热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
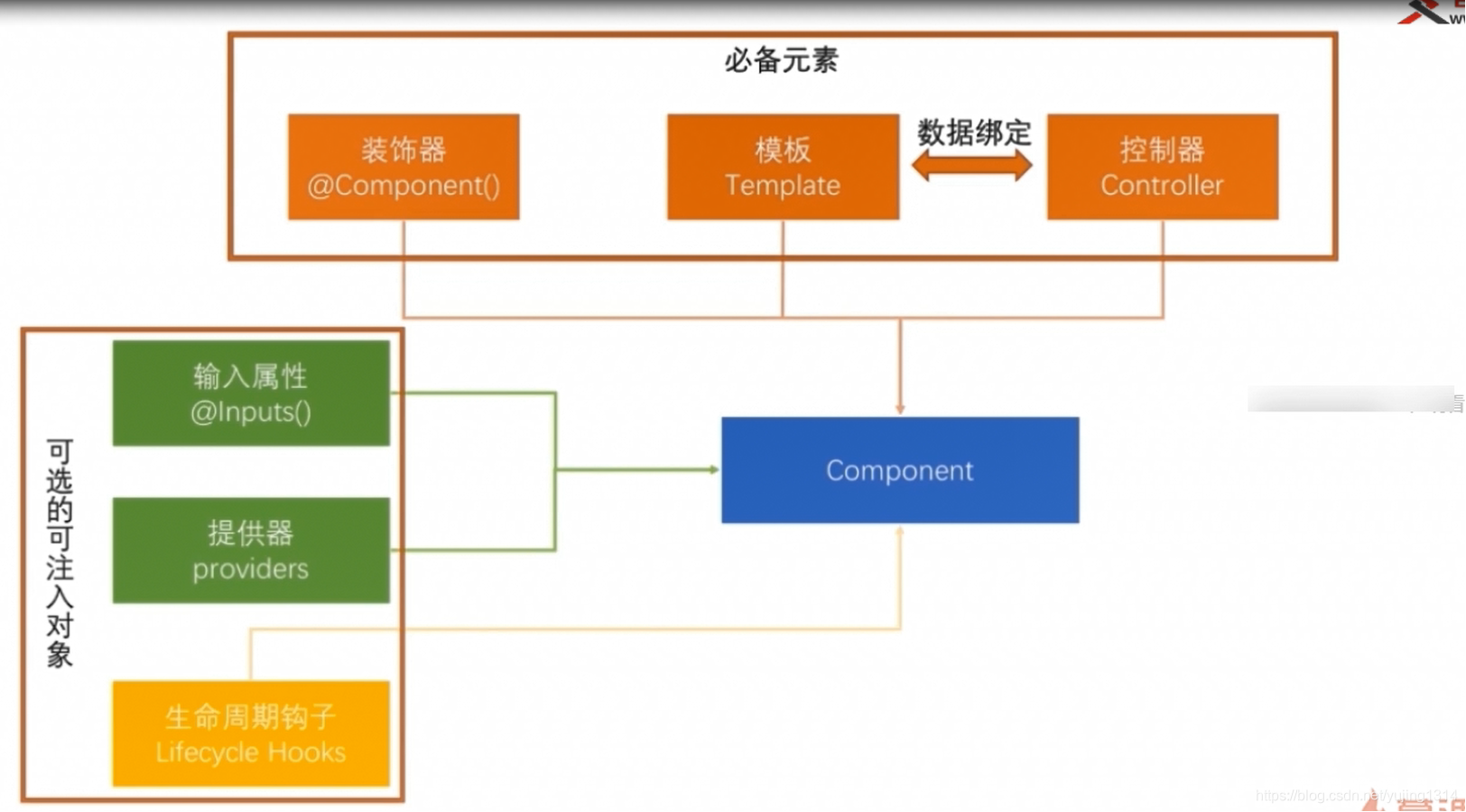
【angular】启动项目和路由配置
Mysql的NULLIF
java使用jodd操作html
suno-api
dromara-newcar
操作系统复习要点
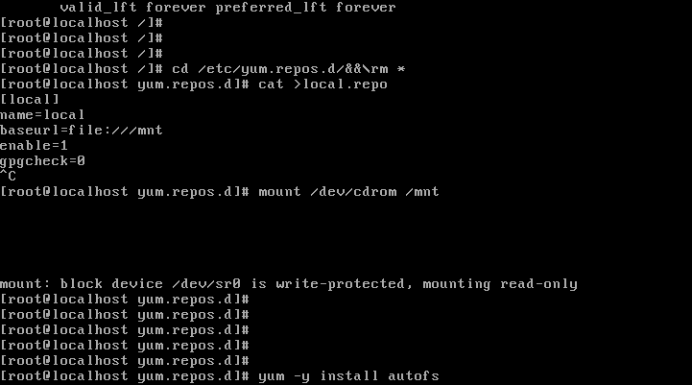
Centos6.5安装配置autofs服务
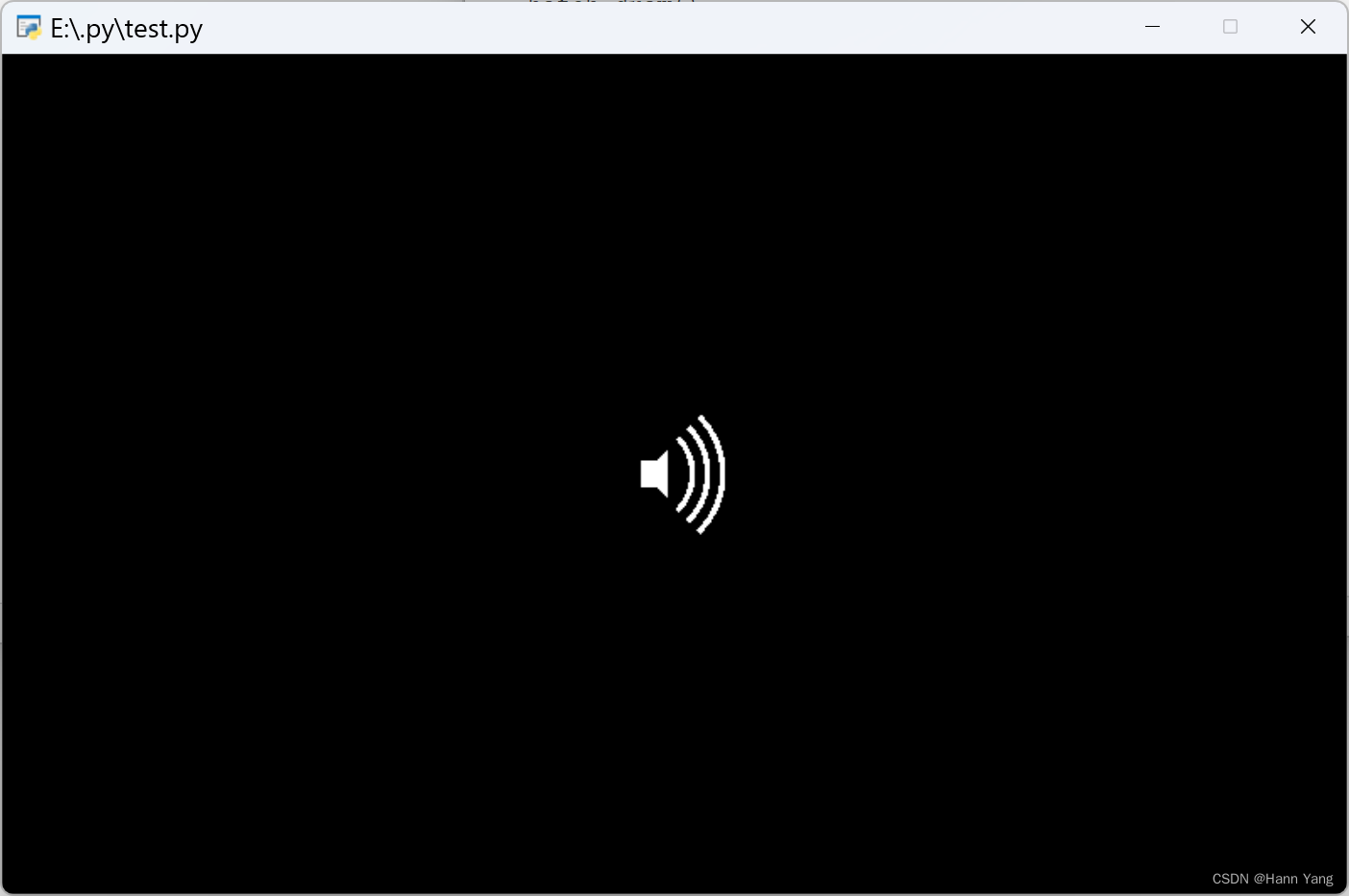
Python 一步一步教你用pyglet制作可播放音乐的扬声器类
Centos6.5安装并配置samba服务
Visual Studio Code 直接启动项目
octokit.js
mybatis判断批量操作是否全部执行成功
github获取uid方式
android-agent-web中js-bridge案例
mybatis-plus使用oceanbase-oracle模式
mybatis-plus启动时自动执行sql脚本
如何在服务器发布网站
Pandas DataFrame 基本操作实例100个
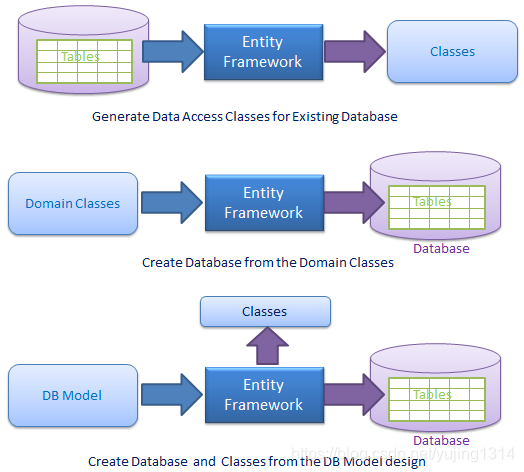
EF学习和使用(一)(Model First为例)
Linux系统常用命令大全
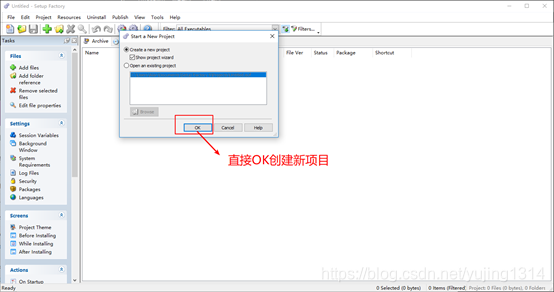
Setup Factory 怎样让打包的程序在安装后自动运行
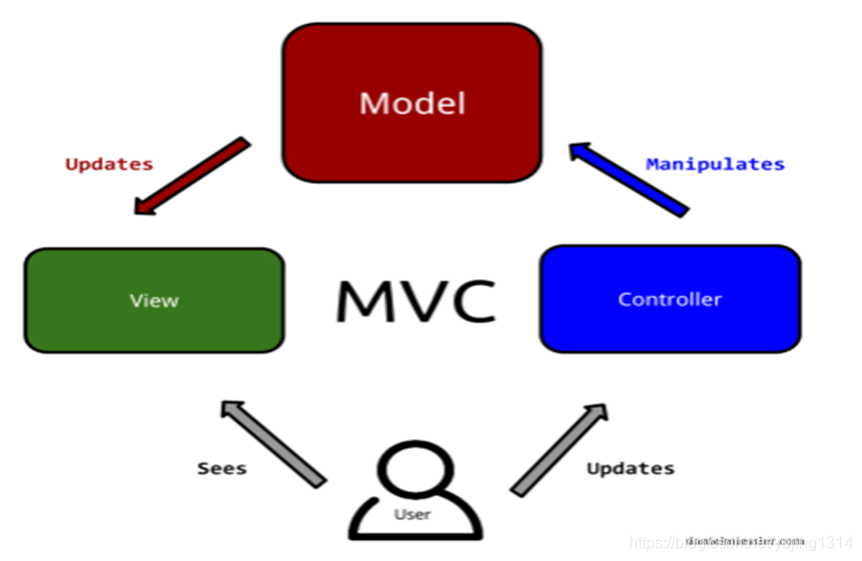
深入浅出MVC
Centos6.5管理与ROOT密码重置
Centos7安装mariadb数据库
PostCSS: Revolutionizing Modern Web Development
代码规范(一)
Pyglet图形界面版2048游戏——详尽实现教程(上)
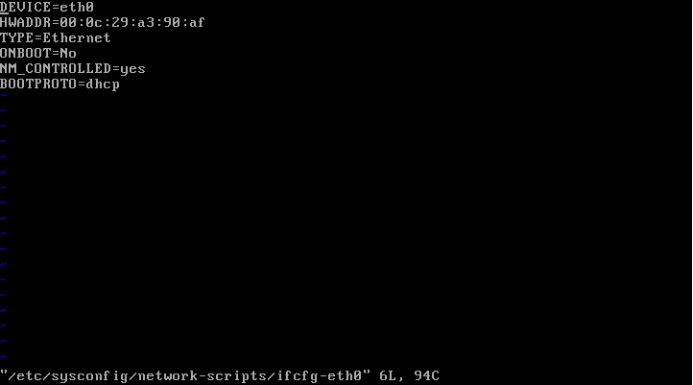
Centos6.5配置网络适配器
《SQL必知必会》读后感(一)
Java中的多线程编程:基础知识与实践
【JavaScript】计时器
Java中的多线程技术实现与应用
常用SQL查询方法与实例
python|闲谈2048小游戏和数组的旋转及翻转和转置
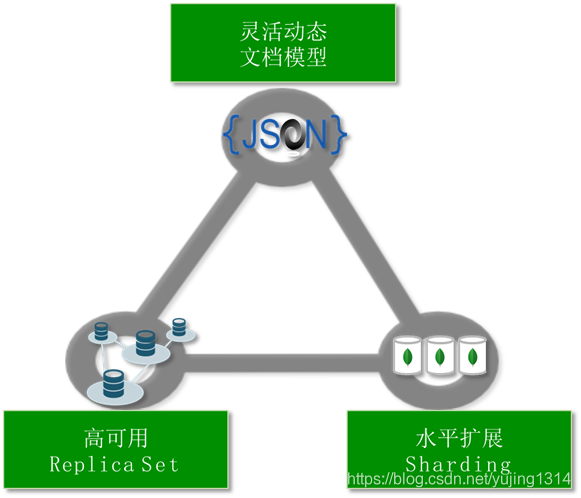
MongoDB的简介和安装(在服务器上)
ECS使用体验
JavaScrip基础(三)
阿里云ECS的使用心得
计算思维学习总结(一)
JavaScrip基础(二)
setup facatory9.0打包详细教程(含静默安装和卸载)
python 和shell 变量互相传递
VulnHub 靶场--super-Mario-Host超级马里奥主机渗透测试过程
基于Vulnhub—DC8靶场渗透测试过程
MySQL字段的时间类型该如何选择?千万数据下性能提升10%~30%🚀
外贸企业邮箱解析:通向全球市场的邮件之路