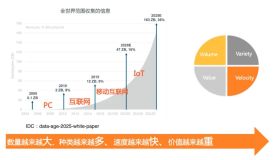
近年来,移动互联网、物联网、云计算的快速发展催生并积累了大量的用户、业务数据。据市场调研机构IDC预计,未来全球数据总量年增长率将维持在50%左右,到2020年,全球数据总量将达到40ZB。据统计,这些海量数据中只有10%~15%的数据是被经常访问的,而绝大部分都会在产生之后逐渐变冷。这些“冷数据”的访问率虽然很低,但用户还是希望保留这些数据,对于企业而言,还有很多数据需要进行备份和存档。
且不管数据的冷热及其冗余备份,如果将这40ZB的数据都使用目前已量产的最大容量蓝光盘来存储,按照单盘容量300GB计算,则需要1300多亿张盘;如果使用10TB的机械硬盘来存储,需要40亿个硬盘;如果采用磁带库来存储,目前也有量产的10TB磁带,按照这个存储能力计算,也需要40亿个磁带。这不仅为数据存储行业带来了巨大的市场空间,同时也对海量数据的存储、处理和管理能力提出了前所未有的挑战。
海量冷数据存储面临诸多挑战
首先,面对快速增长的数据存储需求,成本是需研究的首要问题。如果只从物理上增加存储容量,则必然导致存储数据的成本持续、快速增加,且将受制于机房空间、供电能力等其他因素而难以为继。
其次,是冷热数据的分级。业界根据数据的访问频次将数据分为热数据、温数据和冷数据,但具体到海量的数据,哪些属于冷数据,应该相应采用什么存储策略、存储方式,则是一个需要长期研究探索、实践积累的问题。
再者,海量的已存数据的维护也成为新的挑战。一方面需要定期检测存储介质的健康情况及数据的完整性,在发现坏盘的情况下及时进行更换;另一方面是数据的搬迁,存储介质大都有相对固定的使用寿命,在设备生命周期结束之后,需要将数据迁移到新的存储介质上。
海量数据的价值体现是又一挑战。海量数据的存储必然占用一定的成本,而数据的存储价值并非只是为了保存,而是在需要的时候能够被尽可能快地找到。为用户提供尽可能好的访问体验,这就要求海量数据存储具备可快速查询的能力。
最后,数据的安全也是海量冷数据存储的一大挑战。一方面是数据的可靠性,即数据的冗余备份。数据的存储最基本的要求就是数据不丢失,目前最常用的办法就是对数据进行多副本的冗余保存,或者采用可恢复数据的校验方法。这种冗余存储在本来就海量的基础上又增加了一定比例的数据量,而海量数据的存储通常需要大量的存储设备和其他配套设备,在相同的故障概率下,可能发生故障的设备也就相应较多,因此这些设备的定期巡检、故障定位和维修更换,都因“海量”而极具挑战。另一方面是数据的隐私保护,即数据的访问权限控制。由于大量的数据被聚集在一起,当发生数据泄露时,泄露的数据将会更多,甚至可能包括比攻击目标更加重要的数据。此外,海量的数据也增加了数据被篡改的风险,影响数据的实际价值。
为了实现用尽可能低的成本获得尽可能持久、敏捷、可靠、安全的数据存储,海量冷数据的存储面临着诸多挑战,同时也给产业链上下游企业带来了更多的发展机遇,从存储介质、控制器、数据中心等硬件技术,到数据分级、数据压缩、冗余备份等软件技术,相关企业都在进行相应的技术攻关,也取得了很多突破性的发展。
海量冷数据存储的关键技术
一是数据的分级,主要是指从海量的数据中根据文件的访问频率、价值等因素,进行冷热数据的分类,甚至分出更细的数据类型,如“温数据”、“冰数据”等。目前常见的数据分级方法主要有两类,一类是业务数据的分类,即基于具体的业务类型,结合长期以来的运营经验,进行运营级的数据分类。另一类是基于数据存取特性的分类,即借助存储软件系统自动进行数据的冷热分级。通过存储软件系统对数据进行冷热监控,统计分析一个时间周期内的IO冷热程度,并按照设定的分类策略自动进行数据的分类,并将冷数据从前端业务存储系统迁移到冷数据存储系统。
二是存储密度的提升,几乎所有的存储部件厂商都在努力通过提升单盘的存储容量来应对数据的快速增长。在磁、光存储密度快速提升的同时,电存储也表现出色,32TB的SSD盘已经问世,且预计未来还有更大的增长空间。
三是数据的压缩去重,提高有效数据的存储比例。为了提升数据存储的可靠性,通常会对数据进行多副本存储,但多副本的方式会带来存储数据量的倍增。为了进一步提升存储效率,在一些读写性能要求较低的场景下,可以选择只保存校验数据。
四是运营能力的提升,海量数据的存储需要更智能化的运维系统,包括对数据的定期巡检、数据的精细化分类、自动化的数据迁移、故障预测及定位、设备的休眠等机房节能措施。此外,存储的架构设计也是当前的研究热点,包括设备的分级、存储介质的选型、数据存储格式、数据检索、对外服务接口等。
此外,数据访问延迟、整体读取速率以及数据持久性等,也是海量冷数据存储的关键技术。这些关键技术相互制约影响,尤其是在运营能力提升方面,涉及的因素众多,对冷数据存储的选型提出了新的挑战。
海量冷数据存储选型策略
国内外大型互联网企业已根据自身的业务特点,结合多年的运营经验和业务预测,进行存储架构的整体设计,并基于其在冷存储方面的经验和技术积累,对外提供了相关的冷数据存储服务。以亚马逊网络服务推出的“AWS冰川”数据存储服务为例,用户可以采用它来存储无限量的数据,并建立存储库列表进行管理,包括各种档案的生命周期管理和访问策略。此外,还有谷歌公司提供的“近线云存储”服务,以及微软公司提供的“CoolBlob”存储产品,都是具有一定代表性的海量冷数据存储服务,而它们都有一个共同的特点就是“无限量”。
对于数据量较小且在快速增长的企业而言,可以选择使用一部分的云存储服务,同时也逐步探索建设自己的数据存储中心。
海量冷数据存储的关键还在于运营,在于存储策略和业务需求的匹配程度,因此,还需积极参与各种社区、联盟组织活动,借助产业发展的力量,更多地借鉴先行者的经验,了解行业的技术发展情况,及时更新制定适合自身需求的存储架构和技术路线。
本文转自d1net(转载)