云栖TechDay36期,来自阿里云技术专家必嘫带来题为“打造云上深度学习实验室”的演讲。本文主要从深度学习流程开始谈起,解释了深度学习应用构建的完整生命周期,进而分享了机遇与容器服务的深度学习解决方案架构,接着讲解了端到端的深度学习体验,最后作了简要总结。以下是精彩内容整理:
深度学习流程
目前,人工智能已经进入了深度学习时代,
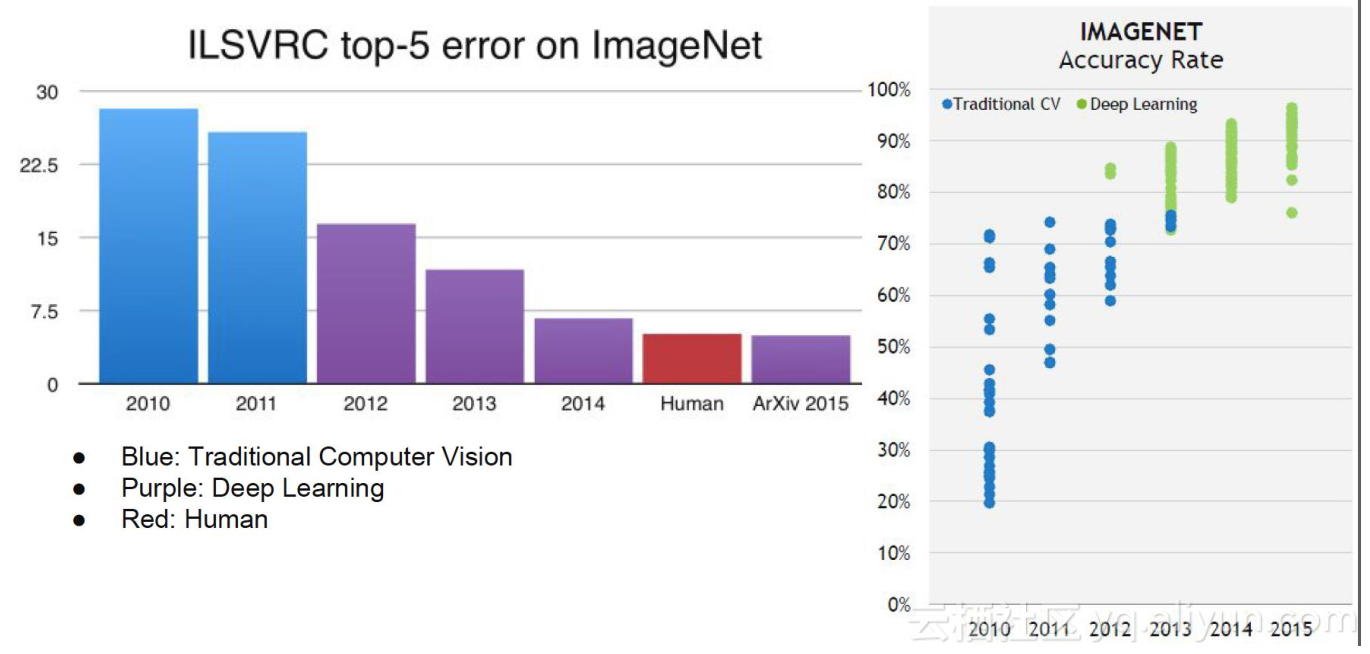
利用GPU加上深度学习理论,构建了一个模型,从2010年开始ImageNet所有技术都是基于传统机器视觉技术来做的,当时的识别率最好也差不多是在75%左右, 2012年达到了85%的准确率,基于深度学习的机器视觉能力上已经超越人类,机器识别的错误率是2.7%,而人的识别错误率是5.3%,这些技术基本上都是完全基于深入学习的技术往下做。从2012年开始,紫色的图都是基于深度学习。
深度学习有一些必要的因素,才有今天成功的效果。从AlphaGo身上,我们已经看到了机器的可怕,过去我们一直认为机器强大的是在于有强大的计算能力,但是深度学习能力使机器慢慢具备了强大的学习能力,而且这个学习能力是在某个领域可以深度加进的能力,也就是说它在某个固定的领域有一些足够多的数据让它去训练的话,它很有可能在某个领域成为技术专家并超越人,这其实对大家是一个非常大的警示,不懂深度学习的都在谈,因为大家确实开始感觉到了这项技术对我们是有影响的。

图为深度学习很常见的应用,这是俄罗斯开发的一款个人APP,这款APP能够把普通的照片加上一个大师的照片,相当于从你的照片中提取图片的内容,从大师图片的内容提取风格,最后合出来一张图,其实它用的是深度学习的技术。这个应用去年是IOS下载榜的冠军,打败了口袋精灵APP。
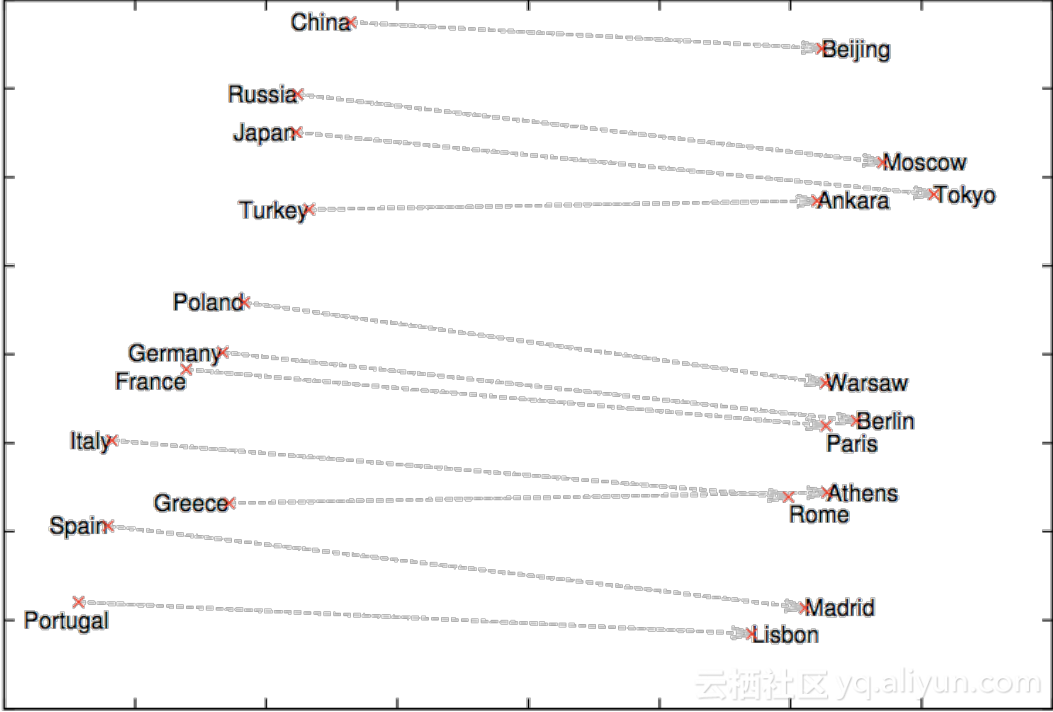
还有一个比较常见的应用就是语义分析,比如说看到中国能够联想到北京,这些都是深度学习广泛使用的一些场景。
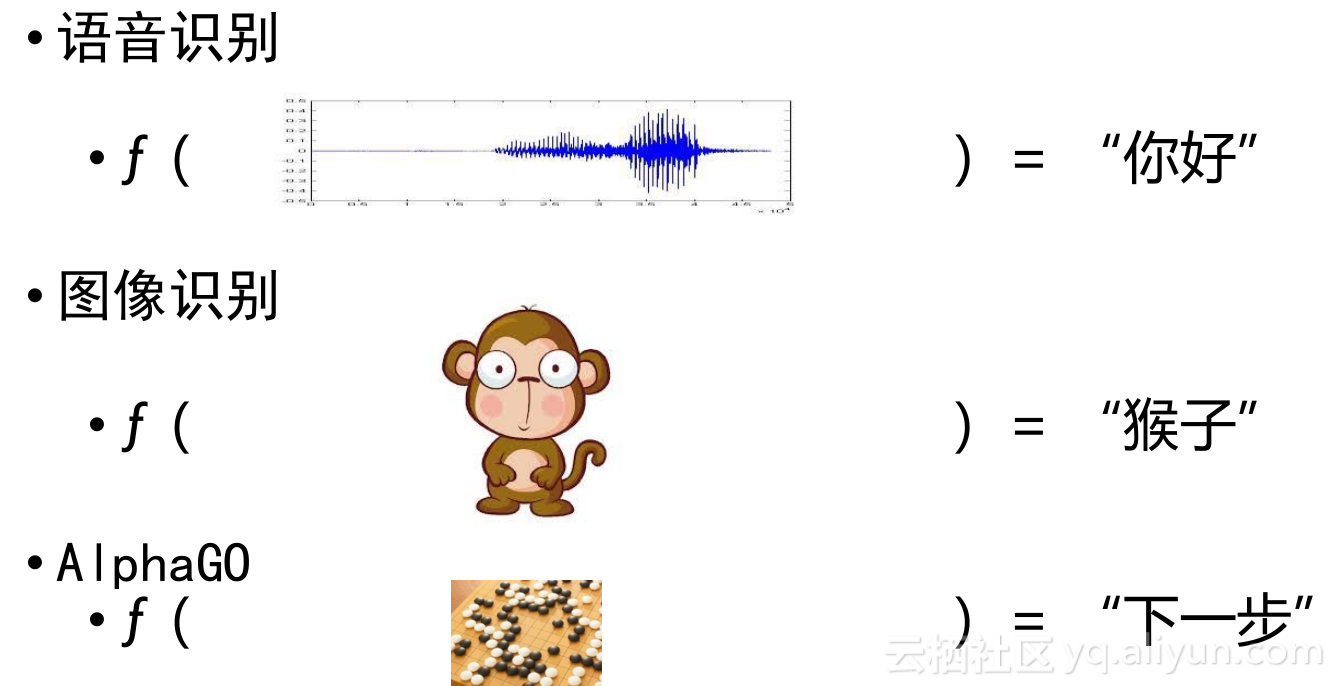
那么,深度学习到底是干什么的?我们给它一个定义,深度学习是在端到端的去寻找一个Y=F(X)的方程,或者是在做一个A到B的映射。具体来说,对于语音识别,我们传给你一段语音,你就能够翻译出,它能够知道是“你好”,然后在图象里面我画出来一个猴子,能够识别出来是猴子,AlphaGo下棋的时候,当我把棋局发给你,反馈就是下一步应该如何走,其实机器本身就在干这件事情,当人不知道怎么解决问题的时候,机器学习做一件事情,寻找一个方程能够反应这个规律。
那么,深度学习和机器学习的区别在哪里?在于端到端,传统机器学习不能直接把图片传给机器学习来处理的,它需要一些数据科学家,在阿里我们把算法工程师分成两类,一类叫基础算法工程师就是去开发F()里面东西的人,另外一类叫业务算法工程师,从最开始图片开始特征工程,所谓特征工程就是我来定义有哪些特征,什么是你的鼻子,什么是你的眼睛,然后先把图片转化成特征,把特征作为一个输入,输入到方程里面去求解。那么就意味着整个规律的提取实际上是由人来完成的,它对人是强行依赖的。而深度学习最不一样的地方在于从原数据开始,是由计算机本身来做特征提取,不是由人来做特征提取让机器去运算,这可以称的上是一个革命性的变化。这是深度学习的价值,你只需要在原数据中做计算,不需要做特征提取的事情,但是这也说明了它其实是有局限性的,深度学习其实是有自己的场景限制的,表现比较好的一些领域包括图象识别、语音识别、文字处理和下围棋等;还有对原数据的依赖性非常高,它必须要求原数据里面没有任何的特征丢失。
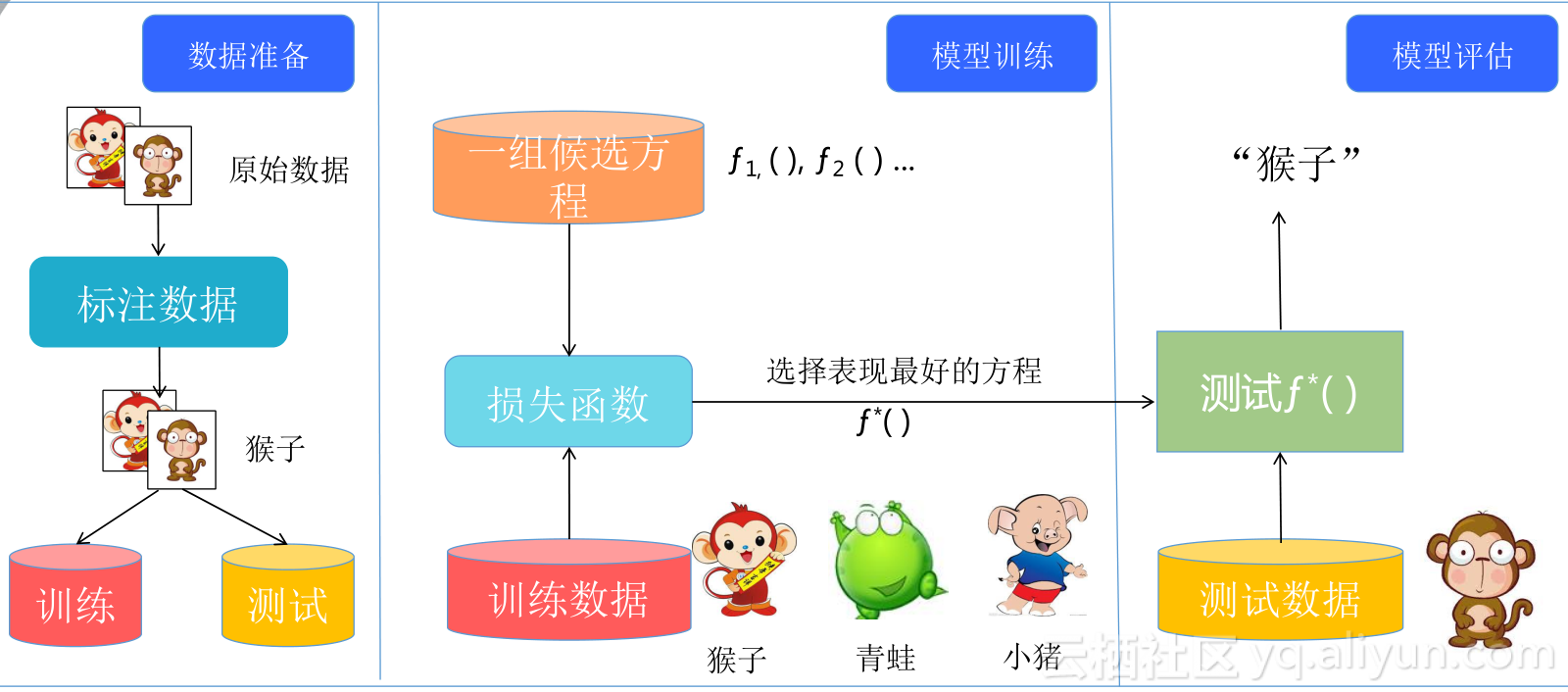
深度学习是直接从数据里面学规律,那么数据是很重要的事情。深度学习的真实应用比如语音识别和客服系统,这两个领域很成功。还有人脸识别,现在所有银行所用的人脸识别技术都是基于深度学习的。人工智能前面看到有多少智能,后面就有多少人工,它是完全数据驱动的,如果没有足够大的标注数据,深度学习是比较难开展的,所以要把数据标注出来,而这个东西耗时耗力,先要从网上拉图片,然后对这些图片进行标识。
标识完之后,要把数据分成训练集和测试集,提高它的泛化能力。
因为深度学习其实是寻找方程,那个方程会有很多的参数,会产生什么效果呢?会成为一个实验室的书呆子,我只能够把实验室的训练数据学的特别好,输入一个照片,可以给出正确的判断,但是当拿到真实的社会上去用的时候,我发现它是一个书呆子,看起来只是把那些数据的拟合程度做的比较好,但是它实际上叫过拟合,它只符合自己实验室的数据,没有真正学到规律。所以我们真实处理深度学习的时候,通常会做两件事情,数据标注好之后我会把数据分成两类,一类是训练数据,另外一类是测试数据,这是很重要的过程。后面做的事情就是把前面找到的一些后选方程输入进来进行比较,看哪个方程表现最好,表现最好的方式再做一个测试,当这个方程能够满足测试条件的时候,它就可以用来做商业化,用来做预测的方程。
深度学习是有门槛的,数据的能力、算法的能力和计算能力。过去只有数据科学家知道怎么解决的一些问题,而现在,特别像Google把TensorFlow库开放出来之后,对于普通的程序员来说,有许多东西你只要知道它能干什么,而它的使用实际上只是一个API的调用,这在深度学习方面有非常好的支持。
开源代码实现
另外一件事情,深度学习有机会把一些论文用代码实现,并且是可以下载找到并且学习的。所有成功的在做深度学习的公司,其实还是依赖于大数据来做。但是实际上包括Google、各个大学都已经把一些图象的库甚至一些视频的库放在了网上,如果大家肯去学习肯去看,这些库都是可以拿到的,重要的是你想要让深度学习帮你做什么,你要做一盘什么样的菜。
深度学习应用构建的完整生命周期
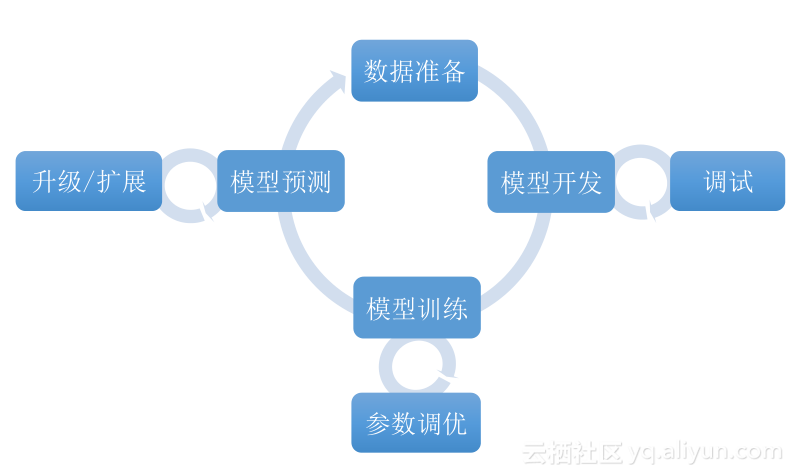
对于普通人来说,深度学习到底跟我们有没有关系?如果我想做成一个业务应用,你要做哪些事情?首先是数据准备,数据是深度学习的驱动力,然后里面有模型开发和模型训练,深度学习实际上在寻找一个方程,用这个方程去描述某些事情的规律,那么这个方程有两部分,这个方程长什么样,WX+B,后面加一个激活函数后面再加CNN,这个事情是由模型开发来决定的。我大概决定方程长成什么样,然后做模型训练,我只能知道模型长什么样,但是模型的参数实际上是训练在做的事情,把参数进行优化,当整个模型训练完成之后,就产生了一个模型。
那么,模型预测是干什么的呢?实际上就是把辛辛苦苦通过数据搜集、通过模型开发模型训练产生的模型进行商业化,它可以去做AlphaGo跟人下棋,可以做图象转化,实际上它有两种存在方式,一种是在线的存在方式,它作为一个API服务和整个微服务、其他外部服务进行整合,我从外部的API去调用,把这些输入放进去,返回一个值,这是一种方式;另外一种方式是手机APP,把它作为一个图书馆加上一个配置放在手机应用里面来做模型预测,当你的模型预测是为API所用的时候,这里面就涉及到升级扩展的问题。
为什么要用阿里云容器服务来跑我的GPU?阿里云容器服务助力深度学习敏捷化:
- 快速部署:无需安装,分钟级别启动/关闭;
- 多套环境共存:可以支持多个TensorFlow,Keras版本,不同python库;
- 可复现,可迁移并且可扩展:可复制可备份的环境,扩容简单,方便共享;
- 集成阿里云的分布式存储,负载均衡,云监控等服务,提供一站式的深度学习训练体验:ECS,EGS,NAS,OSS,SLB,SLS等服务无缝集成。
基于容器服务的深度学习解决方案架构
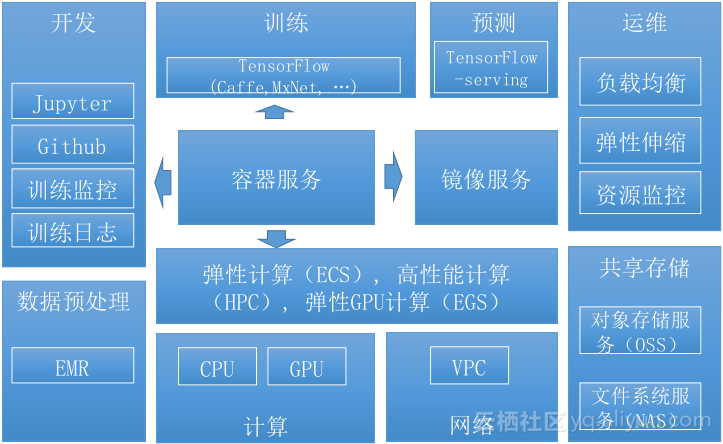
这是我们深度学习解决方案的一个整体架构,可以看到向上关联了它整个生命周期从数据的预处理,从开发训练到预测,包括EGS,我们支持GPU N卡,N卡是在深度学习场景下很重要的东西,包括VPC、共享存储,我们都已经集成了。向上管理整个生命周期,向下集成阿里云所有服务,你只需要使用我们的服务,就不需要管如何去用OSS,NAS的问题了。在运维的层面上,负载均衡、弹性伸缩包括你的资源监控都是在我们管理范围之内。同时我们也和EMR的集成。
利用容器技术进行GPU管理和调度
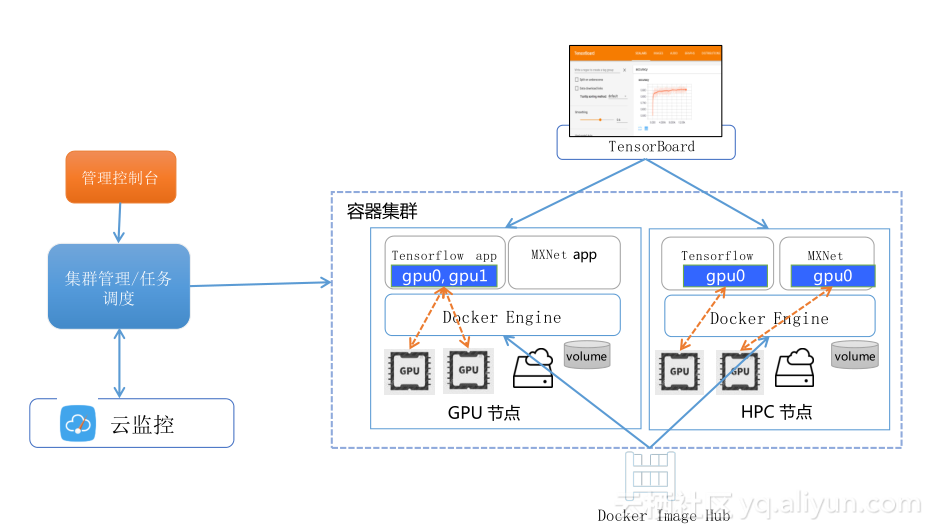
我们利用容器的技术进行GPU的调度,可以看到在控制台里面只需要告诉我,你的深度学习应用需要用几块GPU卡,如果是两卡,就把两卡都分割给你,如果是一卡,可以看到,在真正的主机上一个DVS要一个GPU0,一个DVS需要GPU1,写程序必须要指明用GPU0还是GPU1。利用容器化技术可以把你的应用和底层相屏蔽,做到应用里面是GPU0,虽然下面用的是GPU0和GPU1,但是在容器视角里面看,他们都是GPU0,这样使你的程序和底层相当于做到透明化管理。
另外,我们提供了docker镜像,我们提供的东西跟你的需求还是有差异的,你也可以用自定义的镜像来管理你的深度学习技术库。
端到端的深度学习体验

我们做的实验也是基于我们的解决方案,我们在模型开发、模型训练和模型预测三个最主要的场景下给大家一些支持。
模型开发支持很多学习框架,正确学习深度学习的话,是需要比较大数据量的,所以需要一些外接的数据券支持,包括OSS、NAS、HDFS,这个我们在模型开发上都做了支持,你可以选择要用GPU还是CPU;模型训练现在支持TensorFlow,我们支持TensorBoard的分布式训练,如果你的数据比较大,模型比较大,可以在我们这套框架下做分布式的训练。我们同时还有OSS、NAS和HDFS的支持等。我们也支持job的历史记录以及训练的时候要用到GPU和CPU;模型预测所做的事情是什么呢?我前面做的所有努力都是为了最后业务结果来付出的,最后的业务结果就是算出一个模型,把它做成一个服务暴露出去,存储现在支持OSS和NAS,也支持大实例和负载均衡。
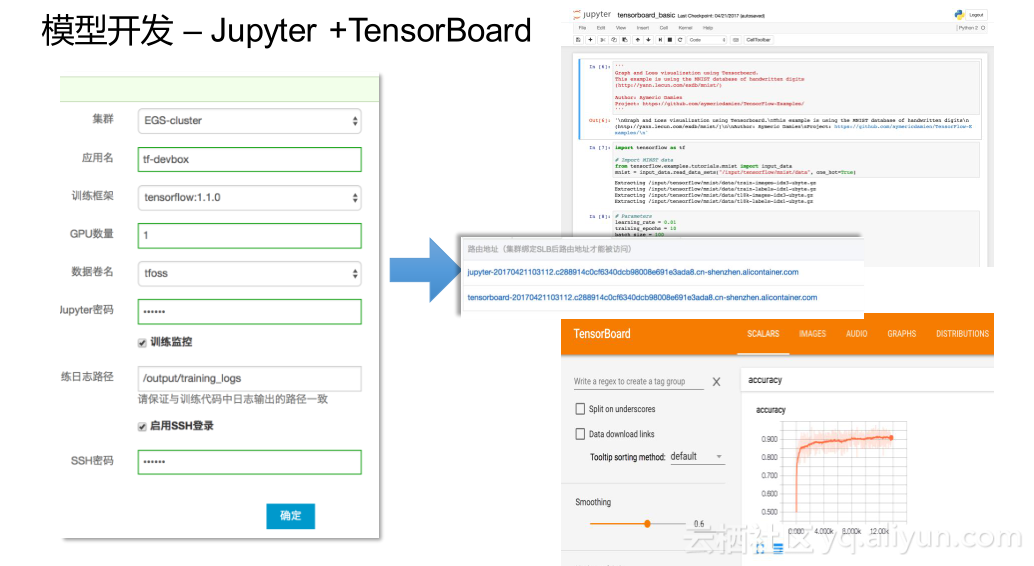
简单看一下,如果要做模型开发,怎么创建一套EGS的环境?首先要选一个集群,整个环境实际上都是你自己的,实际上对你来说完全安全的。然后选择开发环境的名字,然后选择训练框架,然后选择GPU的数量。可以选择使用数据券也可以选择不适用数据券。另外一个就是jupyter,相当于外部开发环境下面的密码,当你开发完之后,运行训练的时候,会有一个训练监控,就是我要看整个训练效果准确率等等。
下面就涉及到你是不是用SSH的方式去访问,当它被创建出来之后,可以看到有两个链接,一个是jupyter,一个是Tensorboard的访问连接,你可以通过这两个链接分别去访问两个不同的服务。
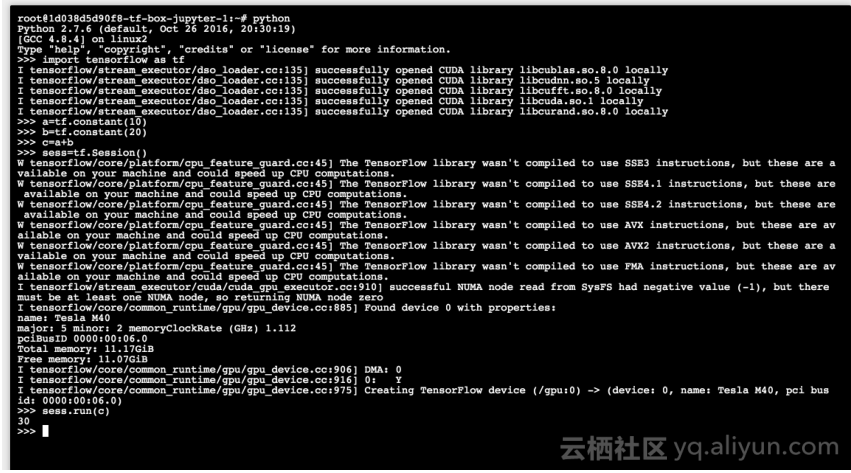
同样,模型开发我们提供了SSH的登录方式,这种方式对大多的程序员来说还是比较熟悉的。
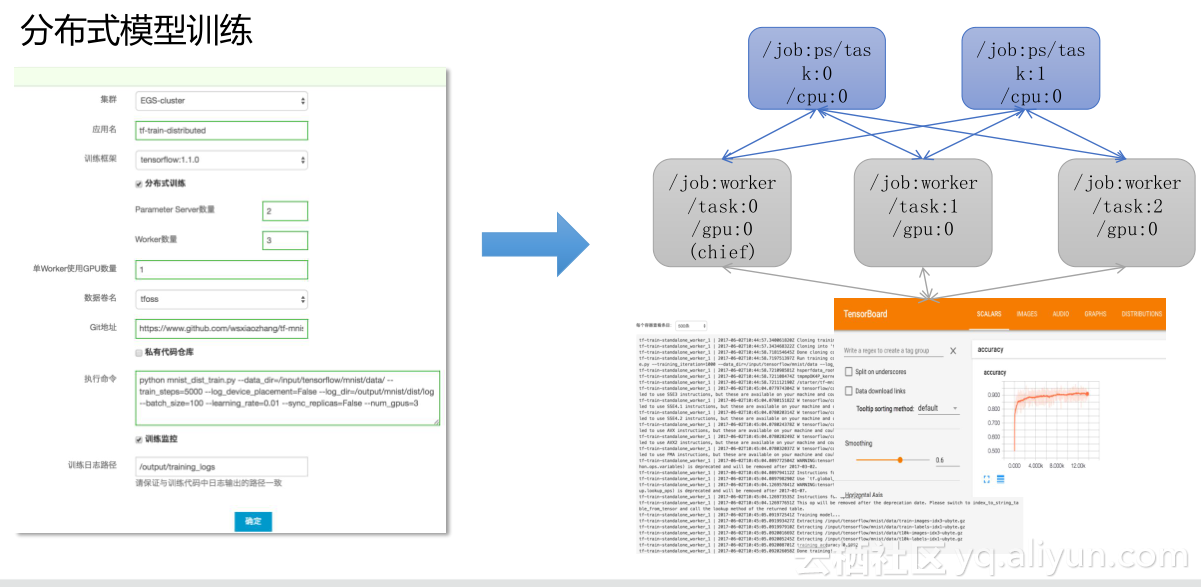
图为分布式模型训练,因为我们现在多数客户,除了一些比较先进客户在用这套东西,多数人还停留在模型开发,而模型训练的东西和模型开发有一点类似,但是最大的区别是有一个分布式训练选择。分布式训练我就可以选择去做参数服务器,然后做Worker, Worker是来做乘法操作的,所以要指定每个Worker要用几个GPU。数据券是把数据加载进来,如果你有比较大的数据量,另外我们有一个规约,相当于训练中间每隔1000步、2000步会产生一个中间的训练结果,把它记录下来,保存到某个地方,如果你的程序不幸挂掉,还可以自动恢复来进行运算,保证整个训练的时间没有因为意外而间隔。同样它也支持训练监控,一旦你把训练监控加长的话你就可以这里看到,每台Worker训练的效果是一个什么样子,包括日志。
分布式预测是用所谓的预测程序去加载模型,可以利用阿里云的负载均衡去做负载均衡的工作,用你的客户端来访问,相当于支持预测这个场景。除此之外,我们还提供了深度学习的一些基础服务,我们可以从HDFS上拿数据。
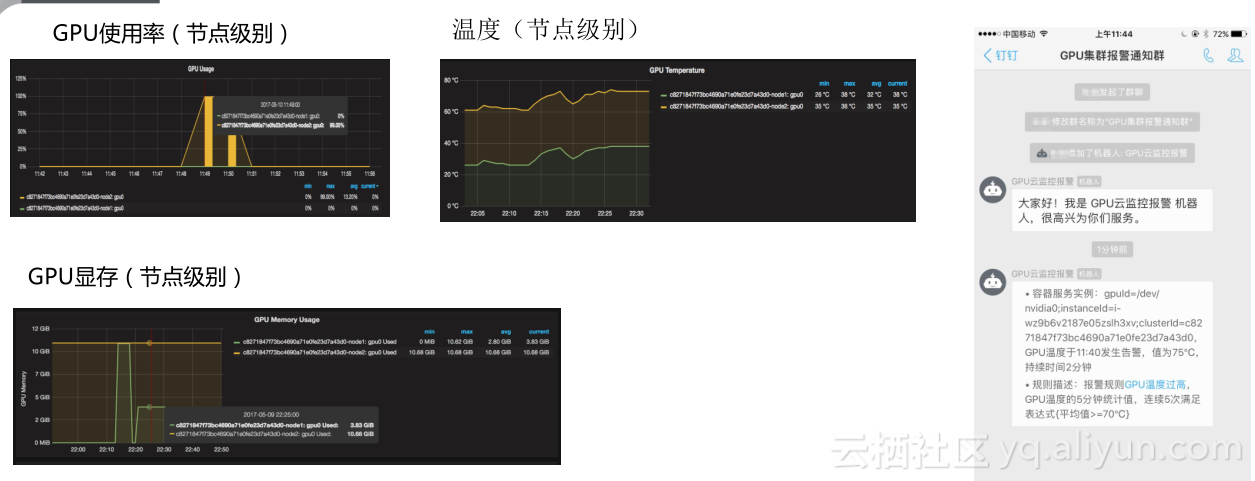
另外就是运维支撑,包括GPU的监控和报警,还有负载均衡以及根据监控和报警产生结果来做一些弹性伸缩的工作。大家可以看到,我们其实提供两个监控方式,一种监控方式是完全由你自己一个开源框架来做的,就是这套监控环境就布在你自己的机器上,阿里云不会拿到他的数据,另外一个方式是你可以把你的监控数据对接到你的监控上,我们监控能够给你提供一些像报警、自动恢复的能力,大家可以看到我们监控的维度,像GPU的使用率、GPU显存的使用率、GPU的温度。
云上深度学习的价值
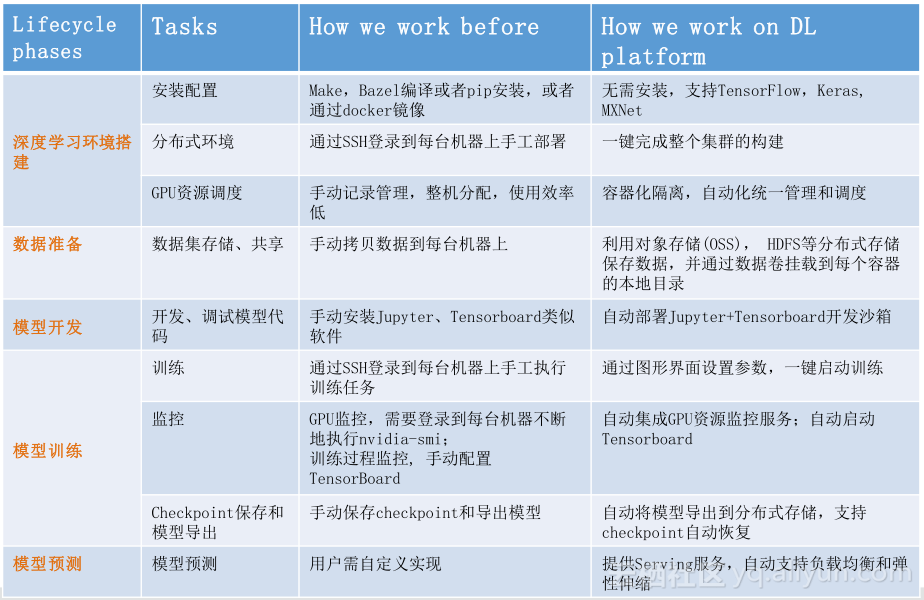
总结来看,大家经常说可以自己手操一套,自己买一个GPU机器,自己来搭一套环境是没问题的,实际上有一些隐性的成本可能要跟大家谈一谈。图中就是整个手工操作所必须的,包括这些深度学习库的版本维护,还有多版本的共存,以及它的监控和运维等,阿里云深度学习的方案给大家提供的就是一套基于深度学习的在线运维系统,帮助你把阿里云的经验放到云里面,帮助你更有效的训练出来你的深度训练模式。