![]()
在我们公司初创的时候,组齐了三人的团队就开始做产品研发。当时整条业务线的东西都需要我们自己写,要在短时间内把东西做出来,效率是非常关键的。
我们的产品模式本身其实是需要验证的。创业有很多不确定性,在上线之前没人能知道,我们的一个项目究竟能达到多大的规模,能做到什么样。所以这时技术的重要性就在于快速把东西做出来。
我们最终选择Java,一方面是因为我们团队已经有了一定的写Java的基础,从最开始的搭建到后来初具规模也能Hold住,基数很稳;另一方面是因为Java有很大的用户量,人才储备非常多,我们看中了它规模化的能力。
从某种意义上来说,Java的开发效率确实有些低。但是后来由于选型的原因,我们还是坚持使用了Java。
在“Java如何写得更方便易懂”这方面,Java一直在改进。之前的Java设计思想是模块之间要做到可扩展,崇尚配置和代码分离。
现在Java社区在向高效开发比较理智的方向去做,各种语言慢慢趋向一致。
Java 8
我们在使用Java 8之前都是用面向对象的方式去思考、去处置代码。
当时有人贴出了Java 8,用一个Lanbda可以从头写到尾,十几二十行的Lambda能做很多事情。
引入这个技术栈之后,我们发现只要控制住适用的范围,它就是一个非常好用的东西。
我觉得无论是做Web开发还是服务端开发,都有一个非常经典的场景。在Java里我们提倡分层,如果批量去做很容易写成下图中的代码。

这段代码的核心是Map,它要做的就是把两个对象进行转换,把一个List转换成另一个List。
StreamAPI不单有编程方式上的提升,还可以在内部自行去做并发处理。
大家不用Java有很多原因,比如运维觉得它很难部署,架构师则会考虑第三方API在二次反射的时候是否能读到Java。
其实Java是主流的Java,只要还活着的开源项目基本上都已经支持Java。
SpringBoot到目前为止已经非常成熟了,我们身边有很多最近才创业的朋友基本上用的都是这套技术栈。
它的特点是把Spring全家桶用一个看起来很简单美好的方式进行了整合,实际上它不是对Spring技术栈的重构,而是把Spring技术栈做了封装和组合。
现在的Spring全家桶更多了。针对Web开发,基本上可以完成全部的选型,并封装得很漂亮。
在2015年Spring Boot还没有那么火的时候,我们做了一个类似的整合工作,用到了Spring 4、Spring MVC。
Spring4目前已经相对成熟稳定。Spring的发展经历了一个变更过程,从最开始的XML,在当时也算轻量级;到2.5的时候有了注解,简化了很多事情;在Java 3的时候加入了Spring Config。

Spring4相对于Spring 3加了一些Java 8的支持。
Spring MVC

如图是MVC的一个例子。
我们为了解决ORM使用繁琐的问题,自己写了Daogen。这个工具兼具了灵活性和规范性,它可以统一代码规范,强制做命名,并在编译期自动生成XML。

我们当时引入Jade4j框架,借用前端基本在用的模版引擎,在前端用Js可以跑,后端用Java也能跑。
现在Java比较火的框架叫Thymeleaf,这个框架也很好。基于我们想用前端来写模版,所以当时还是选择了Jade4j。
在第一个版本上线之后,“从0到1”阶段完成,这时我们又将面临不一样的问题。
随着业务规模扩大,线上故障、可用性、质量不能忽略,团队也要扩张,并提出新的要求。要求主要是质量、可见性和可用性三个方面。
团队扩张
因为条件限制,我们的招聘工作进行艰难。退而求其次,我们会选择一些资质较好、主动性较强的应届生或一两年工作经验的员工做培养。
我们需要构建一个人才梯队,以“一个带两个”的工作模式,把团队组织成一个有梯队的团队。
我们是单代码仓库,当代码不断增加,前期又做了很多不清楚的模型或代码的时候,必须要去整理清楚。
我最大的经验就是重构不合理的业务模型,业务模型是最重要的。
Devops可以做线上的无缝发布,做版本的回滚重启。测试环境要高可用。
可用性-应用监控
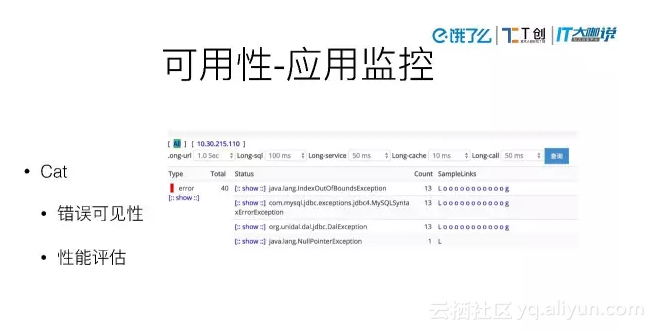
我们现在用Cat最多的是报错功能。Java的错误机制还是很完整的,如果出现什么线上问题,报错基本都能发现。我们主要做了两件事,一是把所有异常都发报警短信,另一件事是把所有异常放到一个电视机上,便于我们随时监控。
性能评估是其次,毕竟QPS只有1。
可见性-日志管理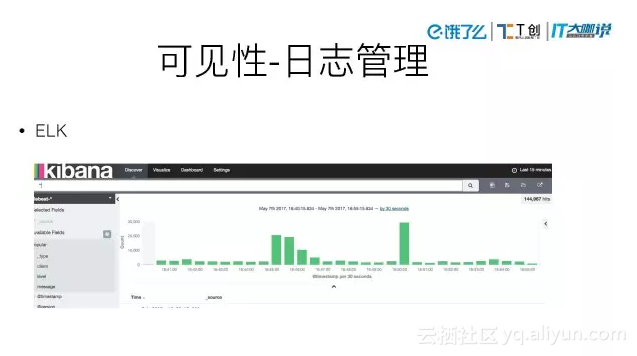
ELK可以用于做日志收集、业务监控、性能监控,甚至可以用来做数据分析。
但是因为它的数据量特别大,对服务器的性能调优要求比较高,所以我们最终只保留了日志管理功能。
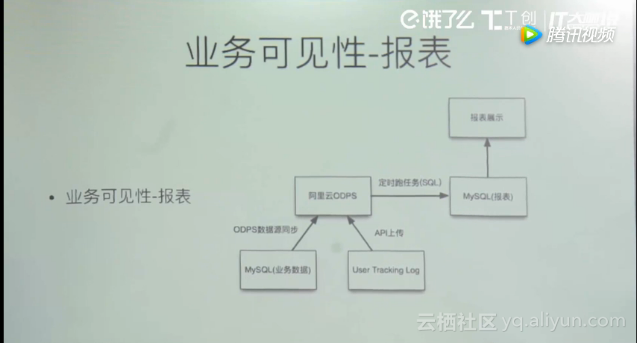
任何公司都有报表需求,我们的做法是跑个SQL把数据存下来然后给老板看。后期有些数据量较大,Mysql存储有压力,所以我们就用了阿里云的MaxCompute(原ODPS,https://www.aliyun.com/product/odps)。
吃自己的狗粮:在我们团队是真正做开发的人来选型,不是由老板决定。或许大公司的选型是“自上而下”,而我们团队是“自下而上”的,这一点更适合创业公司。
懒是一种美德:技术选型上我们选择更适合的,可能会提高开发效率或运营水平,但也可能不行。所以要去不断尝试,我们觉得这是值得的。我们为了追求更高的生产效率,也会写很多的小工具。
找到实用和好奇心的平衡点:到了整天做业务的阶段,会觉得枯燥。我觉得技术团队应该是有追求的,在满足“吃自己狗粮的条件下”尝试新技术。这个平衡点是根据团队规模和人员对某个方向的了解水平来定。
对利用第三方平台:我们团队能用别人的就尽量不自己做。用第三方服务多少会有些问题,但在衡量之下肯定会选择先把它做出来。
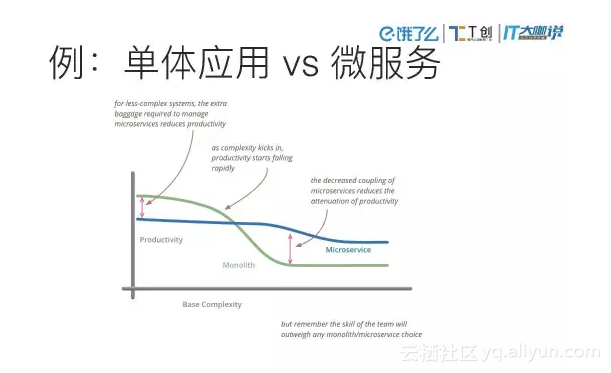
如图可见,在最初的时候单体应用的生产率更高,它有很多优点。
技术角色和创业公司的分工
技术在创业过程中相对来说还是比较确定的因素。当各部门之间出现分歧的时候,要提高效率只能选择相信队友,所以快速失措快速迭代是非常重要的,并且要进行有效支援。
发现当下的问题
要提高效率依靠更好的开发工具;
质量由QA人员和运维把关,进行异常监控;
可用性和安全也要通过监控来保障。
文章转载自IT大咖说公众号
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……