作者:DeeperMan
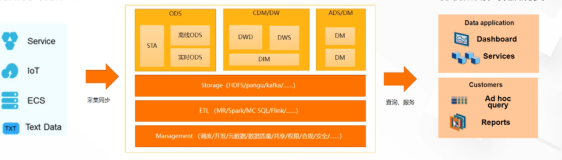
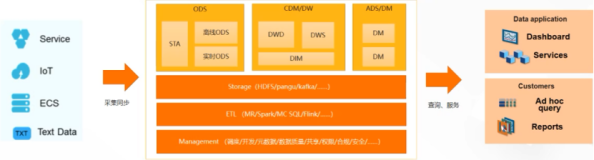
采集&传输层
- Sqoop
Hadoop、关系型数据库之间传输数据的工具。传输时,会启动多个MR作业并发的传输数据 - DataX
阿里巴巴开源的数据同步工具,用来在各种异构数据源之间同步数据。比如 RDBMS<->Hadoop/MaxCompute、RDBMS<->hbase/ftp等等。部署、运维非常简单,将DataX的jar包copy到linux系统中即可运行 - Flume
分布式的高可用的数据收集、聚集的工具。通常用于从其他系统搜集数据,如web服务器产生的日志,结合Kafka的消息队列功能,实现实时日志处理、离线日志投递。 典型的使用方案是:
离线计算:应用系统日志 -> flume -> kafka -> hdfs -> MR作业
实时计算:应用系统日志 -> flume -> kafka -> blink/jstorm/storm/spark streaming
- Logstash
服务器端数据收集工具,能够同时从多个来源采集、转换数据。日志收集功能与Flume比较类似 - Kafka
基于发布/订阅机制的分布式的消息系统。常用于日志投递、分发场景 - RocketMQ
阿里巴巴开源的消息队列工具。经过了双11场景的洗礼,稳定性、可靠性非常好
存储层
- HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取数据文件 - HBase
Hbase是分布式、KV查询的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,LSM数据存储格式提供了高性能读写能力 - Redis
Redis是key-value存储系统。采用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志格式,并提供多种语言的API。提供了哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等数据结构 - Ceph
开源分布式存储系统,提供了块储存RDB、分布式文件储存Ceph FS、以及分布式对象存储Radosgw三大储存功能,是目前为数不多的集各种存储能力于一身的开源存储中间件 - 存储格式
常见的有Apache Parquet,Apache ORC、华为Carbondata、Kudu、Avro等。在大数据领域,面向不同的业务场景,采用不同的数据存储格式。这几类存储格式的差异点,主要体现在行、列存储、预计算
计算层
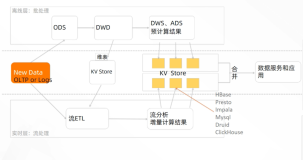
1、离线计算
- Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。是事实上的离线数据仓库标准。 - Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 - MaxCompute
阿里巴巴开发,基于MR原理的大数据处理平台,已经通过阿里云对外输出,是一种快速、完全托管的TB/PB级数据仓库解决方案。 - CDH
CDH是Cloudera的软件发行版,包含Apache Hadoop及相关项目。所有组件都是100%的开源(Apache许可证)。
2、实时计算
- Storm/Jstorm
分布式的、高容错的实时计算系统,2014年以前应用非常广泛,近几年初步被其他流计算产品替代。 - Flink
Flink是一个低延迟、高吞吐、统一的大数据计算引擎。在阿里巴巴的生产环境中,Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。同时Flink提供了一个Exactly-once的一致性语义。保证了数据的正确性。这样就使得Flink大数据引擎可以提供金融级的数据处理能力。 - Spark Streaming
Spark Streaming 类似于 Apache Storm,是一个流计算处理框架。Spark Streaming 有高吞吐量和容错能力强这两个特点。
在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
数据服务层
- Kylin
开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。核心原理是数据预计算,利用空间换时间来加速查询模式固定的OLAP查询。最新的版本已经支持了实时数据导入。 - Druid
Druid也是一款非常流行的olap引擎,基于MPP架构,采用了 预聚合、列式存储、字典编码、位图索引 4个方法,加速查询性能。 截止2019年9月22日,Druid原生不支持数据精确去重功能。快手已经将Druid应用于生产环境。 - Presto
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。 - Lucene
Lucene 是一个基于Java 的全文信息检索工具包,目前主流的搜索系统Elasticsearch和solr都是基于lucene的索引和搜索能力进行。 - ElasticSearch
基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎。 - Solr
Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr 4还增加了NoSQL支持。 - Palo
百度开源的olap引擎,在百度内部使用比较广泛。基于MPP架构,集成了Google Mesa、Cloudera Impala。
阿里巴巴数据中台团队,致力于输出阿里云数据智能的最佳实践,助力每个企业建设自己的数据中台,进而共同实现新时代下的智能商业!
阿里巴巴数据中台解决方案,核心产品:
Dataphin,以阿里巴巴大数据核心方法论OneData为内核驱动,提供一站式数据构建与管理能力;
Quick BI,集阿里巴巴数据分析经验沉淀,提供一站式数据分析与展现能力;
Quick Audience,集阿里巴巴消费者洞察及营销经验,提供一站式人群圈选、洞察及营销投放能力,连接阿里巴巴商业,实现用户增长。
欢迎志同道合者一起成长!更多内容详见 https://dp.alibaba.com