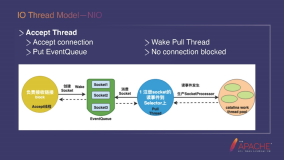
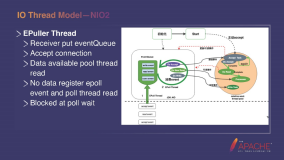
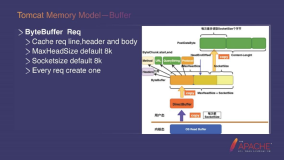
"快照"概念
计算机科学中,快照是对机器上某一个时间点的数据的拷贝。
你可能做过如下的事情:
每一个快照中的文件,都是你所保存的短文的某一个时间点上的拷贝。快照提供了一个简单的撤销更改以及备份系统的方法。
Cassandra存储数据的方式
Cassandra 将数据以keyspace(在mysql/PostgreSQL里面就是database的类似概念),table形式逻辑存储。数据实际上则是存储在SSTable里面的。
当Cassandra将数据写到磁盘上的时候,他会生成一个SSTable文件,每一个SSTable文件是不可更改的,所以在每次从内存中flush数据下来的时候都会生成一个SSTable文件。在Cassandra中会有一个特殊的叫做Compaction的过程用来自动的将table下面的多个SSTable文件合并起来。
例如,如果我们在App这个keyspace里面有一个Users的table(老一点的版本叫做column family 列族),数据文件的存储样子就会像下面这样:
<Cassandra Data>/App/Users/
1-big-Data.db
2-big-Data.db
3-big-Data.db
4-big-Data.db每一个big-data.db的文件都是SSTable的数据存储文件,Compaction将会将这些SSTable文件合并成为一个新的文件比如叫做5-big-data.db。
Cassandra 如何打快照
当你打快照的时候,cassandra会对每一个live SSTable文件进行打hard-link。这个流程实际上是比较简单的。
什么是hard-link
hard link 就是我们理解的硬链接,在类unix系统里面,系统将会使用Inodes去索引对应磁盘上面的文件,所以计算机上面的文件最终都是由Inodes进行索引。一个hard link 是一个与你现有的文件共享一个Inode的新文件。
hard link 与soft link不一样,soft link则是存储了源文件的路径。
补充
对于hard link而言,有一个重要的特性,那么就是当所有的引用都被清楚以后这个实际引用到的物理文件才会被删除。
举个例子,Inode 1001 在磁盘上面索引了500M的文件,我们有2个文件指向Inode1001 ,如果我们删除第一个link,这个文件不会被清理掉,但是当所有的link被清理掉以后这个500M文件将会被删除。
Cassandra的快照存储
因为快照是对已有文件的hard link,所以这些文件不能跨文件系统。 快照文件在Column family(table)目录下面的snapshots目录,如果我们打了一个叫做snapshot1的快照,那么在我们的文件系统上的存储格式将会是这样的:
<Cassandra Data>/App/Users/
1-big-Data.db
2-big-Data.db
3-big-Data.db
4-big-Data.db
<Cassandra Data>/App/Users/snapshots/snapshot1
1-big-Data.db (Hard link)
2-big-Data.db (Hard link)
3-big-Data.db (Hard link)
4-big-Data.db (Hard link)即使你的源文件执行删除操作,或者源文件执行了merge操作,这个都不会影响snapshot文件的存储。
<Cassandra Data>/App/Users/
5-big-Data.db
<Cassandra Data>/App/Users/snapshots/snapshot1
1-big-Data.db
2-big-Data.db
3-big-Data.db
4-big-Data.dbsnapshot对存储容量影响
在分布式存储系统里面,计算你的存储容量并不是简单的计算你的空闲存储空间,snapshot对存储容量是有一定的影响的,特别是你如果周期性的进行snapshot操作,对存储容量的影响还是要考虑进去。
因为我们的snapshot对已有的文件进行了hard link,所以我们的compacttion任务在后台自动做merge的时候,将老文件合成新文件并不能物理上实际删除打了快照的文件,这个将会影响我们的存储容量。
我们可以做一个简单的假设,你有100G的磁盘存储空间,Cassandra使用了50G。
1.你打了一个快照,这个打快照生成的文件不会占用什么存储空间,假设还是50%的容量空闲。
2.后台执行了一个major compact操作,比如cleanup 或者是手工执行scrub操作,这个操作会将已有的table数据重新写入磁盘
3.原有文件将会被重新写入,且存储的文件都是重叠的。那么现在就是100% 使用了。
虽然上述列子是一个极端情况下的假设,但是实际上打快照以及组合compaction的确会对磁盘容量产生较大影响。
从快照中恢复数据
没有自动的快照恢复机制,这里需要执行一些手动操作。
当cluster在运行:
- truncate 需要恢复的表
- 停止cassandra服务
为什么需要truncate? 如果有一些tombstone残留着,那么他们可能会删除你将要恢复的文件。 truncate将会remove你表中的tombstones。
(译者注:从snapshot中恢复数据操作需要视具体的操作而言,这里的case需要视你的需求,如果需要恢复到数据tombstones的时间点前,且时间点后的数据不需要,那么truncate表可以理解)
cluster中的所有节点上:
- 到对应的需要恢复数据的snapshot目录下面
- 把已有的目录下的SSTable文件拷贝到数据目录下面
最后
- 启动cassandra 服务
- 每个节点执行下nodetool refresh
相关命令索引
打快照
nodetool snapshot [options] [keyspaces]引用:
https://cassandra.apache.org/doc/latest/tools/nodetool/snapshot.html
(译者注:可以在使用nodetool help command,展示出各个command的操作帮助指南)
执行快照名字打快照
nodetool snapshot -t name
对一个特殊keyspace下的所有table打快照
nodetool snapshot keyspace
对2个指定表打快照
nodetool snapshot -kt keyspace.tabel1 keyspace.table2
列出所有快照
nodetool listsnapshots引用:https://cassandra.apache.org/doc/latest/tools/nodetool/listsnapshots.html
清理快照
nodetool clearsnapshot [options] [keyspaces]引用:https://cassandra.apache.org/doc/latest/tools/nodetool/clearsnapshot.html
删除所有快照
nodetool clearsnapshot
删除带快照名的快照
nodetool clearsnapshot -t snapshot_name
(译者注:为啥要用-t?明明是快照名,这应该是历史问题,因为-t的代码逻辑是-tag,内部代码早期是以tag来处理这个快照)
删除keyspace下的快照
nodetool clearsnapshot keyspace
(译者注:阿里云cassandra部分功能也用到了snapshot,也在调研的时候发现一些社区已有的问题并解决,比如:CASSANDRA-13019,当然我们也提交了一些我们发现的问题,比如CASSANDRA-15297,包括上述描述的快照空间问题,我们也有对应进行解决。)
入群邀约
为了营造一个开放的 Cassandra 技术交流环境,社区建立了微信群公众号和钉钉群,为广大用户提供专业的技术分享及问答,定期开展专家技术直播,欢迎大家加入。另外阿里云提供免费Cassandra试用:https://www.aliyun.com/product/cds