摘要:在云栖社区主办的云栖计算之旅第5期–大数据与人工智能分享中,阿里云计算平台高级专家薛明为大家深入地介绍了阿里云大数据IDE–MaxCompute Studio,并对于其特性和背后的技术思想进行了讲解。
本文根据演讲视频整理而成。
本次将与大家深入地分享阿里云数加平台的大数据开发套件——MaxCompute Studio。其实对于开发者而言,在大数据开发、数据处理以及管理作业时经常会使用到IDE,而在阿里巴巴内部也有上万名大数据开发者,他们也会使用数加平台,也就是阿里巴巴统一的计算引擎——MaxCompute,在MaxCompute之上其实存在一个统一的数据仓库,这个数据仓库中包含了阿里巴巴全部的数据,各个事业部都可以利用数加平台进行大数据应用的开发。而MaxCompute Studio就是针对于MaxCompute的大数据开发套件。
我们为什么需要Data IDE
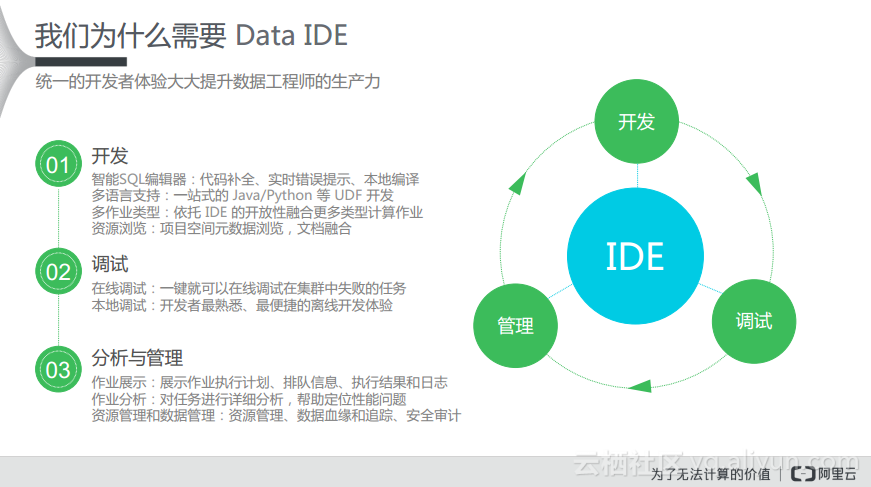
如同编写Java或者其他语言的程序一样,开发者一开始可能会使用文本编辑工具来编写程序,但是随着需要处理的任务变得越来越复杂,就可能会需要使用IDE。同样在数据发展到足够复杂的时候,需要处理的数据也变得非常多,这些数据往往需要用不同的模式进行处理,所以在进行数据处理时往往需要这样的IDE去帮助开发者完成工作。在整个数据平台里可能会存在数据的采集和传输过程,但是对于开发者而言,在真正在线上进行数据处理的时候,可能需要一些使用工具把数据漏到开发环境中,然后在本地进行做工作来验证数据处理逻辑,这样就可以实现在真正的计算环境和数据仓库中进行验证。除此之外,当作业出现问题的时候也需要有足够好的工具进行分析和管理。这些其实都是对于开发者而言需要面对的问题,所以阿里云也希望通过统一的开发工具或者IDE环境来解决上述的问题。
大数据开发套件:MaxCompute Studio
本次分享将为大家介绍目前阿里云在大数据开发中使用的一种工具——MaxCompute Studio,这个工具是面向MaxCompute计算引擎开发的数据处理开发工具,但是目前还不能够覆盖像实时处理以及ADS这些其他的计算引擎,现在只支持离线计算这部分,但是之后或许能够推广到更大的范畴中。
今天的分享将主要围绕以下三个方面为大家介绍大数据开发套件MaxCompute Studio的几个特点以及其背后的实现技术。

智能编辑器背后的编译器支持
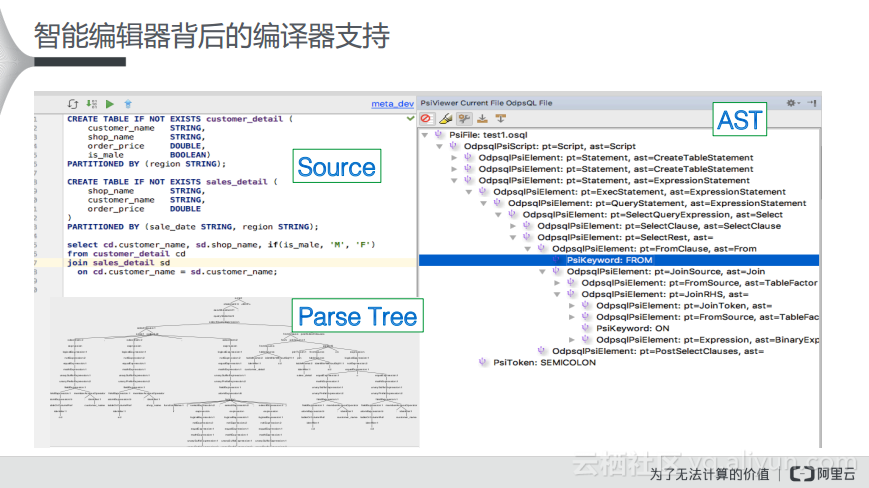
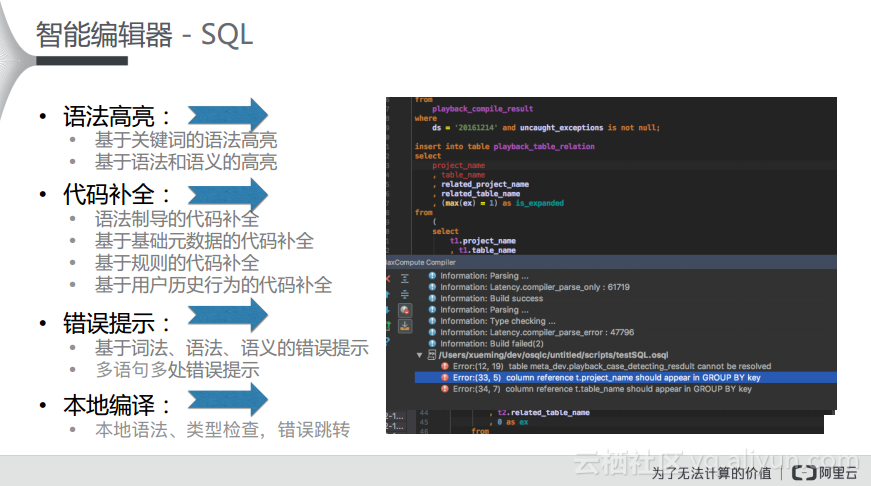
接下来分享一下做智能编辑器这件事情的背景以及其背后所使用的技术。选择在本地实现IDE其实有一个非常大的技术优势,就是本地其实具有比较强大的计算资源。而IDE对于SQL代码在本地其实是进行了预编译的,这样就将源代码转化成了语法分析树,在语法分析树之上可以抽象出逻辑的处理单元AST。之后就可以根据抽象语法树进行语法的判断,可以通过语法分析树进行类型检查。而又因为在建立了树型结构之后就可以方便地对于树进行多次遍历,所以可以通过类型检查发现语法中的错误。
所以目前就是在本地的后台就做了这样的几件事情:首先通过语法分析器和词法分析器生成了语法分析树,然后通过上下文无关文法也就是在MaxCompute中对于SQL定义的语法和扩展可以很方便地在IDE里面提供语言的新特性,比如在SQL里面要增加if-else或者loop这样语法其实只需要去更新上下文无关文法就可以了,这样就可以生成出所需要的后台表示,然后再进行相应的处理。
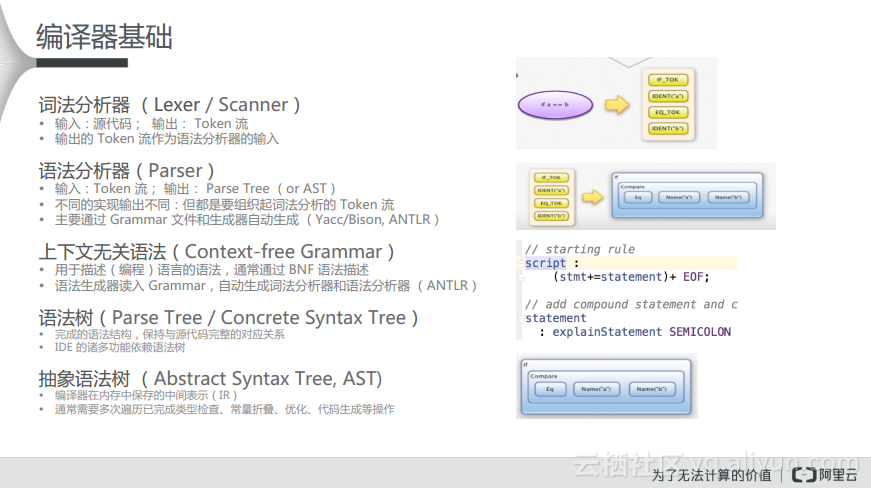
对于具体问题而言,比如要实现刚才提到的语法高亮就需要考虑这样的几个层次,最简单的就是目前任何一个SQL都可以支持的关键词的词法高亮,但是在MaxCompute Studio中会更进一步。其实实现关键词的语法高亮很简单,只需要断出Token就可以了,但是还需要实现基于Parse Tree的语法高亮,再往后就需要实现基于AST的类型检查的语法高亮,比如图中的if是一个函数,其参数需要字符串的类型,那么此时就需要后台的抽象语法树进行判断是不是这个类型并标注相应的颜色。

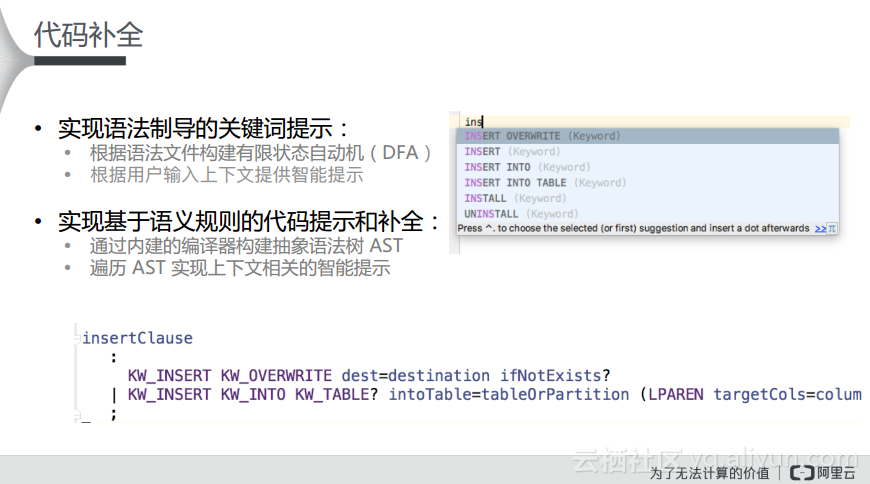
在此基础之上,MaxCompute Studio还实现了很多更好用的特性,比如开发者写出关键词之后IDE就能提示和补全,而且实际上这个功能还可以做的更加智能,可以根据语法文件构建有限状态自动机并根据用户输入的上下文提供智能提示。因为IDE的后台存在语法树所以就可能判断出用户所输入的上下文是什么,而这并不任何一个编辑器都能做到的,只有真正懂文法的编辑器才能够做到。
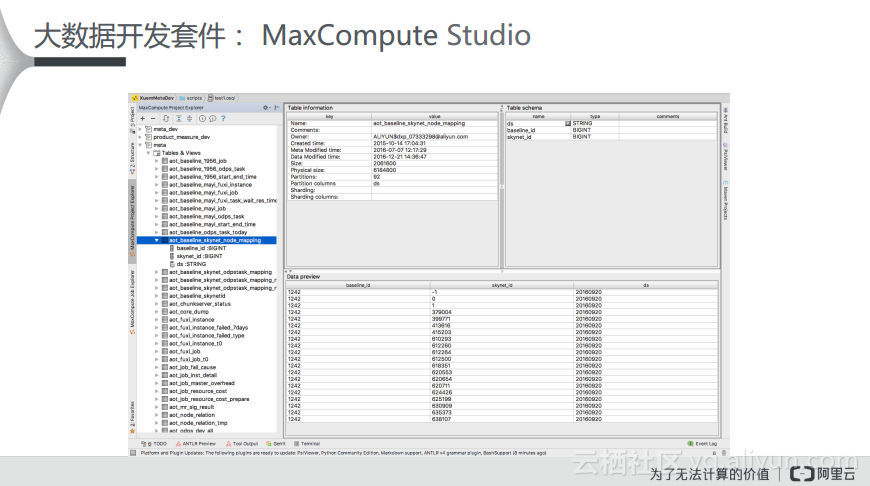
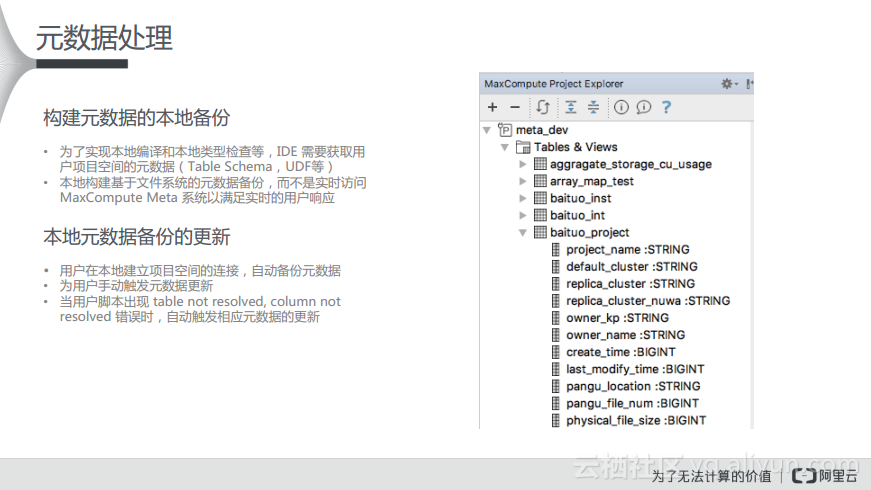
刚才也提到了要对元数据进行处理,而在阿里巴巴会有一个整体的元数据仓库去管理全部的元数据。如下图所示一个项目中会有数千个project,每个project里面都会有自己的table和scheme。在本地其实可以通过缓存知道你所关心的project的元数据是什么样的,这样就可以根据元数据为编辑器提供智能化支持。
当然这里往往就会存在元数据更新的问题,比如开发者下载了一个本地的备份,而其他的同学更新、创建或者删除了一个表,那么已经下载的元数据如何进行更新呢?其实MaxCompute Studio也提供了几个机制进行更新,当开发者自己意识到自己的数据不是很新了,那么就可以进行手工地更新元数据,但是这样也无法保证本地的元数据是完全正确的,当进行编辑的时候IDE会进行语法检查,会去检查表格存不存在以及列的类型是否匹配,当出现问题的时候,IDE会自动地去服务器端将期望的元数据进行更新,可能错误开始时提示表格不存在,但是当拿到元数据之后这个错误可能就没有了。其实这样的错误在开发其他程序时也会用到,比方在开发Java程序时会引用第三方的库,而第三方库可能本身并没有下载,所以会出现某个类找不到的问题,但是当配置了Maven等库管理之后就可以自动地去做更新,这样就由原来有错变成没错了。
MaxCompute调试器

接下来分享在MaxCompute Studio中可以实现的调试器。当出现了任务失败的情况下,可以在IDE中看到失败的任务,然后进行DeBug,这时候在后台其实会在真正的计算集群上面重启了错误的节点,并对于出现错误的节点进行断点监听,然后在IDE中发起DeBug的会话,并通过IDE端口进行与服务器端的连接,并在服务器端重新运行出现错误的代码片,在这个地方利用IDE本身的调试器检查代码的逻辑并进行单步跟踪。其实在真正进行本地开发时会发现这是一个非常重要的问题,就是在本地运行时无错误,但是在服务器端运行数据时出现了错误,这时候开发者往往会非常头疼,因为可能是环境的问题或者是出现了脏数据等造成的影响,而通过IDE就可以很方便地对于问题进行定位。
对于调试器的方案设计可能就有以下的几种了。其实可以下载VM到本地,将计算节点复制一份就可以反复运行任务,或者在本地模拟一个计算环境,但是这些都不是非常完美的解决方案,都有缺点存在。可能需要下载非常庞大的环境,比如像阿里的计算节点往往有非常庞大的运行环境,所以不会很容易就下载下来。而本地运行可以做非常简单的计算环境,但是往往却和服务器端不完全一样,也无法完全复现这个问题,所以选用了Remote Attach,当出现问题的时候可以与服务器端进行Attach。

要实现上述的功能其实可以将IDE与服务器端的DeBug连接,因为计算节点要想启动一个进程可能需要拉起的服务,所以可以与服务器端进行通信进行连接。但是要想真正地去部署时往往会出现很大的问题,因为本地和服务器端网络往往不是联通的,并且还存在安全认证的问题。为了解决安全认证连接的问题,可以现在服务器端进行安全的认证,然后通过中间的Proxy对于请求进行连接。
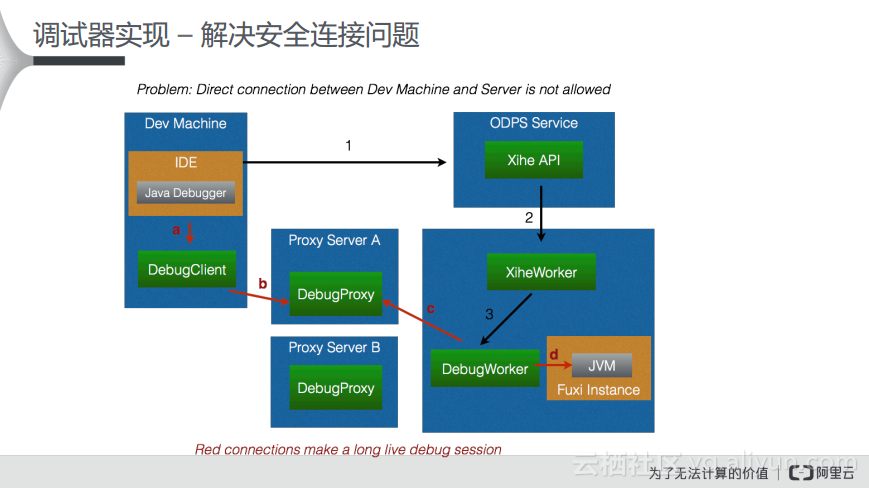 所以这样就解决了在分布式中如何在上万台机器的集群中重启UDF的JVM的环境,因为可能有数据处理的中间文件,如何将这些保存起来,以及如何支持多个用户DeBug的Proxy的扩展也是实现上的难点问题。
所以这样就解决了在分布式中如何在上万台机器的集群中重启UDF的JVM的环境,因为可能有数据处理的中间文件,如何将这些保存起来,以及如何支持多个用户DeBug的Proxy的扩展也是实现上的难点问题。

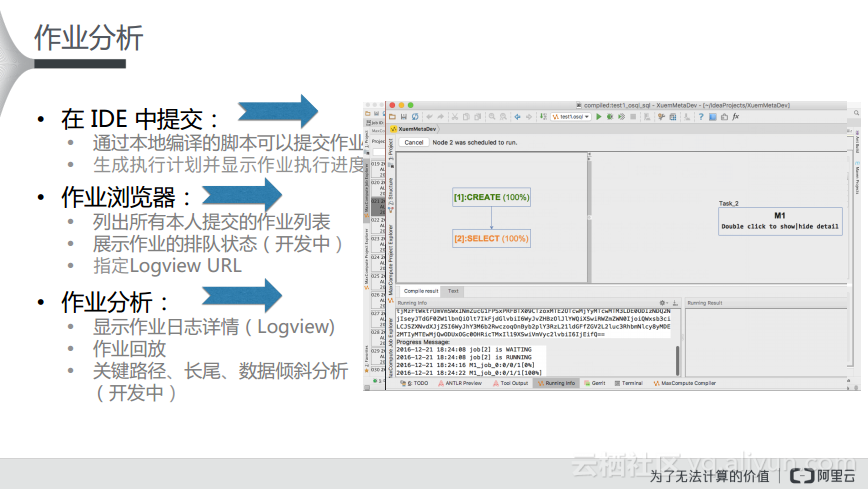
同样在IDE里面因为有元数据,所以可以与服务器端进行连接,可以看表格或者函数的详细信息,这样在开发时就可以轻松地获取所拥有的数据信息,如果没有数据还可以集成阿里MaxCompute数据导入工具对于数据进行导入。还有一种情况就是作业提交完成之后可以展示一个脚本中多条语句的详细执行计划,这样就可以帮助开发者了解脚本中的语句在服务器端究竟执行了几步,每步都可以看到执行的过程,每一步的输入是什么、输出是什么,可以发现究竟哪一步出现了数据倾斜。并且执行完成的作业都可以被列出来,这样就可以看到作业的执行状态以及详细信息。在作业的详细信息中可以看到该作业完整的执行计划以及作业的回放,回放就是无论作业执行成功还是失败都可以以短暂的时间重新回放一遍,这样就可以帮助开发者发现作业中哪一个是瓶颈。而MaxCompute Studio在未来也会在作业分析部分提供更加丰富的功能,比如检测数据作业的关键路径或者对于历史作业的对比,以此来快速地定位问题。
本文根据演讲视频整理而成。
本次将与大家深入地分享阿里云数加平台的大数据开发套件——MaxCompute Studio。其实对于开发者而言,在大数据开发、数据处理以及管理作业时经常会使用到IDE,而在阿里巴巴内部也有上万名大数据开发者,他们也会使用数加平台,也就是阿里巴巴统一的计算引擎——MaxCompute,在MaxCompute之上其实存在一个统一的数据仓库,这个数据仓库中包含了阿里巴巴全部的数据,各个事业部都可以利用数加平台进行大数据应用的开发。而MaxCompute Studio就是针对于MaxCompute的大数据开发套件。
我们为什么需要Data IDE
大数据开发套件:MaxCompute Studio
本次分享将为大家介绍目前阿里云在大数据开发中使用的一种工具——MaxCompute Studio,这个工具是面向MaxCompute计算引擎开发的数据处理开发工具,但是目前还不能够覆盖像实时处理以及ADS这些其他的计算引擎,现在只支持离线计算这部分,但是之后或许能够推广到更大的范畴中。
今天的分享将主要围绕以下三个方面为大家介绍大数据开发套件MaxCompute Studio的几个特点以及其背后的实现技术。
- 智能编辑器,本质上而言MaxCompute Studio是一个IDE,如同在编写C++或者Java程序时需要用到IDE一样,编写离线数据处理中常用的SQL以及Hive也需要一个智能编辑器,MaxCompute Studio是基于MaxCompute 2.0新一代引擎的编译器,可以提供上下文相关的代码补全、实时错误提示以及本地编译。
- 调试器,当代码出现问题时,开发者可以通过MaxCompute Studio进行远程的调试和处理。MaxCompute Studio可以建立IDE与远程计算集群的安全调试通道,并提供一键触发调试在集群中失败的任务的功能。
- 作业分析,MaxCompute Studio除了可以帮助开发者进行调试外,还可以进行相关的问题分析,也可以为开发者提供一些相关视图和分析工具,可视化地展现数据作业的执行计划,通过快速回放、关键路径分析等帮助用户定位性能问题。
智能编辑器-SQL
智能编辑器背后的编译器支持
所以目前就是在本地的后台就做了这样的几件事情:首先通过语法分析器和词法分析器生成了语法分析树,然后通过上下文无关文法也就是在MaxCompute中对于SQL定义的语法和扩展可以很方便地在IDE里面提供语言的新特性,比如在SQL里面要增加if-else或者loop这样语法其实只需要去更新上下文无关文法就可以了,这样就可以生成出所需要的后台表示,然后再进行相应的处理。
MaxCompute调试器
对于调试器的方案设计可能就有以下的几种了。其实可以下载VM到本地,将计算节点复制一份就可以反复运行任务,或者在本地模拟一个计算环境,但是这些都不是非常完美的解决方案,都有缺点存在。可能需要下载非常庞大的环境,比如像阿里的计算节点往往有非常庞大的运行环境,所以不会很容易就下载下来。而本地运行可以做非常简单的计算环境,但是往往却和服务器端不完全一样,也无法完全复现这个问题,所以选用了Remote Attach,当出现问题的时候可以与服务器端进行Attach。
回顾今天所分享的内容,实际上阿里巴巴在统一的数据平台之上就会存在非常集中的数据开发需求,要想满足这样的需求就需要完善的工具来支持,这其实非常符合数加理念:在数据强大引擎之上需要能够真正发挥作用的工具。MaxCompute Studio就是面向大数据开发者的工具,它能够覆盖大数据开发中的开发、测试调试以及作业管理整个闭环。在编辑器上可以浏览元数据,并给出智能的语法提示,当出现问题时可以像开发Java程序为开发者从线上下载样例数据来提交SQL验证逻辑,当作业出现问题可以使用可视化的方式观察执行计划,并通过快速回放去定位问题,这样就使得在统一的数据平台上进行快速开发成为可能,同时因为存在集成的开发环境就可以在上面方便地扩展数据的应用,可以在数加平台上实现自己的数据调度和数据监测功能,还可以通过IDE对于开源资产进行管理或者迁移。
欢迎加入钉钉群与大数据专家一起交流