背景
最近折腾的数据库同步项目中,大量使用了zookeeper(版本3.3.3),可以说是强依赖,但是最近频频出现zookeeper内存使用率达到100%,而且是GC不掉,直接导致整个系统挂起,伤不起阿
分析
因为大部分的情况都是无法GC回收,所以很大程度上怀疑出现memory leak。
设置了jvm参数,收集了一下OOM导致jvm crash之后的日志文件进行分析
1.-XX:+HeapDumpOnOutOfMemoryError leak分析:


从leak分析来看,比较明显,99%的内存都被Leader类的observingLearners给吃光了,所以重点就可以落在zookeeper observer的使用上了。
zookeeper的observer模式
官方说明: http://zookeeper.apache.org/doc/trunk/zookeeperObservers.html
主要用于解决读扩展性的问题,observer的节点不参与vote,也就是说写操作都只会发生在leader/follower中进行投票决策,而observer就是一个只读镜像。
但有一点和数据库的master/slave模式不同的是,observer也会接受写请求,但会将请求转交给leader/follower集群进行处理,并同步等待返回结果。
可以说observer比较巧妙的解决了读扩展性的问题,在zookeeper3.4.5版本,增加了readonlymode,和observer模式还是有所不同。
在我之前的文章中,zookeeper项目使用几点小结,有描述在项目中使用observer的情况:

从图中可以看出:
1. 整个zookeeper大集群有2部分组成,杭州的一个leader/follower集群 + 美国的一个observer集群
2. 为保证可用性,杭州集群的机器分别部署在3个机房中,(满足任意机房AB, 机房A+机房B > 机房A+机房B+机房C/2),最小的部署结构为3+2+2机器,这样可以确保,任何一个机房挂了,都可以保证整个zookeeper集群的可用性
代码分析:
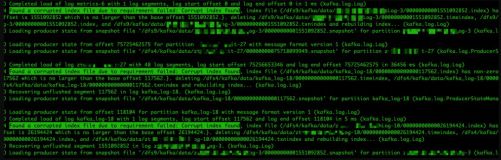
有了以上的背景分析,再回到memory leak问题上来,翻了下zookeeper issue,发现还真有提交对应的memory leak问题,https://issues.apache.org/jira/browse/ZOOKEEPER-1303
看完issue后,这时候问题已经明显了。
在Leader.java类中:
1./**
2. * Remove the learner from the learner list
3. *
4. * @param peer
5. */
6. void removeLearnerHandler(LearnerHandler peer) {
7. synchronized (forwardingFollowers) {
8. forwardingFollowers.remove(peer);
9. }
10. synchronized (learners) {
11. learners.remove(peer);
12. }
13. } 这里面Leader节点,在与对应的follower/observer之间的链接异常断开时,会清理当前内存中的引用句柄 (不然下次的vote信息还会发送到挂了的节点上)。
而leader在往observer上推送write数据,会遍历当前内存中的observingLearners列表
1./**
2. * send a packet to all observers
3. */
4. void sendObserverPacket(QuorumPacket qp) {
5. synchronized(observingLearners) {
6. for (LearnerHandler f : observingLearners) {
7. f.queuePacket(qp);
8. }
9. }
10. }
再看一下LearnerHandler.java类中:
1.public class LearnerHandler extends Thread {
2.
3.public void run() {
4. p = queuedPackets.poll();
5. ........
6.}
7.void queuePacket(QuorumPacket p) {
8. queuedPackets.add(p);
9. }
10.
11.}
LearnerHandler中的处理方式是一种典型的异步处理,通过queuedPackets接受任务数据,然后线程异步进行消费处理。 因为observer可能因为网络抖动,会断开与Leader之间的链接,就会触发shutdown方法。而shutdown方法就是尝试将自己从Leader的observer句柄中移除
所以整个问题原因已经比较明确,removeLearnerHandler没有清理observer队列中的句柄,导致一直进行queuePacket调用,又没有异步线程进行消费,所以暴内存是迟早的事。
总结
特别注意:3.3.6中居然没修复这个问题,所以可升级zookeeper至3.4.5, 经过实际验证大家可放心升级(我的client 3.3.6 , server 3.4.5)
zookeeper 3.4和3.3的兼容性描述: http://blog.cloudera.com/blog/2011/11/apache-zookeeper-3-4-0-has-been-released/