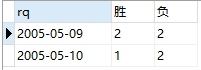
看到楼下各位兄弟的批评指正后,确实对我很有启发,任务如果都以配置的形式出现,在项目中是很利于维护的,所以,稍作修改,呵呵。
首先要做QuartzJob定时任务类了,这个类要实现的是Job接口,然后重写execute方法,方法中就是执行你具体要做的事情了。不过首先需要一个配置文件,里面定义了一些参数,是Quartz的一些配置。配置文件如下
即使做成配置,这个类也必须要有,一定会有个Job类,专门做数据分析,有的朋友说配置文件搞定所有,不现实,
好了,这就是配置文件,接下来我们就要做这个计划类了,这个类执行的是去源数据库中查询数据,并插入目标数据库中,并且不允许有重复。代码如下
这里一次性查出了源数据库中所有字段,因为源数据库表中的数据最多不会超过10000条,我在做测试的时候,在本机上发现一次查询10W条也不会出现结果集溢出情况,所以这里就忽略这个问题了。
然后需要这么个配置文件quartz_jobs.xml,内容如下
ok,最后就是web.xml文件配置一下,Quartz提供了个初始化的Servlet,呵呵,内容如下
这样就搞定了,
首先要做QuartzJob定时任务类了,这个类要实现的是Job接口,然后重写execute方法,方法中就是执行你具体要做的事情了。不过首先需要一个配置文件,里面定义了一些参数,是Quartz的一些配置。配置文件如下
Java代码

- #============================================================================
- # Configure Main Scheduler Properties
- #============================================================================
- org.quartz.scheduler.instanceName = QuartzScheduler
- org.quartz.scheduler.instanceId = AUTO
- #============================================================================
- # Configure ThreadPool
- #============================================================================
- org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
- org.quartz.threadPool.threadCount = 3
- org.quartz.threadPool.threadPriority = 5
- #===============================================================
- #Configure JobStore
- #===============================================================
- org.quartz.jobStore.misfireThreshold = 60000
- org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
- #============================================================================
- # Configure Plugins
- #============================================================================
- #org.quartz.plugin.triggHistory.class = org.quartz.plugins.history.LoggingJobHistoryPlugin
- org.quartz.plugin.jobInitializer.class = org.quartz.plugins.xml.JobInitializationPlugin
- org.quartz.plugin.jobInitializer.fileName = conf/quartz_jobs.xml
- org.quartz.plugin.jobInitializer.overWriteExistingJobs = true
- org.quartz.plugin.jobInitializer.failOnFileNotFound = true
- org.quartz.plugin.jobInitializer.scanInterval = 60
即使做成配置,这个类也必须要有,一定会有个Job类,专门做数据分析,有的朋友说配置文件搞定所有,不现实,
好了,这就是配置文件,接下来我们就要做这个计划类了,这个类执行的是去源数据库中查询数据,并插入目标数据库中,并且不允许有重复。代码如下
Java代码
- package com.bj58.job.servlet;
- import java.sql.Connection;
- import java.sql.PreparedStatement;
- import java.sql.ResultSet;
- import java.sql.SQLException;
- import org.apache.commons.logging.Log;
- import org.apache.commons.logging.LogFactory;
- import org.quartz.Job;
- import org.quartz.JobExecutionContext;
- import org.quartz.JobExecutionException;
- import com.bj58.job.utils.ConnectionFactory_DB_dest;
- import com.bj58.job.utils.ConnectionFactory_DB_src;
- /**
- * 定时任务类
- * @author zhangwan@58.com
- * Jun 8, 2010
- *
- */
- public class QuartzJob implements Job {
- private static final Log log = LogFactory.getLog(Job.class);
- private static final String findSql_src = "select PortalId from t_portalinfo";
- private static final String findSql_dest = "select userId from t_user";
- private static final String insertSql_dest = "insert into t_user(userId) values (?)";
- /**
- * 执行任务方法
- */
- @Override
- public void execute(JobExecutionContext context) throws JobExecutionException {
- Connection conn_db_src = ConnectionFactory_DB_src.getConnection();
- Connection conn_db_dest = ConnectionFactory_DB_dest.getConnection();
- PreparedStatement pstmt_src = null;
- PreparedStatement pstmt_dest = null;
- ResultSet rs_src = null;
- ResultSet rs_dest = null;
- try {
- pstmt_src = conn_db_src.prepareStatement(findSql_src);
- rs_src = pstmt_src.executeQuery();
- pstmt_dest = conn_db_dest.prepareStatement(findSql_dest);
- rs_dest = pstmt_dest.executeQuery();
- pstmt_dest = conn_db_dest.prepareStatement(insertSql_dest);
- while(rs_dest.next()) { //第二次或第n次入库,第一次入库的话rs_dest没有结果,所以此段操作都不执行
- String userId = rs_dest.getString(1);
- while (rs_src.next()) {
- String protalId = rs_src.getString(1);
- if(userId.equals(protalId)) { //如果两个结果相同,则不进行入库
- break;
- } else {
- pstmt_dest.setString(1, protalId);
- pstmt_dest.execute();
- }
- }
- }
- while (rs_src.next()) { //如果是第一次入库
- String protalId = rs_src.getString(1);
- pstmt_dest.setString(1, protalId);
- pstmt_dest.execute();
- }
- log.info("存储数据...");
- } catch (SQLException e) {
- log.info("存储数据出现异常...");
- e.printStackTrace();
- } finally {
- ConnectionFactory_DB_dest.free(rs_dest, pstmt_dest, conn_db_dest);
- ConnectionFactory_DB_src.free(rs_src, pstmt_src, conn_db_src);
- log.info("数据库连接已经关闭...");
- }
- }
- }
这里一次性查出了源数据库中所有字段,因为源数据库表中的数据最多不会超过10000条,我在做测试的时候,在本机上发现一次查询10W条也不会出现结果集溢出情况,所以这里就忽略这个问题了。
然后需要这么个配置文件quartz_jobs.xml,内容如下
Java代码
- <?xml version="1.0" encoding="UTF-8"?>
- <quartz>
- <job>
- <job-detail>
- <name>PortalInfoJob</name>
- <group>PortalInfo</group>
- <job-class>com.bj58.portalcrm.web.job.PortalInfoJob</job-class>
- </job-detail>
- <trigger>
- <cron>
- <name>PORTALINFO</name>
- <job-name>PortalInfoJob</job-name>
- <job-group>PortalInfo</job-group>
- <cron-expression>0 0 1 * * ?</cron-expression>
- </cron>
- </trigger>
- </job>
- </quartz>
ok,最后就是web.xml文件配置一下,Quartz提供了个初始化的Servlet,呵呵,内容如下
Java代码
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="2.4"
- xmlns="http://java.sun.com/xml/ns/j2ee"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
- http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
- <welcome-file-list>
- <welcome-file>index.jsp</welcome-file>
- </welcome-file-list>
- <!-- Quartz配置计划 -->
- <servlet>
- <servlet-name>QuartzInitializer</servlet-name>
- <servlet-class>org.quartz.ee.servlet.QuartzInitializerServlet</servlet-class>
- <load-on-startup>1</load-on-startup>
- <init-param>
- <param-name>config-file</param-name>
- <param-value>/quartz.properties</param-value>
- </init-param>
- <init-param>
- <param-name>shutdown-on-unload</param-name>
- <param-value>true</param-value>
- </init-param>
- </servlet>
- </web-app>
这样就搞定了,