更多深度文章,请关注:https://yq.aliyun.com/cloud
预测肺癌
Data Science Bowl是由Kaggle主办的年度数据科学比赛,今年的参赛题目是根据一年内诊断为癌症的人的胸部CT图像来进行预测肺癌。竞赛平台可以在此查看。
为了完成此次挑战,由来自根特大学的博士生和博士后们Andreas Verleysen,Elias Vansteenkiste,FrédericGodin,Ira Korshunova,Jonas Degrave,Lionel Pigou和Matthias Freiberger组成机器学习团队Deep Breath,没有任何一个成员具有关于医学图像分析或癌症预测方面的具体知识。比赛结束后,Deep Breath团队取得了第9名的成绩!在这篇文章中将说明该团队采用的方法。
介绍
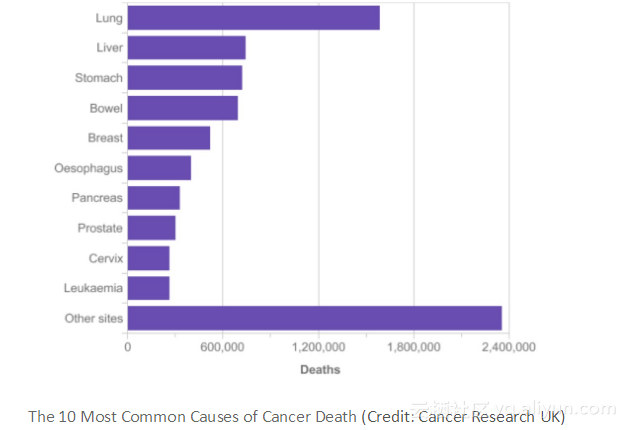
从图中可以看到肺癌是全球癌症死亡的最常见原因,其次是乳腺癌。为了预防肺癌死亡,高风险个体正在使用小剂量的CT扫描图来进行筛查,这是因为早期检测使肺癌患者的存活率增加了一倍。从CT扫描图图中自动识别癌性病变可以节省放射科医生的时间,这将使得诊断变得更加实惠,从而挽救更多的生命。
为了通过胸部CT预测肺癌,总体的策略是将高维CT图降维到一些感兴趣的区域,基于这些感兴趣的区域来预测肺癌。下面将解释如何训练几个网络来提取兴趣区域。
大海捞针
为了确定是否有人会发展成肺癌,不得不寻找早期阶段的恶性肺结节,而在肺部CT图中发现早期恶性结节就像大海捞针。为了说明这个声明,下面一起看看LngC / IDRI数据集中的恶性结节的例子,这些数据集是从LUng Node Analysis Grand Challenge中获得的,本文广泛使用了这个数据集(通常也被称为LUNA数据集,该数据集中包含已被诊断患有肺癌的患者)。
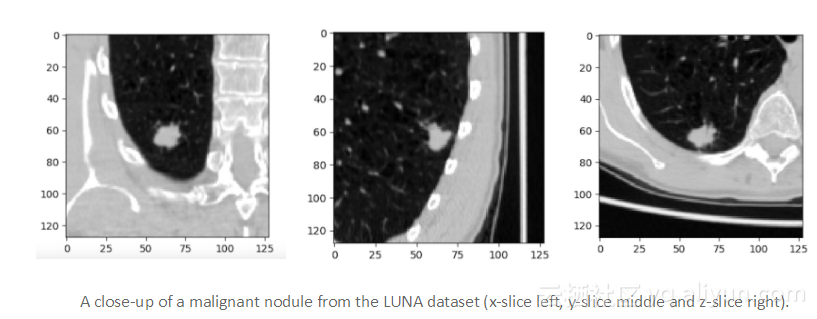
LUNA数据集中平均恶性肺结节的半径为4.8 mm,而普通的CT扫描图图采集的体积为400mm×400mm×400mm,真的是如大海捞针一样,即我们正在寻找一个比输入量小一百万倍的特征;此外,该特征决定了整个输入体积的分类。这对于放射科医师来说是一个巨大的负担,同时对于使用卷积网络的常规分类算法来说,也是一个困难的任务。
在竞赛中,上述问题变得更糟糕,因为必须从扫描日期的一年之内的一名患者中被诊断患有肺癌的患者CT图开始预测肺癌。在我们的病例中,患者可能尚未发展为恶性结节。因此,假设直接对竞争对手的数据和标签进行训练是不合理的。
结节检测
结节分割
为了减少扫描图中的信息量,首先尝试检测肺结节。由于LUNA数据集包含了患者扫描图中每个结节的位置和直径信息,因此可以通过建立了一个网络来分割扫描图中的结节,并使用数据集中记录的信息来训练搭建的分割网络。
为了解决不同CT扫描图仪产生的胸部扫描图的立体像素间距存在的差异,对所有CT扫描图图进行缩放和插值,以使得每个立体像素代表1x1x1毫米的立方体。为了训练分割网络,将CT扫描图中切割为64x64x64大小的图像块并将其作为分段网络的输入。对于每个图像块,其真值是一个32x32x32毫米的掩膜。掩膜中的每个立体像素表示该立体像素是否在结节内。掩模通过使用结节注释中的直径来构造。

本文将优化Dice系数作为目标函数,Dice系数是图像分割常用的度量标准。Dice系数的缺点在于若真值掩膜内没有结节,则它的默认值为零,每个图像块中必须有一个结节,并将其反馈给网络。应用平移和旋转增加方法引入额外的变化,选择合适的平移和旋转参数使得结节的一部分保留在64x64x64输入图像块的中心周围32x32x32立方体内。
网络架构如下图所示,该架构主要基于U-net架构(2D图像分割的通用架构),可以看到该架构主要由3x3x3无填充的滤波器的卷积层组成。
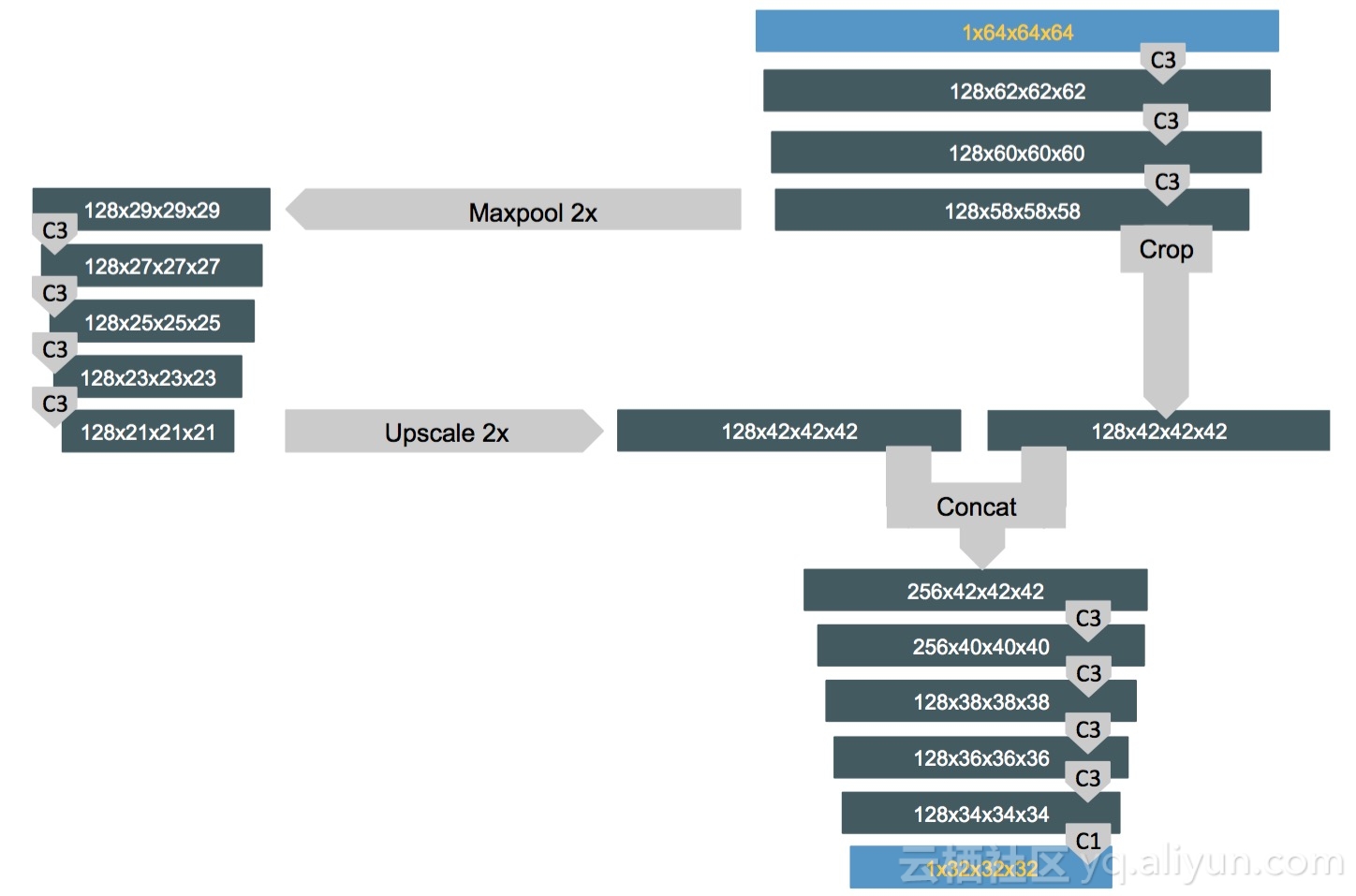
张量形状用深灰色框表示,浅灰色方框内表示网络操作。C1卷积层是1x1x1大小的滤波器,C3卷积层是3×3×3大小的滤波器。将训练好的网络用于分割LUNA和DSB数据集中患者CT扫描图,64x64x64的图像块以32x32x32的速度取出,并将输出拼接在一起后得到的一个张量中,张量中的每个值表示立体像素位于结节内的预测概率。
斑点检测
这个阶段是对肺扫描图中的每个立体像素进行预测,但是我们还想找出结节的中心,并将其中心将被用作结节候选者的中心。
本文使用高斯差分(DoG)方法检测斑块,使用拉普拉斯算子计算密度较小的近似值。另外使用以下两种方法可以降低结节候选者的数量:
- 在斑点检测之前应用肺分割
- 训练假阳性以减少专家网络
肺的分割
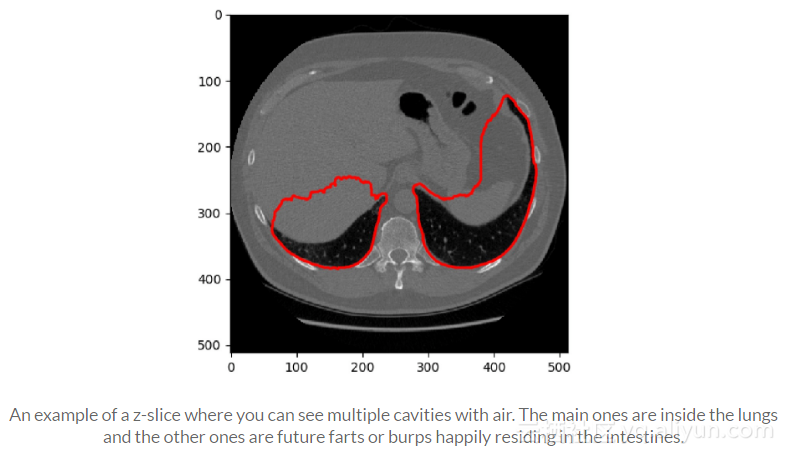
结节分割网络无法看到全部内容,因此在肺的外部产生了许多假阳性结果,为了缓解这个问题,采用手工设计的肺分割方法。
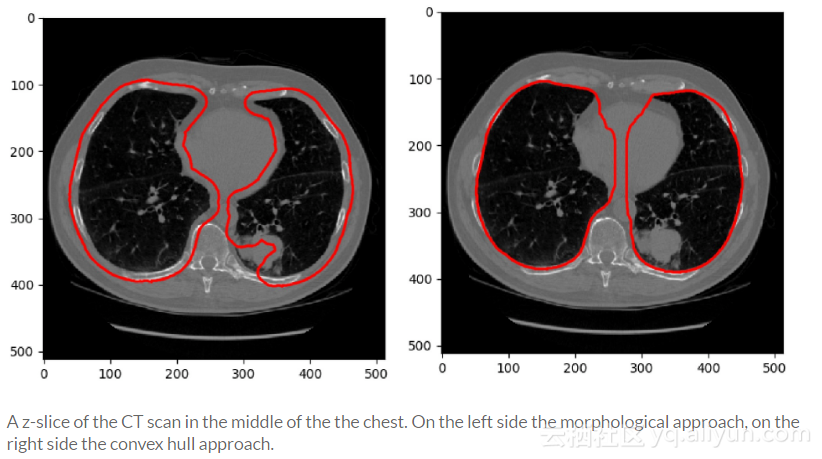
起初,采用了类似于Kaggle教程中提出的策略,它使用一些形态学操作来分割肺。但通过检查后发现,肺分割的质量和计算时间太依赖于架构元素的大小。
最终采用的方法是3D方法,其重点是从围绕肺部的凸包中切出非肺腔。
为了进一步减少结节候选人的数量,我们训练了专家网络来预测斑点检测后的给定候选者是否确实是一个结节。我们使用假和真结节候选人的名单来训练专家网络。LUNA大挑战为每个病人提供一个虚假和真正的结节候选人名单。
为了训练假阳性减少专家,我们使用了48x48x48图像块,并应用全旋转和微移增加方法(±3 mm)。
架构
如果想要网络检测到小结节(直径<= 3mm)和大结节(直径> 30 mm),架构应使网络能够以非常窄的和广泛的接受域来训练这两个特征。我们的架构主要是基于RESNET V2这种架构(非常适合于不同的感受野的训练特点),并对其简化,将其原理应用于具有3个空间维度的张量。
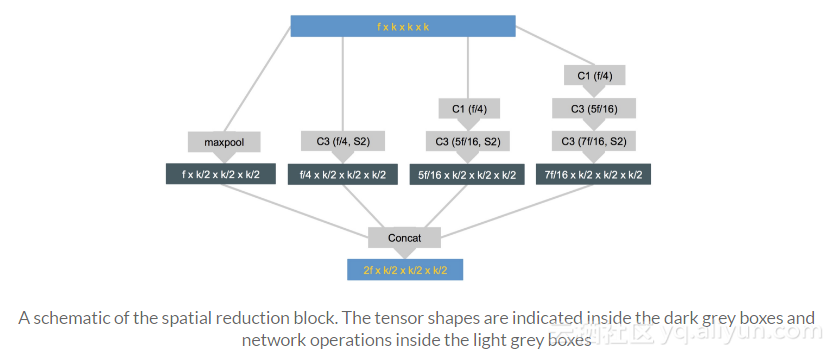
空间缩减块,通过应用不同的缩减方法,将输入张量的空间尺寸减半。
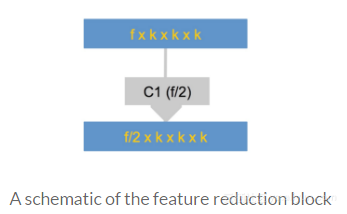
特征缩减块中的1x1x1滤波器内核卷积层是用来减少特征的数量。滤波器内核的数量(f/2)是输入特征图数量(f)的一半。
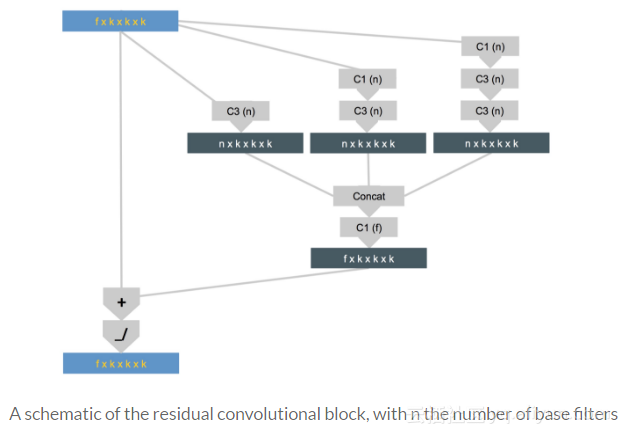
该残差卷积块包含三个不同的堆叠,每个堆叠具有不同数量的卷积层。最浅的堆叠不会扩大接收域,因为它只有一个具有1x1x1过滤器的卷积层。然而,最深的堆叠会扩大接收域。之后,不同堆叠的特征图被连接和缩小后再次与输入图叠加到一起。最后,经过应用ReLu非线性激活函数。
通过实验发现以下是减少假阳性最有效的架构:
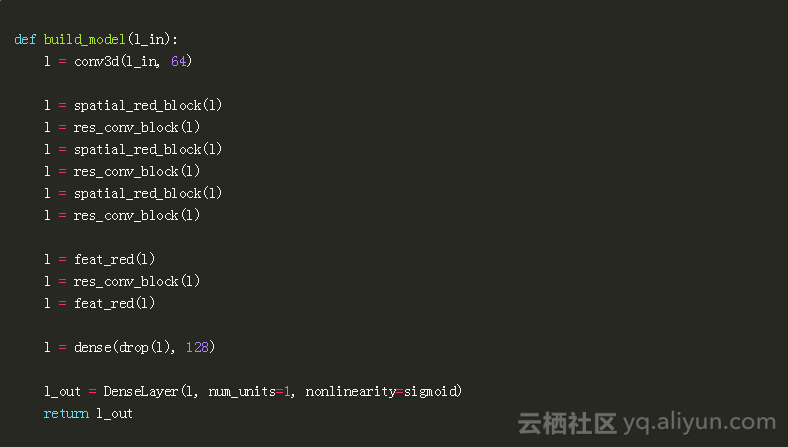
与初始版本的resnet v2架构相比的一个重要区别是创建的网络开始时只有一个卷积层。
结果
LUNA数据集的验证子集由118个患者(总共238个结节)的组成。通过分割和斑点检测后,发现229个结节中的,但仍然有大约17K个假阳性。为了减少假阳性,将候选人按照假阳性减少网络给出的预测进行排名。

恶性肿瘤的预测
在比赛的最后2周里,我们发现LUNA数据集中的结节存在恶性肿瘤标签。这些标签是LUNA所基于的LIDC-IDRI数据集的一部分。只有当我们训练了一个模型来预测个体结节/图像块的恶性肿瘤时,才能够接近LB的最高分数。

可以看到使用的网络与FPR网络架构非常相似。
之后重新缩放恶性肿瘤标签,以便它们在0和1之间表示。通过在LUNA数据集中抽取等量的不具有恶性肿瘤标签的候选结节来作为训练集。
另外使用均方误差(MSE)损失作为目标函数,这比二进制交叉熵目标函数性能更好。
肺癌预测
使用假阳性减少网络对候选结节进行排序,并训练构建的恶性肿瘤预测网络,之后就可以在Kaggle数据集上训练一个肺癌预测网络。采用的方法是通过相同的子网发送一组n个靠前的候选结节,并将最终汇聚层中的各个评分/预测值/激活值结合起来。
迁移学习
在训练了不同的架构后,我们意识到需要更好的推理特征的方法。虽然CT扫描图被缩减到一些感兴趣的区域,但患者数量仍然很低,这也导致恶性结节的数量很少。因此,我们专注于使用预先训练的权重来初始化网络。
迁移学习的思想在彩色图像分类任务中非常流行,其中大多数的迁移学习方法是将ImageNet数据集上训练的网络作为其自己网络的卷积层,这些卷积层在大数据集上学到了很好的特征,然后作为另一个神经网络/另一个分类任务的一部分重新使用(迁移)。然而,对于CT扫描图,需要自己训练一个这样的网络。
起初使用的是一些改进的fpr网络,后来是训练了一个网络来预测结节的大小。在这两种情况下,我们的主要方法是反复使用卷积层,但都是随机初始化。
在最后几个星期里,我们使用完整的恶性肿瘤网络并在添加了一个聚合层,这就得到了最好的解决方案。
聚合结节的预测
我们尝试几种不同的方法去结合节点的恶性肿瘤预测,下面强调两种最成功的聚合方法:
- P_patient_cancer = 1 - Π P_nodule_benign:这种聚合背后的想法是,如果所有结节都是良性的,那么患癌症的概率等于1;如果一个结节被分类为恶性肿瘤,P_patient_cancer将是1。这种方法存在的问题是,当恶性肿瘤预测网络相信有一个结节是恶性时,其表现不佳,所有一旦网络正确地预测到一个结节是恶性的时,终止学习。
- 对数平均指数(LME):这种聚合背后的想法是,癌症概率是由最恶性/最不良良性结节来决定,它以指数方式打破了单个结节的预测,因此专注于最大的概率。与简单的最大函数相比,此函数还允许通过其他预测的网络进行反向传播。
集成
我们整体合并了30个最后阶段模型的预测,由于Kaggle允许两次提交,因此使用以下两种集成方法:
积极集成:交叉验证用于选择均匀混合的高分模型。在这个集成中使用的模型对所有数据进行了训练,因此命名为“积极集成”。统一地混合这些“好”模型以避免由于在权重优化过程中具有较高修剪因子而导致极少数模型集成的风险。它还可以减少过载模型的影响。
最后的想法
挑战赛的很大一部分工作是建立一个完整的系统,它包括相当多的步骤。由于没有时间完全了解每一个部分,所以该系统还有很大的改进空间,另外感谢比赛的组织者。
黑客排行榜
在比赛开始之前,巧妙地推出了排行榜的真值标签,它利用了从提交预测时返回的高精度分数得到的信息。因此,每个人都可以通过有限数量的提交结果来更新排行榜。
通常,排行榜真实地表明了其他队伍的表现,但由于队伍完全处于不知情中,这会对其动力产生不利的影响。因此,Kaggle通过截断提交后返回的分数来避免这种情况的出现。
作者信息
Elias Vansteenkiste :博士后研究员,对深度学习、人工智能、人机界面和计算机辅助设计算法感兴趣。
Github:https://github.com/EliasVansteenkiste
Linkedin:https://www.linkedin.com/in/elias-vansteenkiste-33060839/
Youtubu:https://www.youtube.com/EliasVansteenkiste
Twitter:https://twitter.com/sailenav
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Predicting lung cancer》,作者:Elias Vansteenkiste,译者:海棠,审阅:
文章为简译,更为详细的内容,请查看原文
翻译者: 海棠