使用持久化
GemFire支持无共享存储持久化。每一个VM写入他们的region data到自己的磁盘文件中。
People region来说,每一个region将要写入整个的region到自己的磁盘文件中。而post region每一份拷贝都将要存在两个不同的peer中。
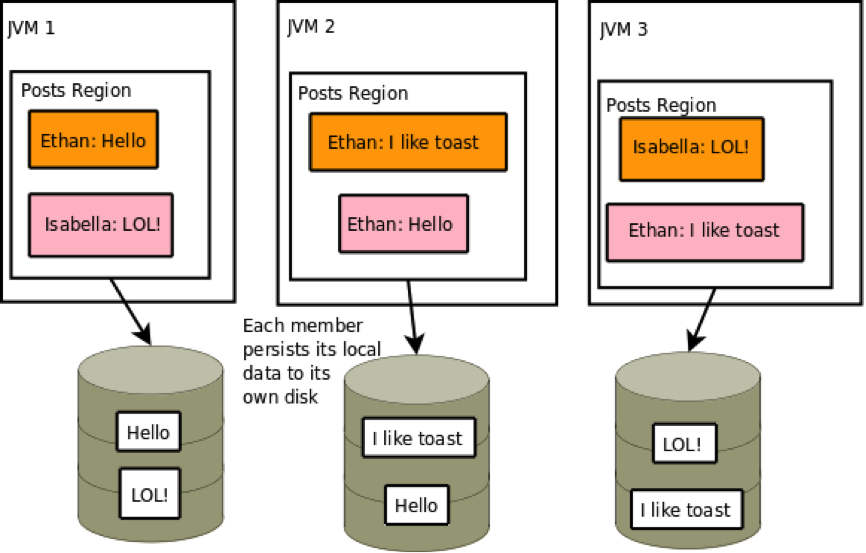
当你重启持久化成员,你需要调用cacheserver start并行地在每个服务器。
原因是GemFire保证了你完整的数据被在VM重启的时候被恢复。每一个VM只能持久化他自己的post部分。每一个GemFire VM等待直到所有的posts都可用。这阻止你看一个不完全的post region视图。
其他的特性
这有一些其他的GemFire特性你能够用来扩展这个例子。
GemFire快速序列化
在这个例子中,PostID和Profile类实现了java.io. Serializable.但是有些时候java的序列化是低效的,序列化使用了反射机制来使域对象序列化。序列化对象写入了整个类名和域名到输出流。GemFire提供了更高效的序列化机制,你能使用它来提高序列化性能。在java c++和c#客户端共享数据更简单(这个真的很强大)。
Locator冗余
在这个例子中,我们只使用了一个简单的locator,能够引起SPOF。在生产环境中,我们至少使用两个locator。Locators属性接受了一个locator列表。
执行查询
假设你想要显示所有的people。GemFire支持query region OQL。
持续查询
在这个例子中客户端注册interest更新进入people region使用正则表达式。你也能够注册更新使用OQL语句。例如,你能为特定用户注册所有的posts。
网格编程模型
缺省情况下,posts被指定到不同的peers基于key的哈希码。那就意味着没有哪一个post到哪一个server。如果你需要做什么东西从一个特定的用户那里。比如运行拼音检查你必须访问不同的peer中的post。通过用户名来组织这些posts是高效的,这样拼写检查能够在单一的VM上来运行,GemFire通过PartitionResolver来做这个事情。Partition Resolver让你返回一个值来指定一个键值属于哪个逻辑组。在这个例子中,PartitionResolver能够返回PostID的author field。他能够告诉GemFire放所有的post在相同的VM和相同的author上。
一旦posts被逻辑地组团。你需要执行你的拼写检查在存储posts上的VM。GemFire传递功能到peers的子集上。这些功能在peers的子集上并行执行。执行拼写检查功能
SpellingCheck spellcheck = new SpellingCheck(); //implements Function
Set<String> authors = new HashSet<String();
authors.add("Ethan");
FunctionService.onRegion(people).withFilter(authors).execute(spellcheck);
多地域 WAN 网关
如果你有多个数据中心在远程,处于不同位置的GemFire Peers之间的同步复制可能会导致太多的延迟。GemFire提供了WAN 网关,允许两个和更多的远程站点异步发送更新。使用网关很多的更新立即被发送到来提高吞吐能力
缓存writer和loader
如你所见,在一个条目被改变之后,一个CacheListener 回调函数被调用。在一个条目被更新之前CacheWriter回调函数被调用。你能够阻塞更新或者发送更新到其他的系统在cachewriter中。你能够添加CacheLoader回调到一个region来获取或者生成一个值,如果他不在缓存中,当get被调用。
清除和超时
GemFire提供了完全的支持对于eviction 和expiration在缓存中。你能够限制一个region的大小来接受特定的条目或者特定的空间大小。你能配置region在一定时间之后条目超时或者简单地清除条目当你的堆栈满员的时候。
你也能够配置region条目溢出到磁盘,而不是完全地丢掉它。




