文章引用:【http://www.biaodianfu.com/piwik-database-schema.html】
Piwik是一套基于Php+MySQL技术构建,能够与Google Analytics相媲美的开源网站访问统计系统,前身是phpMyVisites。Piwik可以给你详细的统计信息,比如网页浏览人数, 访问最多的页面, 搜索引擎关键词等等,并且采用了大量的AJAX/Flash技术,使得在操作上更加便易。此外,它还采用了插件扩展及开放API架构,可以让开发人员根据自已的实际需求创建更多的功能。
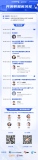
Piwik的数据库结构图

上图(点击可查看大图)Piwik的数据库结构按照简洁、效率和模块化进行设计。其数据库包含以下部分
- Statistics logger(统计记录)
- Users & Permissions(用户和权限)
- Site(网站)
- Archived data(存档数据)
- Debug / Info log(调试/信息记录)
- SQL query profiling(SQL查询分析)
Statistics logger
统计记录部分包含统计到的用户访问日志,这些数据一些来自于Javascript的标记,一些包逊于Cookie,一些有PHP获取。每个单独的访问者在Cookie中标记了一个唯一的visitor_idcookie。在数据库表log_visit中记录了用户的每一次“visit”。例如一个访问者在一天内访问网站两次(中间相隔30分钟),log_visit中就会有两条该用户的记录。
在一次访问中,一个访问者至少会浏览一个页面,我们称每浏览一个页面为一个“action”,每个action都会被定义一个名称(”homepage”, “/blog/hello-world”)和类型(一个定义行为种类的整数)。所有的单独“action”都被储存在表log_action中。
每个用户新的action都被记录到表log_link_visit_action中,其中包含了idaction和idvisit。同时这个表还包含idaction_ref 和time_spent_ref_action 字段,用来记录用户的上一次action。当我们请求第二个页面,程序将从cookie中读取上一个页面的idaction ,并作为action_ref保存,并记录中间的时间time_spent_ref_action.使用这个技术是因为我们不需要去更新上一条记录的时间:我们只需要记录当前上层页面的信息。
Users & Permissions
一个用户被定义为login, password, email 和一个用于请求API的token_auth。对于一个网站一个用户会有不同的access级别(浏览、管理、没有权限或是超级管理员。
Site
一个网站被定义为idsite和 main_url,main_url 是用来指向 site_url,所以它可以有很多的url。
Archived data
存档在piwik中是一段时间的数据聚合。它是由日志处理后得到的有具体含义的数据。
archive_* 表中的每行数据包含一个网站给定的日期/时间段的数据。例如,提条记录idsite = 3的这个网站在2008年2月7日的这周访问网站用户的国家列表。
Piwik的存档中总共有两种不同的数据类型的表:float和blob
- archive_numeric_* 表是用来储存数值的。改字段值value使用的是FLOAT类型,即他可以保存整型和浮点数。比如储存给定时间点网站的访问者数。
- archive_blob_* 表用来储存出数字以外的其他任何数据。BLOB是二进制数据类型,可以用来任何数据,比如字符串、字符串转化的序列数组、序列化的对象等。例如用来储存用户在一定时间段内所有的关键词。
事实上两个表都有相同的结构,除了value 字段的类型不同。他们同时包含以下字段:
- idarchive 用来定义单独的存档。对于一个特殊的网站在一个特殊的时期内(特定的日期)会是相同的idarchive. 换句话说如果(idsite,period,date1,date2)相同,则idarchive 相同且为主键。
- name 是用来记录值value 的描述。例如你想储存不同关键词的数量,比较恰当的name 可以是’Referers_distinctKeywords’
- idsite 是记录所属的网站
- date1 和 date2 使记录的起始日期和结束日期,如果记录的是一天的数据则date1 = date2.
- period 用来定义周期的类型有: day / week / month / year.
- ts_archived 是存档创建的时间戳。这个对确认存档是否还是有效很很大的帮助。比如今天的存档将会有效1小时或1分钟,这个取决于cache lifetime value的值。
- value 包含name描述的数据
存档表里的每条记录都是由存档处理类进行自动处理的,其中存档处理有多个类:记录管理的是Piwik_ArchiveProcessing_Record_Manager,数值记录的Piwik_ArchiveProcessing_Record_Numeric,
blob记录的是Piwik_ArchiveProcessing_Record_Blob和字符串blob记录的Piwik_ArchiveProcessing_Record_Blob_Array。
存档的逻辑可以在Piwik_ArchiveProcessing类中找到,按日存档可以从Piwik_ArchiveProcessing_Day类中找到,按时间点的存档可以从Piwik_ArchiveProcessing_Period类中找到。需要注意的是大多数实时处理的存档都是通过插件来执行特殊的事件。
加载存档(或加载处理中的存档)是使用Piwik_Archive类完成的。
从性能上考虑,表按月划分。这就意味着每个月新标就会创建,所以数据会被有规律的划分。如果值使用一张表来储存所有数据,它将变的非常的巨大且查询起来非常的缓慢。数据表划分由Piwik_TablePartitioning类进行处理,按月划分的由Piwik_TablePartitioning_Monthly类完成。
我们使用不同的表结构(FLOAT 和 BLOB),因为它可以非常快速的查询整型/浮点数值。SQL查询会因为数据表非常的轻量(light)而非常的快(并且archive_numeric_* 的每行有固定的长度)。比如我们可以快速的查询最近30天的访客数。
Debug / Info log
表logger_error, logger_message, logger_api_call 和 logger_exception 是用来记录各种各样信息的。
- logger_error 是用来记录错误信息。message 中包含line, php file errfile, backtrace。等。
- logger_message 是用来记录所有的调试和系统信息的。
- logger_api_call 是用来记录所有的API请求的。他会记录所有的请求参数(parameter_values)和返回的值(returned_value)、执行时间(execution_time)和请求地址的IP地址(caller_ip)等。这个信息又来使API请求更加的具体,当返回的值(returned_value)不正确的时候用于调试,监测API接口 的使用情况等。
- logger_exception 是用来记录所有的异常的。
而整体的逻辑控制是由Piwik_Log来完成的。
SQL query profiling
表log_profiling是用来储存SQL查询的概要信息的。
其他
注意:所有的时间戳都是由PHP生成的,而不是使用Mysql自带的NOW(), CURRENT_DATE()等函数。这是用来确保系统使用不同时间的服务器上的MySQL正常的运行。程序不是基于MySQL服务器的时间的。
未来的改进与优化
整个系统目前还存在很多性能改进的空间。比如,我们可以从以下几个方面进行改进。
- 按日期划分log_* 表(和archive_* 采用相同的处理方式)
- 审核大数据量下存档数据的SQL查询。
- 审核所有的索引策略。
- 为了避免大量的jions连接(log_visit, log_link_visit_action),我们可以通过复制(idsite, visit_server_date)字段使数据表非规范化。
如需了解更多的Piwik的原理和逻辑,请持续关注标点符。