本节书摘来自异步社区《思科UCS服务器统一计算》一书中的第2章,第2.4节,作者 【美】Silvano Gai , Tommi Salli , Roger Andersson,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.4 Intel微架构
思科UCS服务器统一计算
思科UCS使用Nehalem和Westmere微架构(更通用点说,是32nm和45nm的Hi-k Intel Core™微架构)的Intel处理器。
Nehalem微架构于2009年初引入到了服务器中,也是Intel[32]、[32]、[34]开发的第一个使用45nm硅技术的架构。Nehalem处理器可广泛应用于高端桌面应用程序、超大规模服务器平台等。代号名来源于位于太平洋西北岸的美国俄勒冈州的Nehalem河。
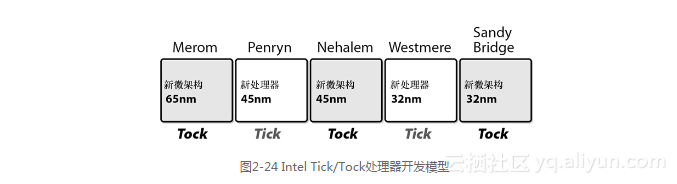
根据Intel公司的说法,处理器的发展速度就像嘀嗒钟声的节奏一样,如图2-24所示。Tick是缩小现有的处理器架构,而Tock则是在前一代技术上发展起来的全新架构。Nehalem就是45nm的Tock,Westmere则是紧跟Nehalem的32nm Tick。
Nehalem和Westmere在不同需求之间取得了平衡:
与新兴应用程序(如多媒体)相比,现有应用程序的性能;
对轻量级或重量级线程应用程序同样良好的支持;
覆盖从便携式计算机到服务器的实现。
它们试图在优化性能的同时降低功耗。这里的讨论基于一个优秀的Intel开发论坛教程[32]。在本章的其余部分,只讨论与Nehalem微架构相关的创新,这些创新在Westmere架构中也得到继承。Nehalem和Westmere架构有一些地方有所不同,会特别指出。
2.4.1 平台架构
这可能是近10年来Intel最大的一次平台架构转变。该架构包括多个高速点对点连接,即Intel的QuickPath互联(参见本章的“专用高速互联”部分),以及集成内存控制器(Integrated Memory Controllers,IMC)的使用,这和基于FSB的方法完全不同。
图2-25显示了一个双插槽的Intel Xeon 5500(Nehalem-EP)系统示例。请注意,CPU插槽之间、从CPU插槽到I/O控制器之间的QPI链接,以及直接附加到CPU插槽的内存DIMM。

集成内存控制器(IMC)
在Nehalem-EP和Westmere-EP中,每个包含集成内存控制器(IMC)的插槽支持3个DDR3内存通道(参见本章的“DDR2和DDR3”部分)。与DDR2相比,DDR3内存的运行频率更高,因此具有更高的内存带宽。此外,对于双插槽架构,有两套内存控制器而不是一套。所有这些改进使得带宽与前一代Intel平台相比提高了3.4倍(参见图2-26)。
随着时间推移,带宽以后还会持续增加,因为会有速度更快的DDR3。有了集成内存控制器后,延迟也减小了。
与DDR2的1.8V相比,由于DDR3采用了1.5V技术,因此其功耗也降低了。功耗与电压的平方成正比,因此电压降低20%,功耗就降低约40%。
最后,IMC支持单、双和四个列的RDIMM和UDIMM(只有RDIMM支持4个列,参见本章的“内存列”与“UDIMM和RDIMM”这两部分)。

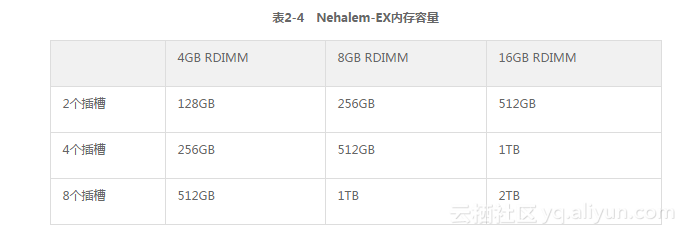
Nehalem-EX有一个类似但不完全相同的架构。在Nehalem-EX中,每个插槽有两个IMC。每个IMC支持两个Intel可扩展内存互联(Scalable Memory Interconnects,SMI)连接到两个可扩展内存缓存区(Scalable Memory Buffers,SMB),每个插槽就可以连接到4个SMB(参见图2-27)。每个SMB有两个DDR3总线,每条总线连接两个DIMM。因此,每个插槽可连接的RDIMM总数就是16。

表2-4总结了根据插槽数量和RDIMM容量计算的Nehalem-EX系统的总内存容量。
随着时间的推移,所有的通信架构都从总线架构向速度更快且扩展性更好的点对点链接演变。在Nehalem中,Intel QuickPath互联已经取代了前端总线(参见图2-28)。

Intel QuickPath互联是由Intel引入的一个一致的点对点协议,不局限于任何特定的处理器,且可在处理器、I/O设备和加速器之类的其他设备之间提供通信。
可用的QPI数量取决于处理器的类型。在Nehalem-EP和Westmere-EP中,每个插槽有两个QPI,支持如图2-25所示的拓扑结构。Nehalem-EX支持4个QPI,允许实现更多无缝连接的拓扑结构,如图2-29所示。
Intel Xeon 7500处理器也与第三方节点控制器兼容,能够与多于8个的插槽互联,从而使得系统实现更强的可扩展性。

2.4.2 CPU架构
Nehalem通过大量创新增加了每个CPU每秒执行的指令数,如图2-30所示。

其中有些创新是不言而喻的,我们将集中介绍最重要的性能与功耗方面的创新。
在比较性能和功耗时,通常假定1%的性能提升就会导致3%的功耗增加。这是因为减少1%的电压,功耗几乎总是降低3%(参见本章的“芯片设计”部分)。
Intel公司最重要的创新就是增强1%的性能,而功耗仅增加了1%。
1.Intel超线程技术(Intel HT technology)
Intel超线程技术可在同一核心上同时运行多个线程,在Nehalem/Westmere中实现了两个线程。这提高了性能和能源效率(参见本章2.1节中的“Intel超线程技术”部分)。
超线程的基本理念是,随着每个执行单元复杂度的增加,对于单线程来说,要保持执行单元繁忙是很困难的。通过在同一核心上运行两个线程,让所有资源保持忙碌的可能性更大,这样整体效率就提高了(参见图2-31)。超线程使用的领域非常有限(不到5%),但在多线程环境中极大地提高了效率。超线程也不是对多核心的替代,只是通过支持每个核心同时执行两个线程来对核心进行合理补充。
2.缓存层次结构
对理想的内存系统的需求是:它应该具有无限容量、无限带宽和零延迟。当然,没有人知道如何构建这样的系统。最接近的方法是实现一个从较大且较慢到较小且较快的内存子系统层次结构。在Nehalem中,Intel将缓存层从2层增加到了3层(参见图2-32),从而添加了1级层次结构。
与Intel以前的设计相比,一级缓存(L1,指令和数据)没有发生变化。在Intel过去的设计中,所有核心共享二级缓存(L2)。如果核心数量限制为2,那么这种设计倒是可行的。但Nehalem将核心数增加到了4或8,二级缓存就不能再继续共享下去了,因为带宽和仲裁请求都会增加(可能会达到8倍)。为此,Intel在Nehalem中为每个核心增加了专用的二级缓存(指令和数据),以减少到共享的高速缓存(现在是三级缓存,L3)的带宽。

3.分段
Nehalem采用了模块化设计。核心、缓存、IMC和Intel QPI都是组成Nehalem处理器的模块示例(参见图2-30)。
这些模块都是独立设计的,它们可以以不同频率、在不同电压下运行。将模块粘接在一起的技术是一种新的同步通信协议,该协议提供了非常低的延迟。以前曾尝试过使用异步协议,但事实证明那样做的效率非常低。
4.集成功率门限
这是一种电源管理技术,它是“时钟门控”技术进化版本,所有现代Intel处理器都使用了时钟门控技术。遇到空闲逻辑时,时钟门控会切断时钟信号,从而免除了开关电源,但仍然存在漏电流。漏电流产生了无用的功耗。随着通道长度减少,从大约130nm开始,漏电流已经占据了电源的很大一部分,到了45nm时,就会相当高了。
相反,功率门限同时关闭开关和漏电,使得空闲核心耗电几乎为零(参见图2-33)。对于软件和应用程序来说,这完全是透明的。
从技术角度来看,实现功率门限是很难的。传统的45nm工艺就存在明显的泄漏。它需要新的晶体管技术和大量铜层(7mm),以前可从来没有这么做过(参见图2-34)。
随着通道长度不断变短,功率门限也变得越来越重要,这是因为漏电流在不断增加。在22nm时,功率门限至关重要。

Nehalem-EP和Westmere-EP都拥有“动态的”功率门限能力,当核心不需要执行工作负载时,可以完全关闭核心电源。之后,当工作负载需要核心的计算能力时,核心的电源又重新激活。
Nehalem-EX拥有“静态的”功率门限功能。某些核心出厂时就禁用,如当8核心熔合成6核心时,核心电源就会完全关闭。这些禁用的核心不能重新启用。对于前几代处理器,在工厂中禁用的核心仍然会消耗一些电力,但在Nehalem-EX中,电源是完全关闭的。
5.电源管理
功率传感器是构建电源管理系统的关键。上一代Intel CPU具有热传感器,但没有功率传感器。Nehalem既有热传感器又有功率传感器,通过负责电源管理的集成微控制器(PCU)来进行监控(参见图2-35)。

6.Intel智能加速技术
功率门限和电源管理是Intel智能加速技术(Turbo Boost Technology)的基本组件。如果环境条件允许(足够的制冷和供电能力),例如,因为一个或多个核心被关闭,当操作系统需要更高的性能时,可以使用Intel的智能加速模式。Intel智能加速会提高活动核心的频率(以及功耗),从而提高指定核心的性能(参见图2-36)。这算不上是巨大的改进(从3%到11%),但在线程很少或者并不是所有核心都被并行使用的环境中,Intel智能加速还是很有价值的。每上升一步,频率提高133MHz。
图2-36显示了3种不同的可能性:正常情况下,所有核心都以标称频率(2.66GHz)运行;在4C Turbo模式下,所有核心的频率都上升了一步(例如,达到了2.79GHz);在<4C Turbo模式下,两个核心的频率都上升了两步(例如,达到了2.93GHz)。

2.4.3 虚拟化支持
Intel虚拟化技术(Virtualization Technology,VT)扩展了核心平台架构,可以更好地支持虚拟化软件——例如,虚拟机(Virtual Machine,VM)和Hypervisor(也称为虚拟机监视程序,Virtual Machine Monitor,VMM),参见图2-37。

VT包含4个主要的组件。
Intel VT-x:指的是Intel 64和IA32处理器中所有硬件辅助虚拟化技术。
用于直接I/O的Intel VT-d(Intel VT-d):指的是Intel芯片组中所有硬件辅助虚拟化技术。
用于互连的Intel VT-c(Intel VT-c):指的是Intel网络和I/O设备中所有硬件辅助虚拟化技术;
简化虚拟机移动的VT Flex Migration。
Intel VT-x增强包括以下内容。
一个新的、更高特权的Hypervisor——允许来宾操作系统和应用程序运行在为其设计的特权级别中,确保Hypervisor有权控制平台资源。
基于硬件的转换——在硬件级支持Hypervisor和来宾操作系统之间的切换。这减少了复杂的、计算密集型软件转换需求。
基于硬件的内存保护——在专用的地址空间中为Hypervisor和每个来宾操作系统保留处理器状态信息。这有助于加速转换并确保过程的完整性。
此外,Nehalem还增加了:
扩展页表(Extended Page Table,EPT);
虚拟处理器ID(Virtual Processor ID,VPID);
客户机抢占计时器(Guest Preemption Timer);
描述符表退出(Descriptor Table Exiting);
Intel虚拟化技术FlexPriority;
暂停循环退出(Pause Loop Exiting)。
1.VT Flex迁移
FlexMigration允许在不同指令集处理器 之间迁移VM。它是通过同步所有处理器 都支持的最小指令集来实现的。
当第一次实例化VM时,它会查询处理器 来获取指令集水平(SSE2、SSE3和SSE4)。处理器 返回池中商定的最低指令集水平,而不是处理器 本身支持的指令集水平。这就允许在具有不同指令集的处理器之间实现VMotion。
2.扩展页表(EPT)
EPT是一种处于Hypervisor控制下的新页表结构(参见图2-38)。EPT定义了客户机物理地址和主机物理地址之间的映射。

在虚拟化之前,每个操作系统负责虚拟应用程序地址和“物理地址”之间的程序页表转换。使用虚拟化后,这些地址就不再是物理的了,而是在VM中的虚拟地址。Hypervisor需要在客户机操作系统地址和真实物理地址之间转换。在EPT出现之前,Hypervisor通过软件的方式在重要的边界(如VM的入口和出口)更新它们来维护页表。
有了EPT后,无需Hypervisor的介入,EPT基指针和EPT页表支持直接从虚拟地址转换到物理地址,这种转换方式与操作系统在原生环境中的转换方式类似。
3.虚拟处理器ID(VPID)
这是分配一个VM ID来标记CPU硬件结构(如,转换后备缓存区TLB,Translation Lookaside Buffers),以避免在VM转换时清洗的一种能力。
在VPID出现之前的虚拟化环境中,CPU会无条件为每个VM转换(如VM入口/出口)清洗TLB。这样做的效率很低,并且会降低CPU性能。有了VPID后,Hypervisor使用一个ID标记TLB,这可以更高效地清洗缓存区中的信息(只清洗需要的)。
4.客户机抢占计时器
有了这个功能后,Hypervisor可在一段指定时间后让客户机优先执行。在进入客户机之前,Hypervisor会设置一个计时器值,当计时器清零时,VM就退出。计时器会让VM无需中断就直接退出,因此使用这个功能时就不会影响VMM虚拟化中断的方式。
5.描述符表退出
通过预防关键系统数据结构被修改,使VMM可以保护客户机操作系统免受内部攻击。
操作系统操作由一组CPU使用的关键数据结构(IDT、GDT、LDT和TSS)控制。如果没有这个功能,Hypervisor就无法预防在客户机操作系统上运行的恶意软件修改这些数据结构的副本。Hypervisor使用这个功能可拦截修改这些数据结构的尝试,从而禁止恶意软件的入侵。
6.FlexPriority
这是一种改进32位客户机操作系统性能的技术,旨在加快虚拟化中断处理速度,从而提高虚拟化性能。FlexPriority通过避免访问高级可编程中断控制器时不必要的VMExits来提高中断处理速度。
7.暂停循环退出
这项技术检测多处理客户机的自旋锁以减少“锁定者抢占(lock-holder preemption)”。如果没有这项技术,指定的虚拟处理器(vCPU)可能会在锁定时被抢占。其他想获取锁定的vCPU会在整个执行时间片内自旋。
在Nehalem-EX中使用了这项技术,但在Nehalem-EP中没有使用该技术。
2.4.4 高级可靠性
与Nehalem-EP相比,在Nehalem-EX中对高级可靠性进行了许多创新,或者更确切地说,应该是可靠性、可用性和可维护性(RAS),参见图2-39。

具体来讲,所有主要的处理器功能都具有RAS特性,包括QPI RAS、I/O集线器(IOH)RAS、内存RAS和插槽RAS。
纠错现在使用修正机器校验中断(Corrected Machine Check Interrupts,CMCI)来发出信号。
另一种RAS技术是机器校验架构恢复(Machine Check Architecture-recovery,MCAr);也就是CPU向操作系统报告硬件错误的一种机制。有了MCAr后,就可以从致命的系统错误中恢复过来。
部分功能需要操作系统的额外支持,或需要硬件供应商的实现和验证。
这项技术目前仅在Nehalem-EX中实现。
2.4.5 高级加密标准
Westmere-EP增加了6个新指令来加速常见高级加密标准(Advanced Encryption Standard,AES)算法的加密和解密。有了这些指令后,所有AES运算都通过硬件完成,这样不只是速度更快,比起软件实现也更安全。
这使得应用程序可使用更强的密钥且开销更小。应用程序可以加密更多数据以满足监管要求,除了更安全外,对性能的影响也更小了。
这项技术目前仅在Westmere-EP中实现。
2.4.6 可信执行技术
Intel可信执行技术(Trusted Execution Technology,TXT)有助于检测和预防基于软件的攻击,特别是:
插入非可信VMM(Rootkit Hypervisor)攻击;
威胁到平台内存中机密的攻击;
BIOS和固件更新攻击。
Intel TXT使用一个组合了处理器、芯片组和可信平台模块(Trusted Platform Module,TPM)的技术测量引导环境以检测软件攻击(参见图2-40)。
这项技术仅在Westmere-EP中实现。

2.4.7 芯片设计
如果想获得高性能又想限制功耗,那么就需要在几个不同因素间达到平衡。
随着晶体管通道长度的逐渐缩短,可用的电压范围也越来越有限(参见图2-41)。

最高电压受总功耗以及与高功率相关的可靠性下降的限制,最低电压主要受软错误(特别是存储器电路中的错误)限制。
一般说来,在CMOS设计中,性能与电压成正比,因为电压越高频率也越高。
性能~频率~电压
功耗与频率和电压的平方成正比:
功率~频率×电压2
由于频率和电压是成正比的,因此:
功率~电压3
能源效率定义为性能和功率之间的比率,因此:
能源效率~1/电压2
因此,从能源效率的角度来看,降低电压(即功率,参见图2-42)才会凸现优势,因而Intel已经决定着手解决这个问题。

由于更容易遭受软错误影响的电路是内存,因此,Intel在Nehalem中加入了复杂的纠错码(三重检测,双重纠错)来纠正这些软错误。此外,缓存的电压和核心的电压是解耦的,因此缓存可以保留高电压,而核心可在低电压下工作。
对于L1和L2缓存,Intel已采用新的8晶体管设计(8-T SRAM)取代了传统的6晶体管SRAM(6-T SRAM)设计,这解耦了读和写操作,并允许使用更低的电压(参见图2-43)。
同样,为了降低功耗,Intel又回到了能耗更低的静态CMOS技术(参见图2-44)。
通过重新设计一些关键算法(如指令解码),性能得以再次提升。