热门
【大模型】如何向非技术受众解释LLM的概念及其能力?
【大模型】哪些关键考虑因素使用 LLM 进行客户服务交互
【大模型】如何诊断和解决LLM 开始生成令人反感或与事实不符的输出?
【大模型】如何处理微调LLM来编写创意内容?
【大模型】探索LLM在各个行业的潜在未来应用
【大模型】如何利用 LLM 来创建更像人类的对话?
⚡REST 和 SOAP 协议有什么区别?
如何在家中使用手机或电脑远程控制公司iStoreOS软路由下的电脑桌面
【探索Linux】P.33(HTTP协议)
运用自定义协议设计与实现“跨网络计算器”
Elasticsearch FSCrawler 一个bug及解决方案
Elasticsearch 配置文件 path.data 中可以配置多个数据目录的路径吗?
Windows电脑如何使用固定TCP公网地址远程连接内网Deepin深度操作系统
探索MATLAB在计算机视觉与深度学习领域的实战应用
大模型时代:一群人的狂欢,一个人的孤单!
Elasticsearch 8.X 向量检索和普通检索能否实现组合检索?如何实现?
【探索Linux】P.32(自定义协议)
一张图30个知识点,全方位认知 Elasticsearch 技术发展
干货 | 2024 年 Elasticsearch 常见面试题集锦
Elasticsearch 悬挂索引解析与管理指南
BoostCompass( http_server 模块 | 项目前端代码 )
用 Python 优雅地玩转 Elasticsearch:实用技巧与最佳实践
BoostCompass( 查找功能实现 )
CentOS如何使用Docker部署Plik服务并实现公网访问本地设备上传下载文件
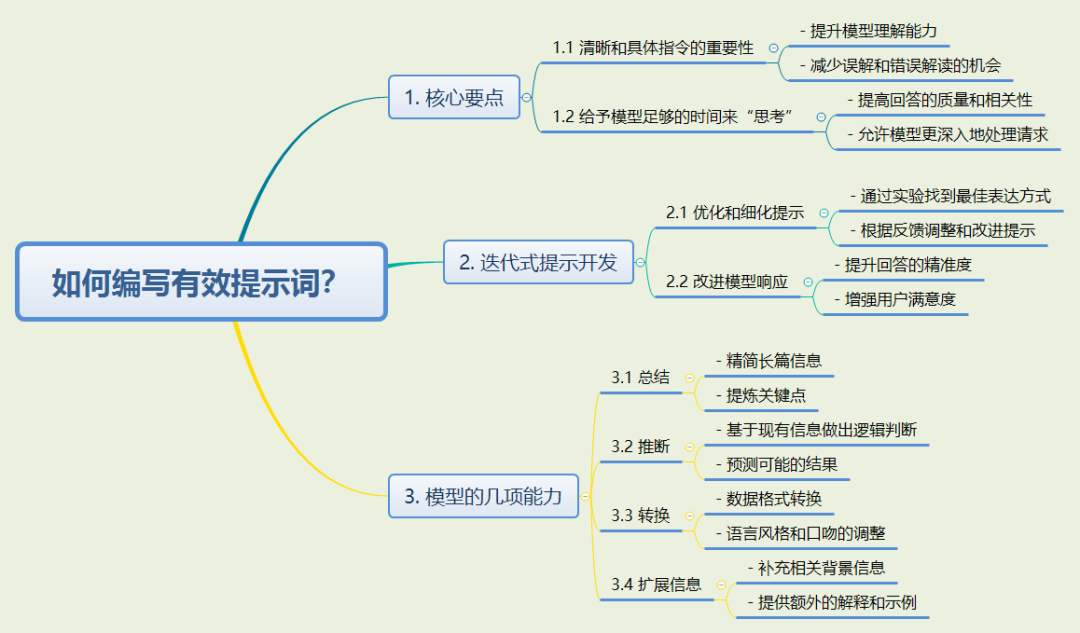
吴恩达 x Open AI ChatGPT ——如何写出好的提示词视频核心笔记
Elasticsearch 通过索引阻塞实现数据保护深入解析
BoostCompass(建立正排索引和倒排索引模块)
死磕Elasticsearch:携手六年,感谢有你!
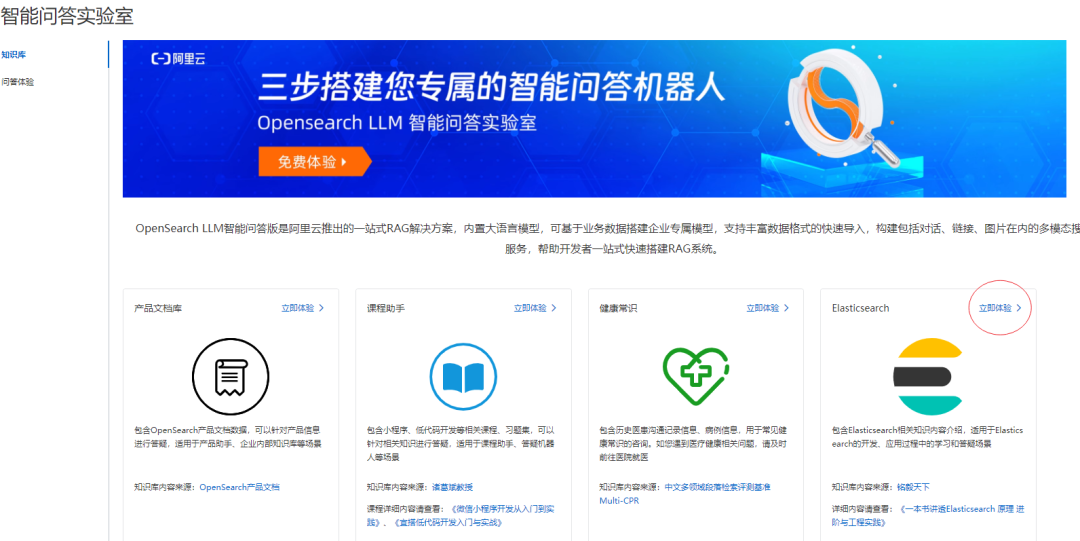
重磅 | Elasticsearch 智能知识问答上线了
BoostCompass(数据准备预处理模块)
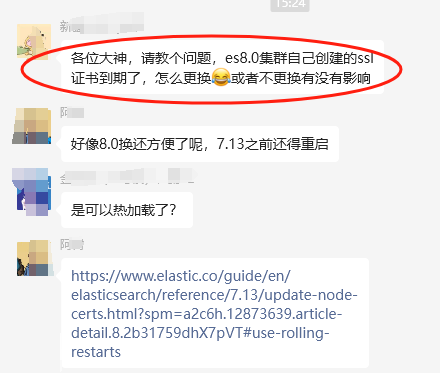
Elasticsearch 8.X 集群 SSL 证书到期了,怎么更换?
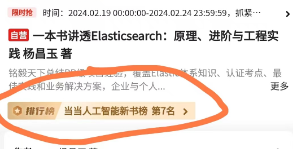
《一本书讲透 Elasticsearch》荣登当当人工智能新书榜
Elasticsearch 与 OpenSearch:开源搜索技术的演进与选择
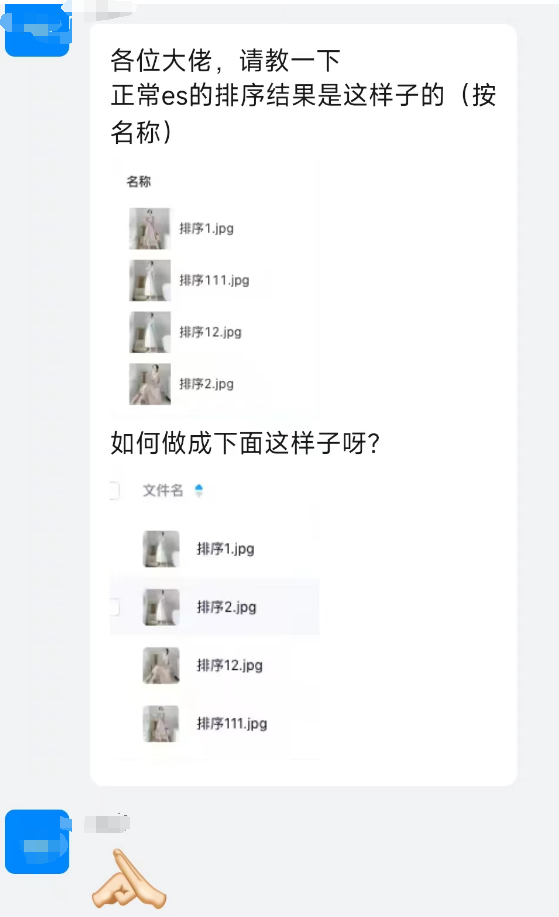
来自钉钉群的问题——Elasticsearch 如何实现文件名自定义排序?
如何使用vscode启动Flask并实现无公网IP远程访问内网服务
近期,几个典型 Elasticsearch 8.X 问题及方案探讨
正排索引 vs 倒排索引 - 搜索引擎具体原理
每一个突破下限的 DSL 背后都隐藏着一个“傻X”的客户需求
日志解析神器——Logstash中的Grok过滤器使用详解
7 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书已上线...
大白话讲清楚:什么是 Langchain 及其核心概念
BoostCompass —— 搜索引擎
Langchain 与 Elasticsearch:创新数据检索的融合实战
如何在Ubuntu系统部署Z-blog博客结合cpolar实现无公网IP访问本地网站
Elasticsearch 8.X 如何依据 Nested 嵌套类型的某个字段进行排序?
Elasticsearch 8.X 小技巧:使用存储脚本优化数据索引与转换过程
Elasticsearch “指纹”去重机制,你实践中用到了吗?
【探索Linux】P.31(守护进程)
Elasticsearch 写入优化探索:是什么影响了refresh 耗时?
最近几个典型 Elasticsearch 线上易出错难排查问题汇集,咱们得避免!