袋鼠学院和优云、阿里云联合举办的沙龙结束之后,总是有小伙伴们来问PPT内容,想要进一步了解Topic内容。(哦,对了对了,竟然还有小伙伴专门冲着袋鼠云去听沙龙,感动cry~~)
千呼万唤,忙成狗的袋鼠小妹终于把沙龙总结整理了出来(⊙o⊙)
本次沙龙的主题是“云时代下的运维管理实践”,受邀请的演讲嘉宾,花名宏翊(经常关注袋鼠云的同学,肯定已经对这个名字很熟悉了),是袋鼠云首席数据库架构师,袋鼠学院数据库讲师。
呼应沙龙运维实践的主题,结合自己的专长领域,宏翊主要是从数据库领域来谈云时代下的运维管理该如何做,主题为“如何实现高容量大并发数据库服务?之数据库分布式架构设计”。

为什么数据库需要做分布式架构设计?在对数据库进行拆分设计和实施时,会遇到哪些坑?又该如何避免踩坑?
袋鼠小妹结合宏翊的PPT和现场演讲,整理内容如下,希望和大家一起分享、探讨。
摘要
数据库拆分要根据业务现状、模式,选择合适的拆分方式,紧密结合业务及应用架构设计,谨慎拆分,防止过度设计。
正文
一 为什么要做分布式数据库架构改造?
云计算大数据时代,传统的数据库架构已经无法支撑企业高容量的数据增长,满足高并发的业务需求。对企业数据库进行分布式架构设计,打破了数据库资源不够用的天花板的同时,还能根据企业业务发展状况,随时平滑扩容。
二 分布式数据库架构改造,如何做?
数据库分布式改造要遵循“循序渐进”的拆分原则
拆分方式有垂直拆分和水平拆分两种,选择拆分方式要根据企业自身业务发展需要。
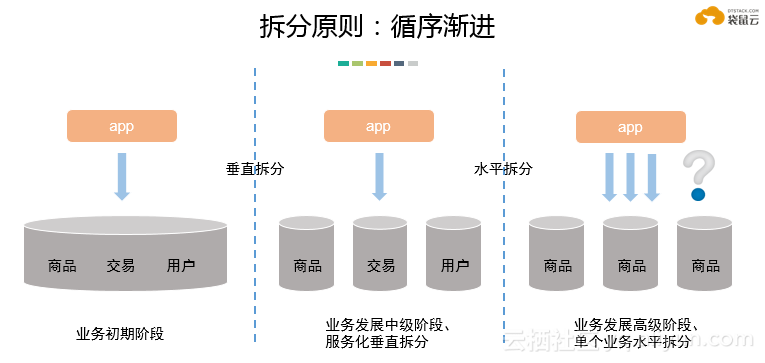
一般来说,是先做垂直拆分,再做水平拆分。
在单一数据节点无法满足业务和用户增长需求的情况下,需要做一个服务化,对业务进行垂直梳理,后面的数据节点可以放在不同的资源节点上,以提高数据服务的整体性能。
比如一个APP的业务数据,在业务初期阶段,是全部放在一个数据库节点中,在业务量和数据量快速增长的中期阶段,需要进行垂直梳理,根据业务逻辑,拆分成商品、交易、用户,并分别放在不同的数据库。
如果其中的一个服务已经拆的很细了,但还是有性能瓶颈,无法支撑我们的业务增长,数据库这块才需要再做水平拆分。
水平拆分就是将数据(比如图中APP的交易数据)拆成多片,放到不同的资源上,用一个集群来支撑更高的业务增长。
在拆分时,要谨慎,因为拆分会引入复杂性,能不做就不做,最优先是做业务和架构上的优化,最终才是做数据库拆分。
在拆分的过程中,不要做过度的设计,或者直接从初级跳到高级,这样做其实非常浪费资源,投入产出比也不好。
三 水平拆分的难点及解决方案
对企业数据库进行分布式改造,需要理解客户的业务逻辑、丰富的拆分经验积累。尤其是水平拆分,有系统复杂度高、技术挑战性强、稳定性控制难、具有一定局限性四大难点。
针对这些问题,宏翊给我们提供了两种解决方案。
-
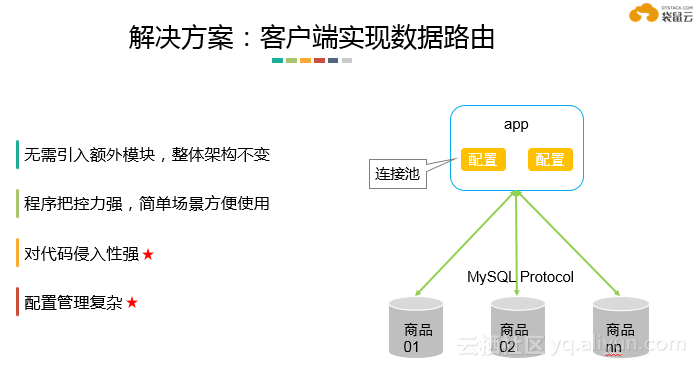
客户端实现数据路由
此方案不会引入额外的组件,架构上比较轻量,简单场景使用尚可,但稍复杂的场景会放大它的劣势,比如配置管理复杂等。
-
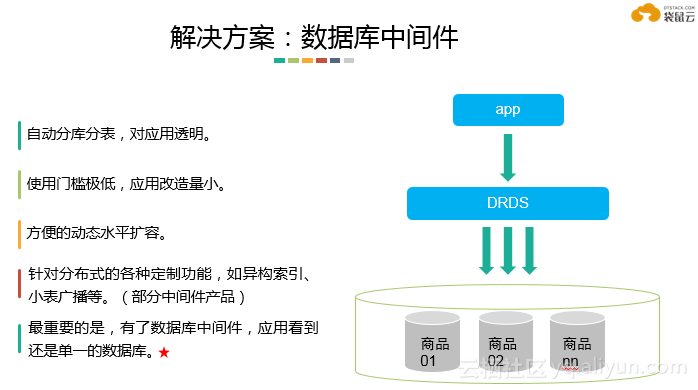
数据库中间件
中间件的使用最大限度地屏蔽了分布式数据库所引入的复杂性,极大降低了研发的门槛。最重要的是,有了数据库中间件,应用看到的还是单一的数据库。
四 水平切分原理及设计原则
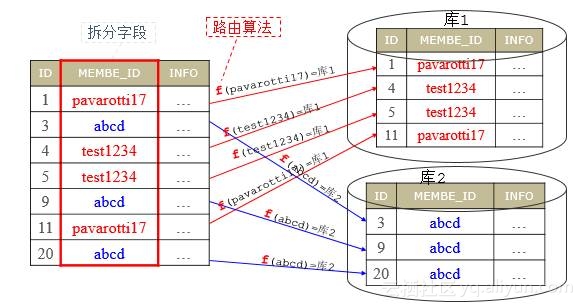
要对一个表做拆分,选择一个拆分字段,通过一个路由算法确定数据存放在哪个底层库。
比如下列数据选择MEMBE_ID作为拆分键,通过路由算法计算后得出’test1234‘相关的数据应该落在库1上,DRDS会把所有MEMBE_ID=‘test1234’相关的请求全都路由到库1。其他数据请求亦落到相应的底层库。
接下来,当数据已经放下去了,应该如何去查询、访问和变更?
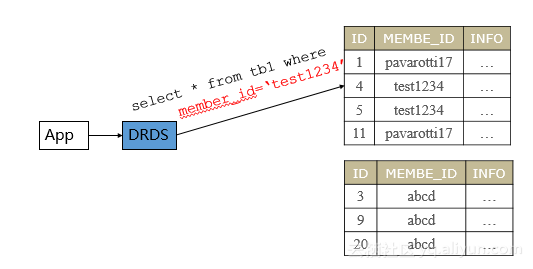
比如要查询一条记录,member_id=‘test1234’
它怎么去执行的呢?
首先计算一个hash值,当值等于某一个值,它会知道这个数据存储在哪一个库上,所以会直接路由到底层这个库,从这个库查询,返回结果。
中间件扮演的就是这个路由和计算的角色,性能非常强大。拆分后,各底层数据库数据量比较小,查询返回比较快;二是可以支持更高的并发,整体并发基本等于两个底层数据库实例并发之和。
五 来自阿里云的数据库中间件产品:DRDS
数据库中间件产品中,有平民软件OneProxy等商业软件;也有MyCat等开源产品,宏翊为大家则介绍了一款广泛使用的成熟商业产品DRDS,并讲解了DRDS如何解决对数据库进行拆分时遇到的难点。
DRDS,英文名Distributed Relational Database Service
是阿里巴巴自主研发致力于解决单机数据库服务瓶颈问题而推出的分布式数据库产品。 DRDS 高度兼容 MySQL 协议和语法、支持自动化水平拆分、平滑扩容、弹性扩展、透明读写分离、分布式事务、具备分布式数据库全生命周期的运维管控能力。DRDS前身为淘宝TDDL,是近千核心应用首选组件,已稳定服务8年以上。
DRDS五大核心功能
-
分库分表
分库分表是DRDS的核心功能,DRDS 在后端将数据量较大的数据表水平拆分到后端的每个 RDS 数据库中,这些拆分到 RDS 中的数据库被称为分库,分库中的表称为分表。拆分后,每个分库负责每一份数据的读写操作,从而有效的分散了整体访问压力。在系统扩容时,只需要水平增加分库的数量,并且迁移相关数据,就可以提高 DRDS 系统的总体容量。DRDS 支持库级拆分,表级拆分和分库分表拆分,通过 DRDS DDL 语句指定。
-
读写分离
在主实例的读请求较多、读压力比较大的时候,可以通过 DRDS 读写分离功能对读流量进行分流,减轻 RDS 主实例的读压力。
DRDS 的读写分离功能是对应用透明的设计。应用在不修改任何代码的情况下,只需要在 DRDS 控制台中调整读权重,即可将读流量按配置的比例在主 RDS 实例与多个 RDS 只读实例之间进行分流;写流量则全部到主实例,不做分流。
设置读写分离后,从主 RDS 实例读取的是强读,既实时强一致读,而只读实例上的数据是从主实例上异步复制的,存在毫秒级的延迟,因此从只读 RDS 实例读取的是弱读,属于非强一致性读。个别需要实时性、强一致性读的 SQL 可以通过 DRDS Hint 指定到主实例上执行。
-
全局唯一ID
DRDS 支持分布式全局唯一且有序递增的数字序列。满足业务在使用分布式数据库下对主键或者唯一键以及特定场景的需求。
-
小表广播
DRDS 将一些数据量小且更新频度不高的数据表存储为单表模式,这些数据表称为小表。通过数据同步将小表复制到与之 JOIN 的分库上进而提升 JOIN 效率的解决方案称为“小表广播”或者“小表复制”。支持查询引擎识别和下推复杂查询,兼容 98% MySQL 语法。
-
弹性扩容
当逻辑库对应的底层存储已经达到物理瓶颈,需要进行水平扩展,比如磁盘余量接近30%,那么可以通过平滑扩容来改善。平滑扩容是一种水平扩容方式,既把分库平滑迁移到新添加的底层存储上。在实现上是通过增加 RDS 实例的数量来提升总体数据存储容量,将分库迁移到新增的 RDS 实例,从而降低单个 RDS 实例的处理压力。
六 分布式改造之后——运维
进行分布式改造之后,如何更省心省力对数据库进行运维?
靠人工?成本高、运维人员也难招!
借助袋鼠云开发的数据库自动化管理平台EasyDB,企业数据库运维很简单。
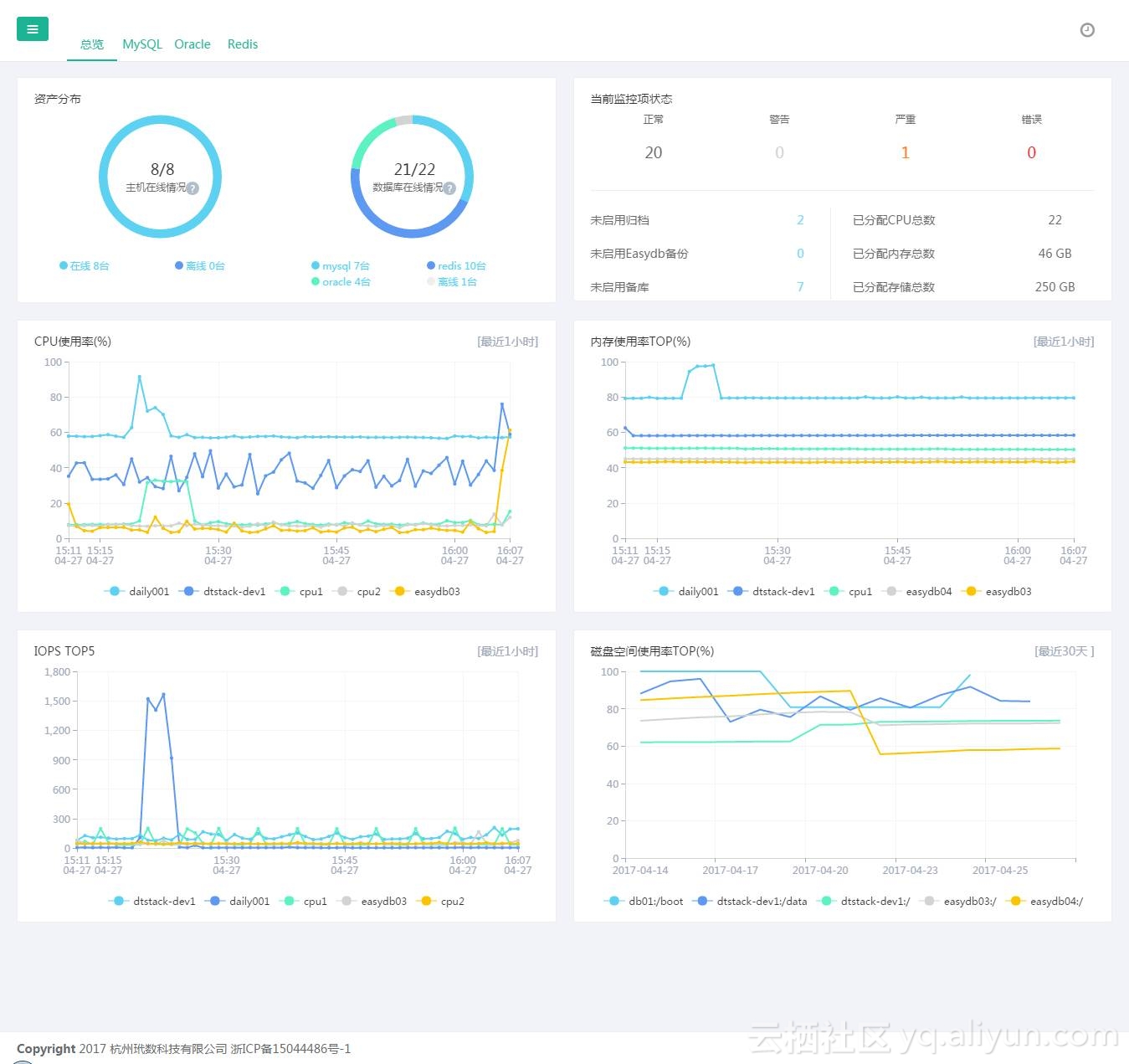
EasyDB完全兼容DRDS manager,具有高可用、高性能、易运维等特点。从性能、资源、集群、备份、容灾入手,支持多种数据库实例,大规模量的数据库运维,提供稳定准确的数据库告警、大盘趋势分析预警、空间跟踪、SQL跟踪、巡检报告等功能。运维管理人员可以轻松应对复杂的日常管理事务及突发性事件,数据库管理从此变得有规划,有效率,有预见性。