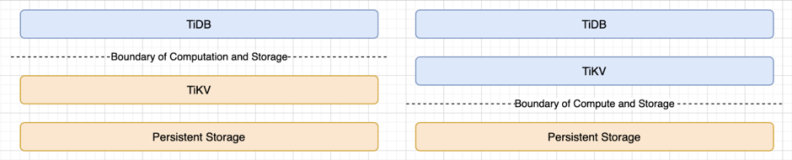
2. 业务架构
3. 流程图
4. 技术架构
业务架构通过任务执行器进行任务解析,根据不同的技术栈对应解析到不同的网关(Greenplum网关、Spark网关、ETL)。
任务解析器会将任务解析成SQL分配给Greenplum执行,目前平台95%的数据源分析工作都是交给Greenplum执行的;另外Spark的任务是通过API调用执行的;ETL的过程,也都是通过Spark实现的。ETLSpark和GP的冷数据落盘,都是落到HDFS中去。
作者提到,开始的时候,他们用的是纯Spark的架构,但是慢慢发现Spark并不能完全满足业务需求,开发难度较大,故切换到Greenplum。目前Lookalike模型在Spark上。
三、主要数据存储Greenplum
1. 数据容量
- 总数据容量400TB
- 15~20TB每天
- 唯一设备数55亿+
- 日活设备数2.5亿
- 月活设备数6.5亿
- 月位置数据(聚集后)600亿,3个月的位置数据量,2000亿
- 最大单个任务参与计算数据超过6TB
- 任务耗时1秒~5分钟
- 机器磁盘容量占用70%左右
2. 目前Greenplum规模
- 21个数据节点,1个Master,单台机器配置4个Primary Instance,4个Mirror Instance;
- 共计84个primary,84个mirror
- 单节点配置:
24Core CPU
128GB RAM
14*SAS 7200 Disk Raid 5 = 45TB(使用的应该是单块容量4T的盘)
- 目前存储数据量
400TB+纯文本数据存储在HDFS上,上载到本地磁盘的数据量大于400TB
3. Why Greenplum
- 得益于可控的数据分布,提高执行效率,相比于spark上面块分布的策略,GP可以提供根据ID值的均匀分布,计算效率更高
- 支持列式存储和压缩,方便对数据进行压缩,节约容量
- 支持多样的数据类型:Array XML Json等,加快查询,节约开发成本
- 支持GEO空间计算引擎PostGIS,不需要自己开发较复杂的空间计算函数
- 扩展性强,Function Operator DataType Aggregation Index都可以由用户来自由定义,为二次开发及扩展提供很大帮助
- 支持多种主流语言:PGSQL C Python Perl Java R,方便各类扩展
- 使用标准的SQL语言,降低前端开发成本和时间
三、技术点分享
1. Array& Json
- 通过使用数组缩减数据量,加快查询
- 部分数据使用了多维数组,官方对多维数组支持较差,可以通过UDF实现
- Greenplum5.0支持Json格式
举例:
2. PostGIS
- 支持所有的空间数据类型
- 支持复杂的空间和地理位置计算
- 数据库坐标变换
- 球体长度计算
- 三维几何类型
- 空间聚集函数
聚集点数据举例:
3. Bitmap
- 在Greenplum内实现了Bitmap相关计算功能,用C写的UDF,效率不错
- 基于RoaringBitmap算法,一个压缩算法,比较流行,在Spark和Hadoop上应用比较广泛
- 通过标准的SQL语句来执行计算,可以像操作普通SQL语句一样操作这些RoaringBitmap数据
- 10亿级别的位运算达到了毫秒级别
Bitmap示例:
使用Bitmap进行加速查询示例:
End~