热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
深入理解操作系统的内存管理:原理与实践
【vue】v-model双向绑定
构建高效自动化运维体系:策略与实践
PYTHON用RNN神经网络LSTM优化EMD经验模态分解交易策略分析股票价格MACD
如何永久关闭笔记本键盘
深入理解操作系统的内存管理机制
【CSS】常用样式
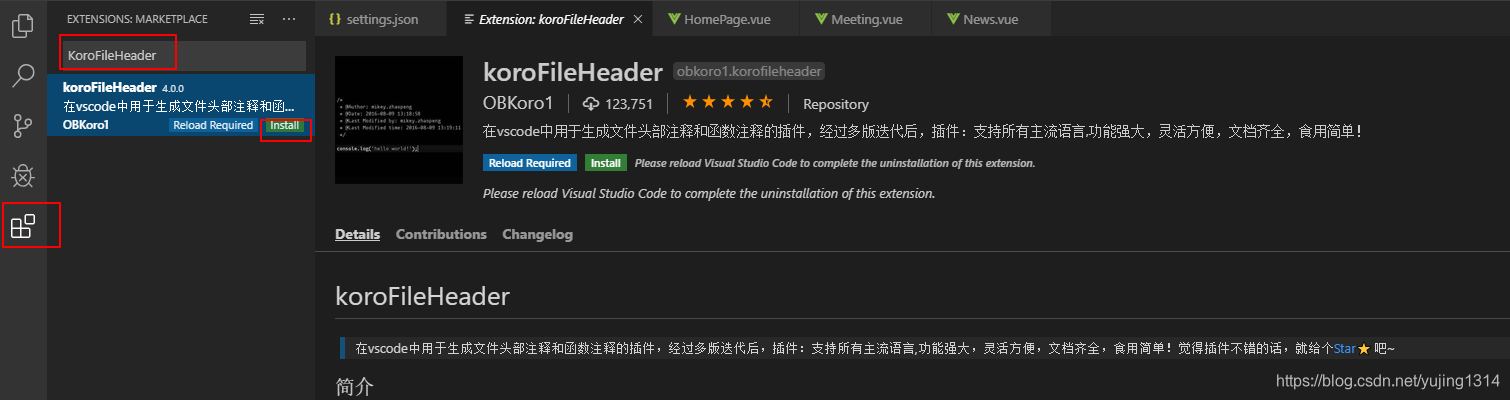
【VSCode】自动生成文件头部注释和函数注释
Vue入门(二)
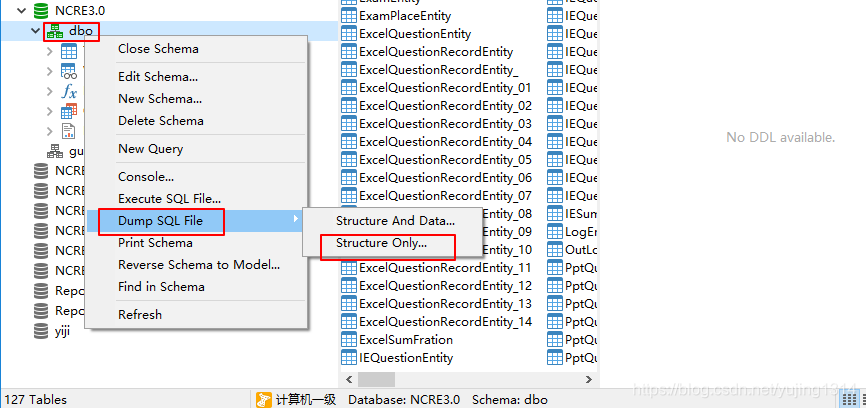
【Navicat】如何导出建表sql
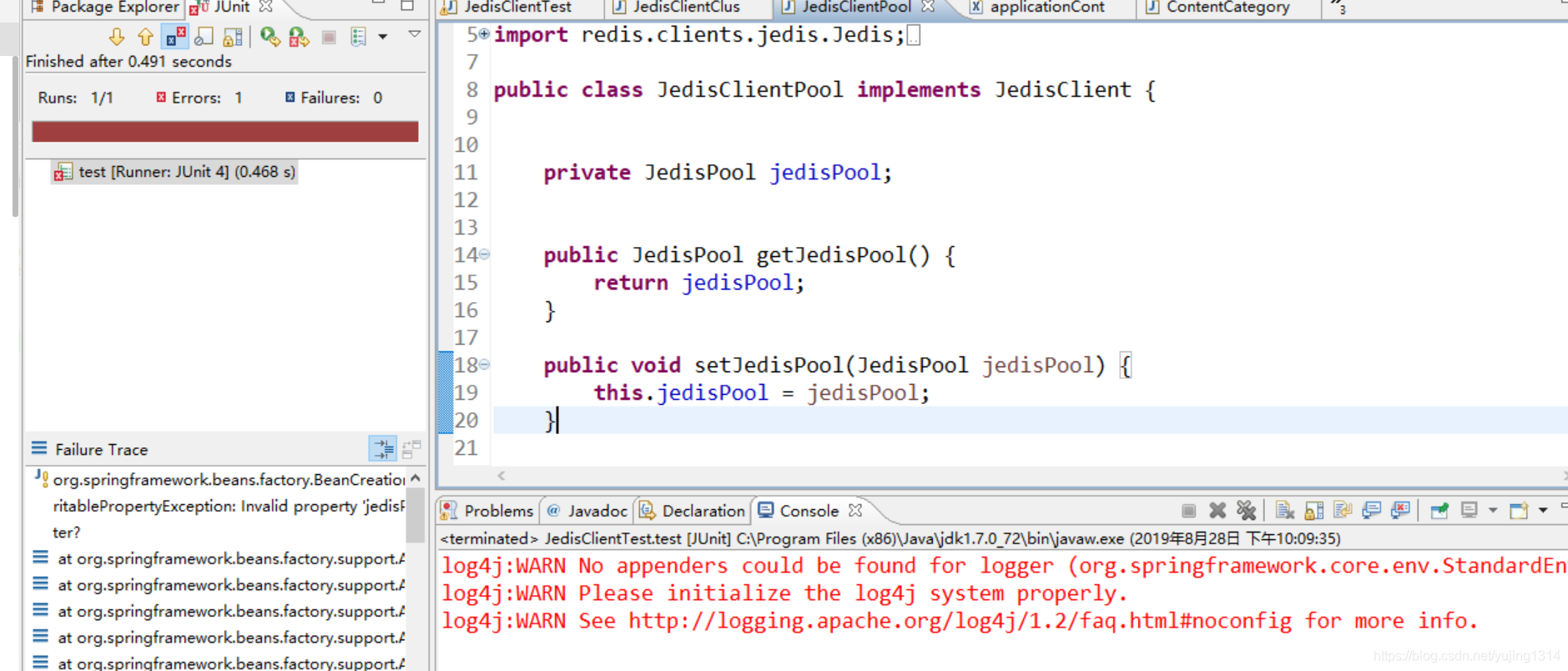
spring整合redis出错
【Linux】虚拟机ip端口如何固定
【视频】复杂网络分析CNA简介与R语言对婚礼数据聚类社区检测和可视化|数据分享
阿里巴巴瓴羊基于 Flink 实时计算的优化和实践
【redis】con't connect to redis-server
【redis】如何搭建redis集群
【Linux】常用命令
【redis】安装和使用教程
错误: 找不到或无法加载主类 org.codehaus.plexus.classworlds.launcher.Launcher
springboot @Transactional的概念以及实战
网络安全与信息安全:防御前线的科学与艺术
nginx: [error] invalid PID number "" in "/var/run/nginx/nginx.pid"
PHP中的异常处理:一个全面的指南
每天解析一个脚本(44)
【Linux】虚拟机ipv4地址消失,主机ping不通
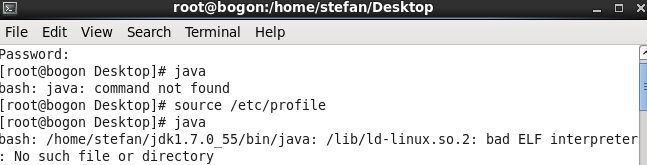
【Linux】bash: /home/stefan/jdk1.7.0_55/bin/java: /lib/ld-linux.so.2: bad ELF interpreter
谈谈钉钉工作台的体验优化及技术思考
【nginx】[emerg] "server" directive is not allowed here in /usr/local/nginx/conf/nginx.conf:45
DHCP-动态主机配置协议
【Linux】中如何安装nginx
每天解析一个脚本(43)
centos 6.5安装yum
Python信贷风控模型:Adaboost,XGBoost,SGD, SVC,随机森林, KNN预测信贷违约支付|数据分享
入门篇:如何快速升级和迁移Confluence
入门篇:如何快速安装和破解Confluence, 打造您的完美知识库
【SVN】如何取消文件和SVN服务器的关联
Vue 报错 error:0308010C:digital envelope routines::unsupported
【Linux】如何修改系统文件并保存(配置jdk1.7环境变量)
Oracle索引知识看这一篇就足够
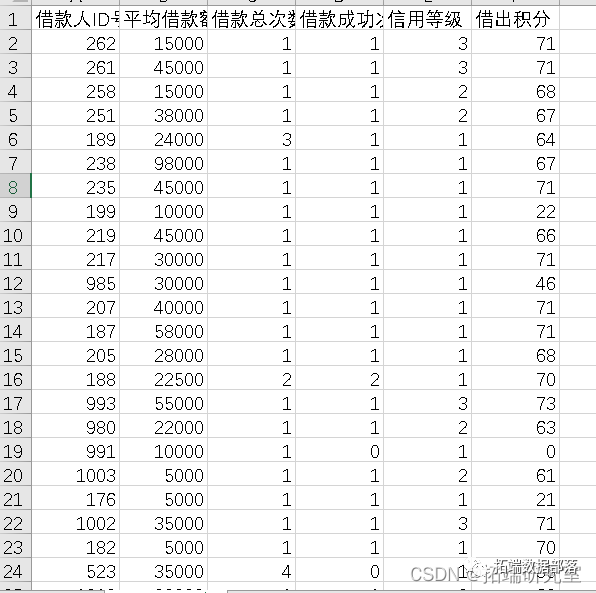
SPSS用KMEANS(K均值)、两阶段聚类、RFM模型在P2P网络金融研究借款人、出款人行为数据规律
Linux|Awk 变量、数字表达式和赋值运算符
Oracle 性能优化之AWR、ASH和ADDM(含报告生成和参数解读)
测试八年|对业务测试人员的一些思考
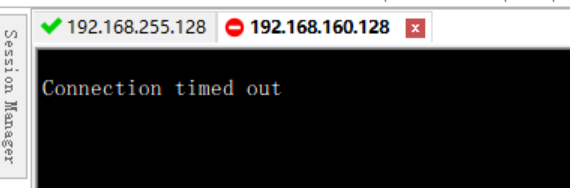
【Linux】SecureCRT连接虚拟机一直显示Connection timed out
一篇文章弄懂Oracle和PostgreSQL的Database Link
如何查询虚拟机Linux的IP和修改