热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
Oracle存储过程与自定义函数的调用:异同与实战场景
Oracle创建函数:数据王国的“魔法秘籍”
Oracle存储过程:数据王国的魔法师
Oracle的PL/SQL游标自定义异常:数据探险家的“专属警示灯”
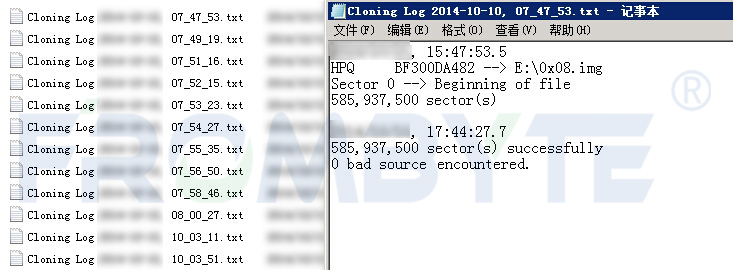
EVA数据恢复—EVA存储中磁盘掉线导致LUN不可用的数据恢复案例
软件体系结构 - 性能指标
Oracle的PL/SQL游标异常处理:从“惊涛骇浪”到“风平浪静”
Oracle的PL/SQL异常处理方法:守护数据之旅的“魔法盾”
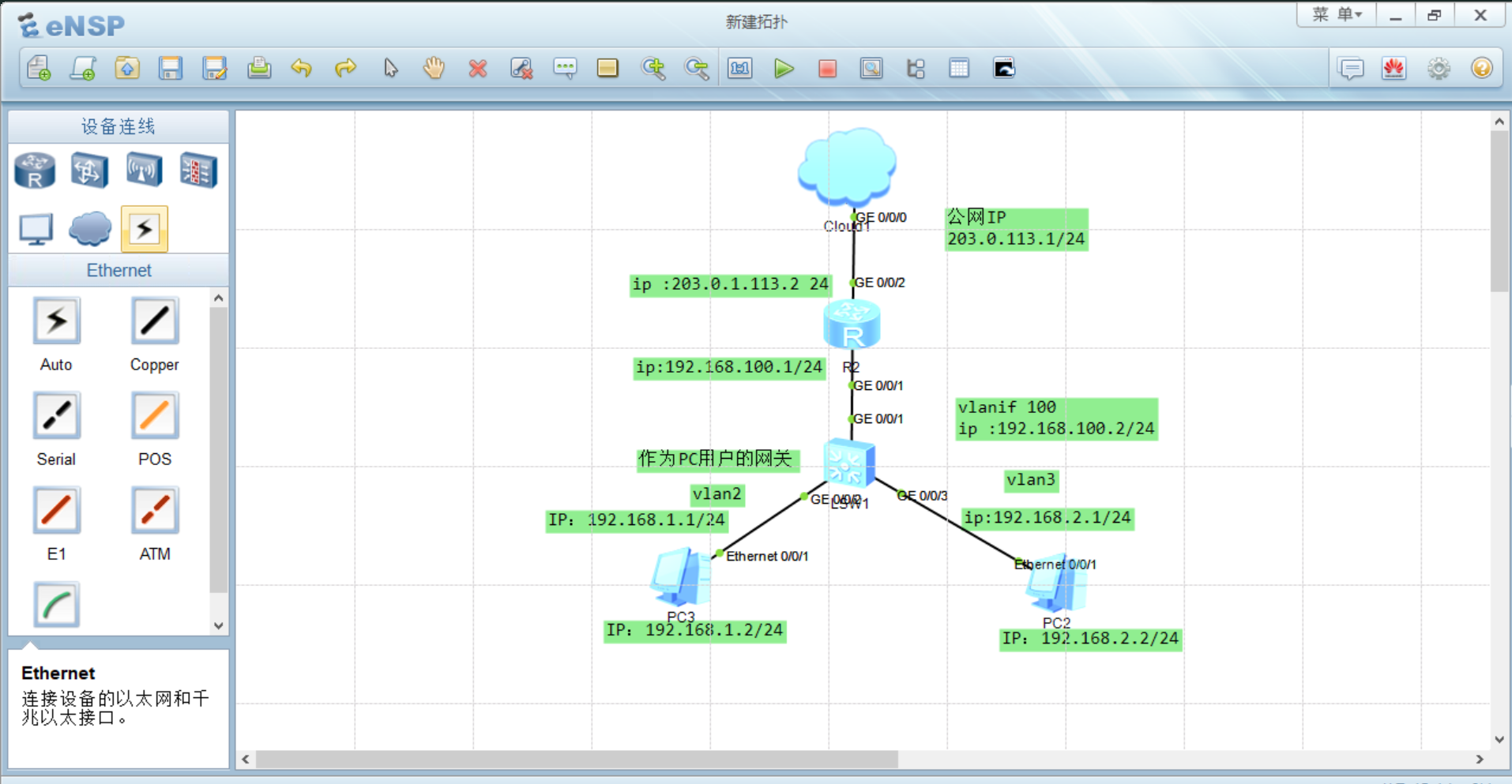
三层交换机对接路由器配置上网实验
Oracle的PL/SQL中FOR语句循环游标的奇幻之旅
Oracle的PL/SQL游标属性:数据的“导航仪”与“仪表盘”
Spring Cloud 常用各个组件详解及实现原理(附加源码+实现逻辑图)
C# HL7消息体
C# 接口
C# 循环遍历使用
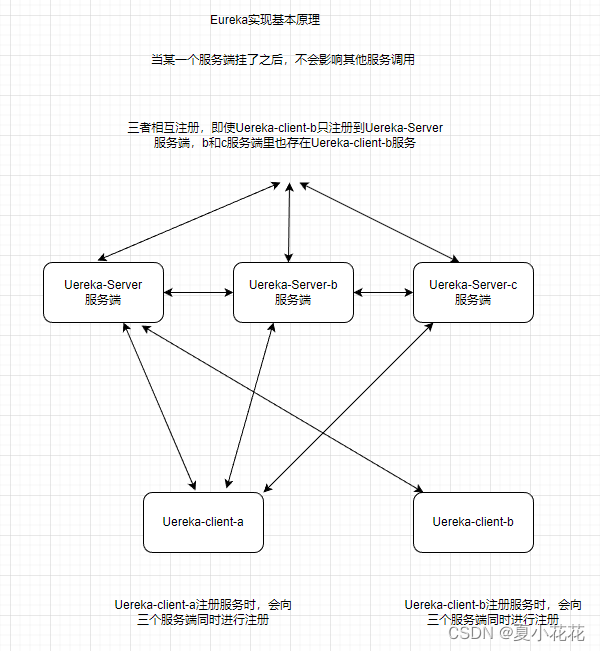
Spring Cloud Eureka详细介绍
C# 使用Socket对接
C# 工具类
Java QueryWrapper基本用法
vue 前端参值后端接收的几种方式
ant design vue + jeecgboot 实现本地上传视频及播放视频功能
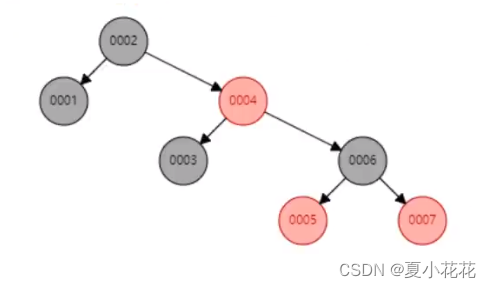
浅谈数据结构---红黑树、二叉树
css div添加滚动条(附加源码)
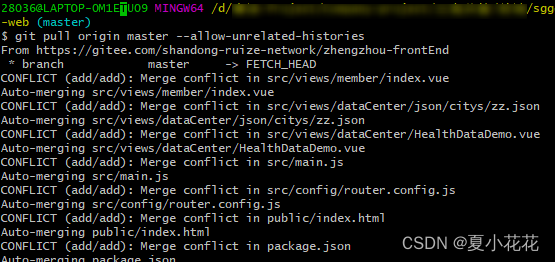
git 拉取代码仓库代码报错(合并错误 refusing to merge unrelated histories)
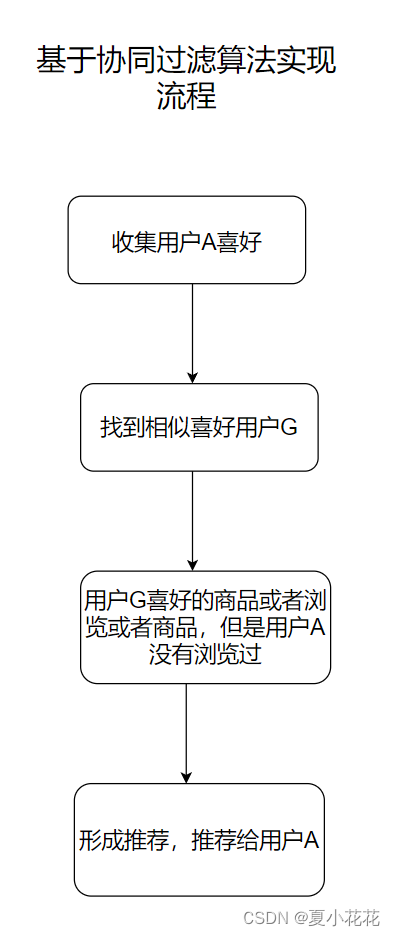
基于用户的协同过滤算法实现商品推荐
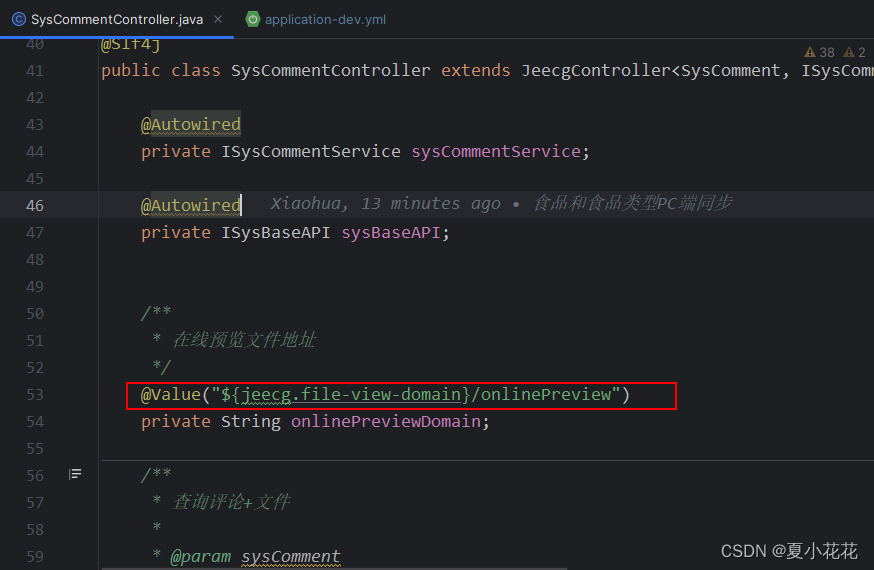
完美解决 Could not resolve placeholder ‘jeecg.file-view-domain‘ in value “${jeecg.file-view-domain}
npm install安装时一直idealTree:npm: sill idealTree buildDeps解决方案(亲测有效)
mysql 数据库查询 查询字段用逗号隔开 关联另一个表并显示
element多选框select下拉框数据回显的问题value.push is not a function
Windows Docker Desktop 无法启动 自动退出报错信息为:Docker Desktop -Unexpected WsL error An unexpected error was e
完美解决git 执行git push origin master指令 报错command not found
linux postgresql 常用指令
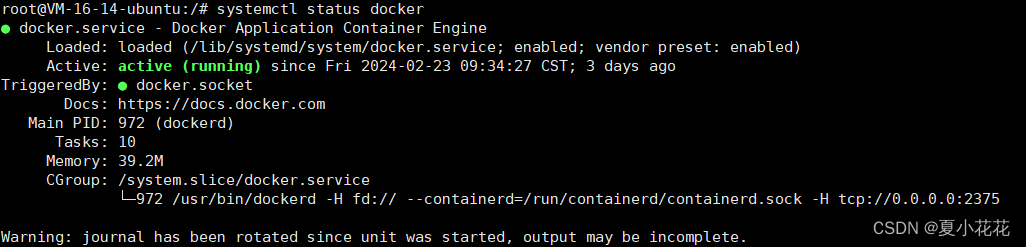
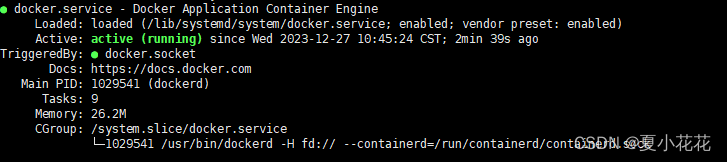
docker 常用指令(启动,关闭,查看运行状态)
若依 mybatis报错nested exception is org.apache.ibatis.binding.BindingException: Parameter ‘XXX‘ 错误
ubuntu 系统切换root用户
postgresql 出现连接不上问题(或者安装完连接不上)附加安装教程 亲测有效!
docker 安装mysql(踩坑踩得想哭 详细解决教程)ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using pa
Mysql 嵌套子查询
Mysql 触发器
sudo apt-get update失败已经解决 报错 The update command takes no arguments
ubuntu 20.04 安装docker教程和安装中遇到的问题解决方案(超详细 附加图文教程)
yarn 安装 卸载降级升级 以及常用指令
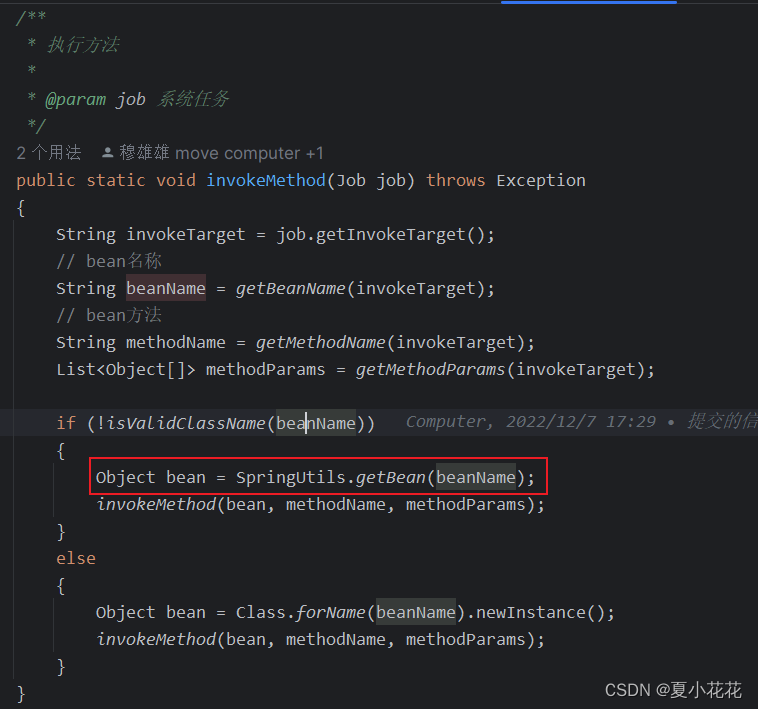
SpringBoot 使用Quartz执行定时任务对象时无法注入Bean问题
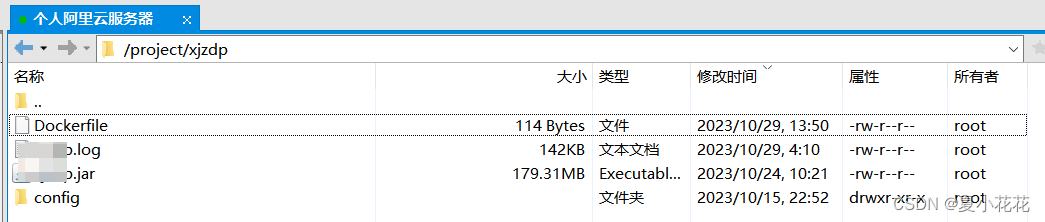
Docker 部署spring-boot项目(超详细 包括Docker详解、Docker常用指令整理等)
uniapp 实现当前页面分享至微信好友或朋友圈功能(带参数和无参数)
超详细 async和await 项目实战运用(附加文字解答+源码)
nginx配置SSL证书配置https访问网站 超详细(附加配置源码+图文配置教程)
PS gif修改背景颜色(附加图片)