更多深度文章,请关注:https://yq.aliyun.com/cloud
当15年前推出MapReduce时,它展示了整个世界对于未来的不屑一瞥。硅谷科技公司的工程师第一次可以分析整个互联网。然而,MapReduce提供了非常低级API,结果使这个“超级力量”成为了奢侈品,只有极少数的高学历的,有很多资源的工程师才可以使用它。
今天,深度学习已经达到了“MapReduce”当时的地位:它已经显示出了很大潜力,它是人工智能的“超级力量”。它的力量在过去的几年创造的价值很让人吃惊,例如:自动驾驶汽车和AlphaGo这些都被认为是奇迹。
然而,今天利用深度学习的超级力量与过去的大数据一样具有挑战性。深度学习框架由于低级API而具有陡峭的“学习曲线” ;扩展分布式硬件需要大量的人工工作; 即使是大量的时间和资源的结合,深度学习实现成功也需要繁琐的工作和实验参数。因此深度学习也通常被称为“黑魔法”。
七年前,我们开始了一个Spark项目,其目标是通过提供高级API和统一的引擎来实现机器学习,ETL,流式传输和交互式SQL,从而实现“大众化”大数据的“超级力量”的目标。今天,Apache Spark已经为软件工程师们及SQL分析师们都提供了大量数据。
继续这个民主化的愿景,我们很高兴地宣布深度学习管道,这是一个新的开源库,旨在使每个人都能轻松地将可扩展的深度学习整合到他们的工作流程中,使他们能从机器学习从业者过渡到商业分析师,真正的将技术应用于实际生活中。
深度学习管道基于Apache Spark的ML管道培训,并使用Spark DataFrames和SQL部署模型。它包括用于深度学习的常见的高级API,因此有些功能可以在几行代码中高效地完成,比如说:
· 图像加载(Image loading)
· 在Spark ML管道中应用预先训练的模型(Apply pre-trained models as transformers in a Spark ML pipeline)
· 迁移学习(Transfer learning)
· 分布式超参数调优(Distributed hyperparameter tuning)
· 在DataFrames和SQL中部署模型
接下来,我们通过实例详细描述这些功能。要在Databricks上尝试这些和更多的例子,请查看笔记本深度学习流水线在数据库中。
图像加载(Image loading)
在图像上应用深度学习的第一步是加载图像的能力。深度学习管道包括可以将数百万图像加载到DataFrame中的实用程序功能,并以分布式方式自动解码它们,从而允许进行大规模操作。
df = imageIO.readImages("/data/myimages")
我们还正在努力增加对更多数据类型的支持,如文本和时间序列。
应用可预测的预训练模型(Applying Pre-trained Models for Scalable Prediction)
深度学习管道支持以分布式的方式运行预训练的模型,可用于批量和流式数据处理。它包含了一些最受欢迎的模型,使用户在不需要花费昂贵的培训模型的前提下,能够直接开始深度学习。例如,以下代码使用InceptionV3创建一个Spark预测流水线,InceptionV3是用于图像分类的最先进的卷积神经网络(CNN)模型,并且预测了我们刚加载的图像中是什么样的对象。当然,这个预测是利用Spark一起完成的。
from sparkdl import readImages, DeepImagePredictor
predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3")
predictions_df = predictor.transform(df)除了使用已经创建好的模型,用户还可以在Spark预测管道中插Keras 模型和TensorFlow Graphs。这可以将单节点工具上的任何单节点模型转换成可以分布式应用在大量数据的单节点模型。
在数据库统一分析平台上,如果选择基于GPU的集群,计算密集型部分将自动运行在GPU上,以获得最佳效率。
迁移学习(Transfer learning)
预先训练的模型在适合手头任务时非常有用,但通常不会针对用户正在处理的特定数据集进行优化。例如,InceptionV3是针对广泛的1000个类别进行图像分类优化的模型,但我们的域可能是狗种分类。一种常用的深度学习技术是迁移学习,它使针对类似任务训练的模型适应于手头的任务。同从初级培训新模式相比,迁移学习需要大幅度的减少数据和资源。这就是为什么迁移学习已经成为许多现实世界的用例,如癌症检测方法。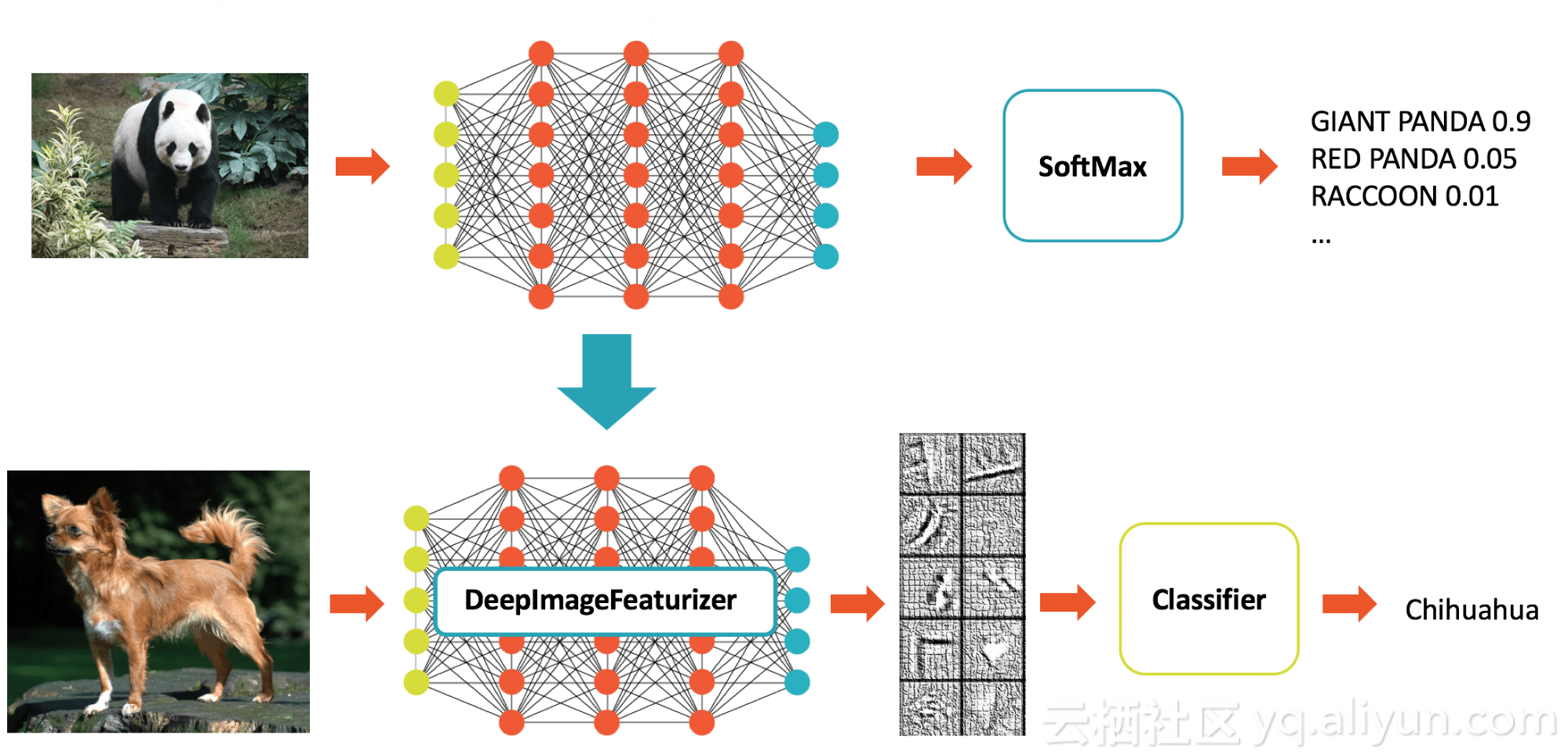
深度学习管道可以快速转移学习与Featurizer的概念。以下示例结合了Spark中的InceptionV3模型和逻辑回归,以将InceptionV3适配到我们的特定域。DeepImageFeaturizer自动剥离预先训练的神经网络的最后一层,并使用所有以前层的输出作为逻辑回归算法的特征。由于逻辑回归算法是一种简单而快速的算法,所以这种迁移学习训练可以快速收敛,而不需要通过培训远程学习模型所需的图像。
from sparkdl import DeepImageFeaturizer
from pyspark.ml.classification import LogisticRegression
featurizer = DeepImageFeaturizer(modelName="InceptionV3")
lr = LogisticRegression()
p = Pipeline(stages=[featurizer, lr])
# train_images_df = ... # load a dataset of images and labels
model = p.fit(train_images_df)分布式超参数调优(Distributed hyperparameter tuning)
在深度学习中获得最佳结果需要对培训参数进行不同的测试,这是一个超参数调优的重要步骤。由于深度学习管道可以将深度学习培训作为Spark的机器学习流程中的一步,因此用户可以依靠已经内置到Spark中的超参数调优基础架构。
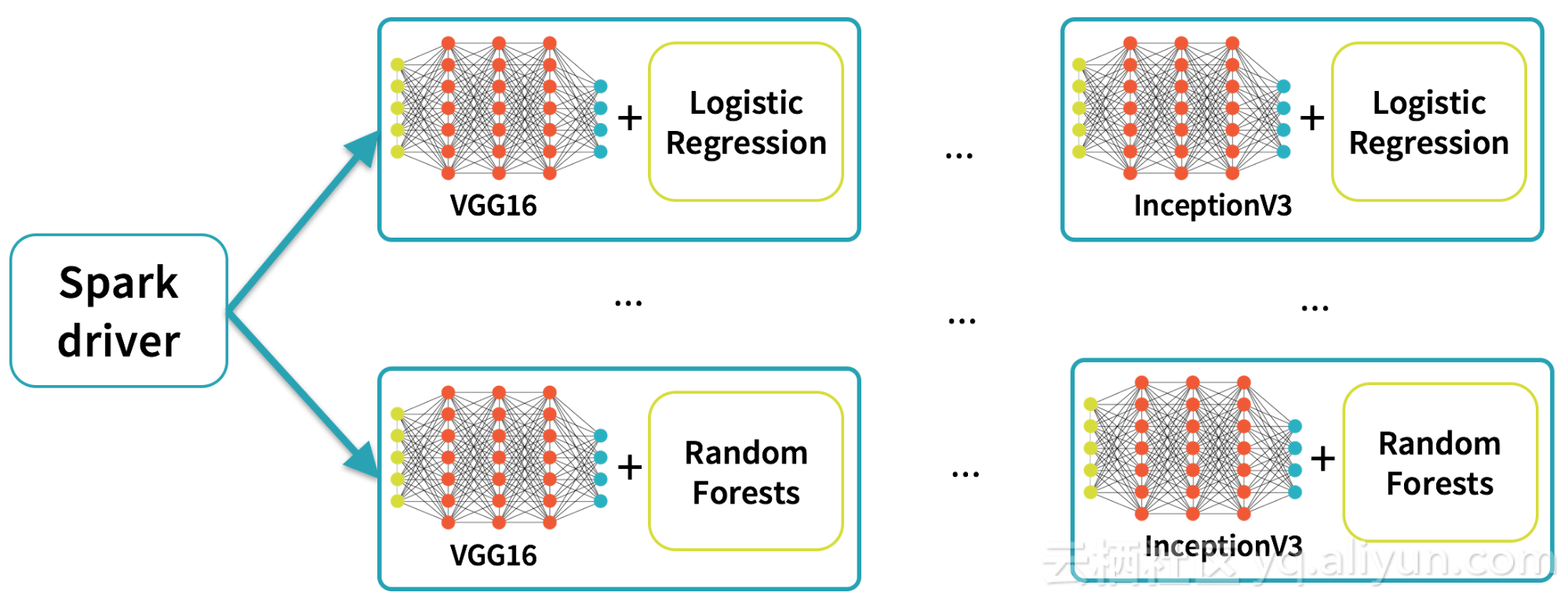
以下代码插入到Keras Estimator中,并使用具有交叉验证的网格搜索来执行超参数调整:
myEstimator = KerasImageFileEstimator(inputCol='input',
outputCol='output',
modelFile='/my_models/model.h5',
imageLoader=_loadProcessKeras)
kerasParams1 = {'batch_size':10, epochs:10}
kerasParams2 = {'batch_size':5, epochs:20}
myParamMaps =
ParamGridBuilder() \
.addGrid(myEstimator.kerasParams, [kerasParams1, kerasParams2]) \
.build()
cv = CrossValidator(myEstimator, myEvaluator, myParamMaps)
cvModel = cv.fit()
kerasTransformer = cvModel.bestModel # of type KerasTransformer在SQL中部署模型(Deploying Models in SQL)
一旦数据科学家建立了所需的模型,深度学习管道就可以将其作为SQL中的一个功能,所以组织中的任何人都可以使用它 - 数据工程师,数据科学家,业务分析师,任何人。
sparkdl.registerKerasUDF("img_classify", "/mymodels/dogmodel.h5")接下来,组织中的任何用户都可以在SQL中应用预测:
SELECT image, img_classify(image) label FROM images
WHERE contains(label, “Chihuahua”)所有支持的语言(Python,Scala,Java,R)中的DataFrame编程API中也提供了类似的功能。与可扩展预测类似,此功能可以在批量和结构化流中使用。
结论:
在这篇博文中,我们介绍了深层学习管道,这是一个新的图书馆,使深度学习更加容易使用和扩展。虽然这只是一个开始,我们认为深度学习管道有潜力完成Spark所完成的工作:使深度学习的“超级力量”对每个人都是触手可得的。
系列中的未来帖子将更详细地介绍图书馆中的各种工具,比如说:大规模的图像处理,迁移学习,大规模预测,以及在SQL中进行深度学习。
要了解有关该库的更多信息,请查看Databricks笔记本以及github仓库。我们希望您能给我们反馈。或者,作为贡献者,并帮助将可扩展的深度学习的超级力量带给每个人。
超级福利:免费试用DATABRICKS
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《A Vision for Making Deep Learning Simple From Machine Learning Practitioners to Business Analysts》,
作者: ,译者:袁虎,审阅:我是主题曲哥哥
文章为简译,更为详细的内容,请查看原文





