用户福利
阿里云发布业界首款云原生多模数据库Lindorm,新用户可享9.9元/3个月优惠,技术交流钉钉群:35977898,更多内容请参考链接
背景
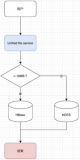
Phoenix的索引构建有两类方法:
- 同步构建,直接通过sqlline.py create index构建
在云HBase Phoenix 5.x之后,同步构建可以通过轻客户端或重客户端来构建。 - 异步构建,先create index ... async, 然后通过MR提交build索引job。
因此我们有三种方式构建索引:轻客户端、重客户端、MR异步构建,我们依次介绍下各种方案的优缺点、适用场景和使用方法。
同步构建-轻客户端
适用与数据量比较小,一般构建耗时在10分钟以内。
使用方式: 直接使用轻客户端, sqlline-thin.py , create index 即可。
如果数据量较大,我们很可能会遇到索引build超时,我们释放调整Phoenix hbase.rpc.timeout、hbase.client.scanner.timeout.period、phoenix.query.timeoutMs 配置,重启Queryserver生效。
优点:
- 简单,不占用客户端资源,整个build过程是在服务端完成的。
缺点:
- 调整参数需要重启queryserver生效,重启过程会导致线上服务临时中断
- 调整参数会对线上服务造成影响
如果有异常SQL导致的大请求会导致服务端负载高,调整了RPC超时时间, 一旦遇到这种请求,无法及时中断,可能对线上业务产生的影响。 - 无法控制并发,可能因为索引构建打爆服务器
同步构建-重客户端
重客户端适用于中小规模的数据构建,一般索引构建时间在10小时以内。
使用方式:
-
下载重客户端工具
- 部署在用户VPC下,机器配置大于等于4c8g;重客户端构建索引的过程中流量会经过这个节点,如果需要更快的索引构建,可以升级节点配置。
- 调整配置 bin/hbase-site.xml后,使用bin/sqline.py
-
集群地址
- hbase.zookeeper.quorum
zk 连接地址,注意使用VPC链接地址。
- hbase.zookeeper.quorum
-
并发数
- phoenix.query.threadPoolSize
并发数,越大对目标集群读写压力,可以从1开始逐步增加
- phoenix.query.threadPoolSize
-
超时配置
- phoenix.query.keepAliveMs
- hbase.rpc.timeout
- hbase.client.scanner.timeout.period
- phoenix.query.timeoutMs
超时时间单位是ms, 可以按需调整。
for ex:
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1-1,master2-1,master3-1:2181</value>
</property>
<property>
<name>phoenix.query.threadPoolSize</name>
<value>1</value>
</property>
<property>
<name>phoenix.query.keepAliveMs</name>
<value>60000000</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>优点:
- 灵活,并发、超时时间可以按需调整,无需重启Phoenix集群,对线上服务影响小
缺点:
- 需要单独build索引的资源机器
- 受制于build索引机器的单机性能,扩展性差。
异步构建-MR
MR索引构建适用于超大规模数据的情况。
使用方式:
-
异步索引构建方案
- 创建异步索引
CREATE INDEX async_index ON my_schema.my_table (v) ASYNC - 提交MR JOB build 索引
- 创建异步索引
hadoop --config /mr-phoenix-conf jar \
/mr-phoenix-conf/ali-phoenix-5.2.4.1-HBase-2.x-client.jar \
org.apache.phoenix.mapreduce.index.IndexTool \
--data-table {DATA_TABLE_XXXX} \
--index-table {INDEX_XXX} \
--output-path hdfs://hbase-cluster/ASYNC_INDEX_TMPps: ali-phoenix-client获取,先下载重客户端包,解压后,取ali-phoenix-xxxx-HBase-2.x-client.jar
- 索引Build MR环境准备
- 自建Hadoop或者购买EMR Hadoop集群
- 在MR环境中创建mr-phoenix-conf目录
- 配置云HBASE的zk到hbase-site.xml,并此配置文件添加到mr-phoenix-conf目录
云HBase的zk地址可以从控制台获取。 - 拷贝以下hadoop配置文件到mr-phoenix-conf目录下,包括: core-site.xml、mapred-site.xml、yarn-site.xml、hdfs-site.xml
- 修改hdfs-site.xml(mr-phoenix-conf目录下) 增加hbase hdfs访问能力。
云HBase HDFS开端口和NN地址获取,找@云HBase答疑协助。
- 修改dfs.nameservices 增加hbase-cluster
- 增加hbase-cluster hdfs相关配置
EMR集群打通HBase集群参考配置
<property>
<name>dfs.nameservices</name>
<value>emr-cluster,hbase-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hbase-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.hbase-cluster</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.namenodes.hbase-cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hbase-cluster.nn1</name>
<value>${nn1-host}:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hbase-cluster.nn2</name>
<value>${nn2-host}:8020</value>
</property>优点:
- 可以对任意规模数据进行索引构建, 扩展性强
缺点:
- 需要准备单独build资源
- 相对复杂
总结
| 适用数据量 | 优点 | 缺点 | |
|---|---|---|---|
| 轻客户端 | 0~10GB | 简单,无需额外资源 | 配置参数调整会影响线上服务 |
| 重客户端 | 10GB-512GB | 可以灵活配置并发、超时参数,无需重启Phoenix集群 | 需要单独的构建索引的机器,受制于单机性能 |
| MR异步构建 | 512GB~TB级 | 适用于任意规模索引构建,扩展性强 | 额外MR资源、MR集群配置复杂 |
一般少量数据直接用轻客户端来做索引构建,对于中小规模的数据推荐用重客户端来构建索引,而大规模数据则推荐用MR进行索引构建。
参考文档: