阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
倚天使用|YODA倚天应用迁移神器,让跨架构应用迁移变得简单高效
YODA(Yitian Optimal Development Assistant,倚天应用迁移工具)旨在帮助用户更加高效、便捷地实现跨平台、跨结构下的应用迁移,大幅度缩短客户在新平台上端到端性能验
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。
ECS实例选型最佳实践
本课程主要讲解在客户明确自身业务功能、性能、稳定性需求,以及成本成本约束后去了解各规格族/规格特性,匹配自身需求选择所需服务器类型。实例规格选型最佳实践,就是为了帮助用户结合自身业务需求中性能、价格、

创建to do list应用教程
阿里云讲师手把手带你部署to do list,本实验支持使用 个人账号资源 或 领取免费试用额度 进行操作,建议优先选用通过已领取的云工开物高校计划学生300元优惠券购买个人账号资源的方案,如您具备免
conda数据源在昨天失效返回404,当前依赖的包无法安装和使用
问题描述conda数据源在失效返回404当前依赖的包无法安装和使用失效的镜像通道地址conda-forge: http://mirrors.aliyun.com/anaconda/cloud
阿里云百炼大模型产品实践
日志服务 HarmonyOS NEXT 日志采集最佳实践
鸿蒙操作系统(HarmonyOS)上的日志服务(SLS)SDK 提供了针对 IoT、移动端到服务端的全场景日志采集、处理和分析能力,旨在满足万物互联时代下应用的多元化设备接入、高效协同和安全可靠运行的
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

阿里云产品手册2024版
阿里云作为数字经济的重要建设者,不断加深硬核科技实力,通过自身能力助力客户实现高质量发展,共创数字新世界。阿里云产品手册 2024 版含产品大图、关于阿里云、引言、安全合规等内容,覆盖人工智能与机器学

加载ModelScope模型以后,为什么调用,model.chat()会提示错误?
加载ModelScope模型以后为什么调用model.chat()会提示错误AttributeError: Qwen2ForCausalLM object has no attribute chat
Doodle Jump — 使用Flutter&Flame开发游戏真不错!
用Flutter&Flame开发游戏是一种什么体验?最近网上冲浪的时候,我偶然发现了一个国外的游戏网站,类似于国内的4399。在浏览时,我遇到了一款经典的小游戏:Doodle Jump...

深入探究Java微服务架构:Spring Cloud概论
**摘要:** 本文深入探讨了Java微服务架构中的Spring Cloud,解释了微服务架构如何解决传统单体架构的局限性,如松耦合、独立部署、可伸缩性和容错性。Spring Cloud作为一个基于

访问控制(RAM)|云上安全使用AccessKey的最佳实践
集中管控AK/SK的生命周期,可以极大降低AK/SK管理和使用成本,同时通过加密和轮转的方式,保证AK/SK的安全使用,本次分享为您介绍产品原理,以及具体的使用步骤。
Higress 全新 Wasm 运行时,性能大幅提升
本文介绍 Higress 将 Wasm 插件的运行时从 V8 切换到 WebAssembly Micro Runtime (WAMR) 的最新进展。


【活动推荐】Alibaba Cloud Linux实践操作学习赛,有电子证书及丰厚奖品!
参与开放原子基金会的[龙蜥社区Alibaba Cloud Linux实践操作学习赛](https://competition.atomgit.com/competitionInfo),获取电子证书。报

云效流水线智能排查功能实测:AI赋能DevOps,精准定位与高效修复实战评测
云效持续集成流水线Flow是阿里云提供的企业级CICD工具,免费且注册即用。它具备高可用性、免运维、深度集成阿里云服务、多样化发布策略及丰富的企业级特性。产品亮点包括智能排查功能,能快速定位问题,提高
阿里云高级技术专家李鹏:AI基础设施的演进与挑战 | GenAICon 2024
阿里云高级技术专家、阿里云异构计算AI推理团队负责人李鹏将在主会场第二日上午的AI Infra专场带来演讲,主题为《AI基础设施的演进与挑战》。
第十三期乘风伯乐奖--寻找百位乘风者伯乐,邀请新博主入驻即可获奖
乘风伯乐奖,面向阿里云开发者社区已入驻乘风者计划的博主(技术/星级/专家),邀请用户入驻乘风者计划即可获得乘风者定制周边等实物奖励。本期面向阿里云开发者社区寻找100位乘风伯乐,邀请人数月度TOP 1


开源开发者沙龙北京站 | 微服务安全零信任架构
讲师/嘉宾简介 刘军(陆龟)|Apache Member 江河清(远云)|Apache Dubbo PMC 孙玉梅(玉梅)|阿里云技术专家 季敏(清铭)|Higress Maintainer 丁双喜(

MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。

RocketMQ 之 IoT 消息解析:物联网需要什么样的消息技术?
RocketMQ 5.0 是为应对物联网(IoT)场景而发布的云原生消息中间件,旨在解决 IoT 中大规模设备连接、数据处理和边缘计算的需求。
在Redhat 9部署nginx服务
Nginx是一个高性能、开源的HTTP和反向代理服务器,以其异步非阻塞模型处理高并发,并具有轻量级、高可靠性、良好扩展性和热部署特性。在Redhat 9.2上安装nginx-1.24.0涉及安装依赖、

文件上传漏洞技术总结
该文总结了文件上传技术相关的漏洞和绕过方法,包括语言可解析的后缀(如phtml、pht)、常见的MIME类型、Windows特性(如大小写、ADS流、特殊字符)、0x00截断技巧(需满足PHP版本和m
基于深度学习的停车场车辆检测算法matlab仿真
该文介绍了使用GoogLeNet进行停车场车辆检测的算法,基于深度学习的CNN模型,利用Inception模块提升检测效率。在matlab2022a中实现,通过滑动窗口和二分类交叉熵损失函数优化。文章
基于阿里云向量检索 Milvus 版与 PAI 搭建高效的检索增强生成(RAG)系统
阿里云向量检索 Milvus 版现已无缝集成于阿里云 PAI 平台,一站式赋能用户构建高性能的检索增强生成(RAG)系统。您可以利用 Milvus 作为向量数据的实时存储与检索核心,高效结合 PAI
Java语言开发的AI智慧导诊系统源码springboot+redis 3D互联网智导诊系统源码
智慧导诊解决盲目就诊问题,减轻分诊工作压力。降低挂错号比例,优化就诊流程,有效提高线上线下医疗机构接诊效率。可通过人体画像选择症状部位,了解对应病症信息和推荐就医科室。
一套java+ spring boot与vue+ mysql技术开发的UWB高精度工厂人员定位全套系统源码有应用案例
UWB (ULTRA WIDE BAND, UWB) 技术是一种无线载波通讯技术,它不采用正弦载波,而是利用纳秒级的非正弦波窄脉冲传输数据,因此其所占的频谱范围很宽。一套UWB精确定位系统,最高定位精

一文读懂:大模型RAG(检索增强生成)
RAG(检索增强生成)旨在弥补大模型知识局限性、幻觉问题和数据安全性的不足。它通过向量搜索从私域数据库中检索相关信息,结合问题生成提示,使模型能提供准确答案。
还在为字典值、枚举值校验烦恼吗,不妨试试这个
本文介绍了如何在Java中实现常量值校验的封装,主要包括两个方面:字典值类型的校验和枚举类型的校验。首先,作者提到在进行数据验证时,实体类字段需要添加`@Valid`注解。然后,对于字典值类型的校验,
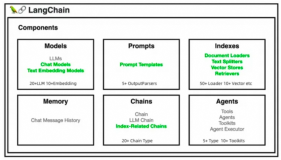
深入浅出LangChain与智能Agent:构建下一代AI助手
LangChain为大型语言模型提供了一种全新的搭建和集成方式,通过这个强大的框架,我们可以将复杂的技术任务简化,让创意和创新更加易于实现。本文从LangChain是什么到LangChain的实际案例