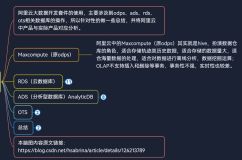
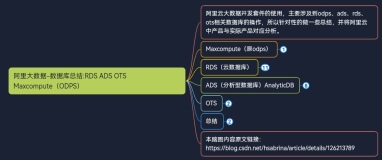
DLA很早之前就支持了对关系型数据库的查询,但是一直以来用户会有一个担心:
直接分析RDS里面的数据会不会影响线上业务。
这个担心很合理,除非你要查询的RDS是专门用来做后台数据分析使用的,否则直接大规模分析确实可能会造成数据库性能下降,影响前台业务。对于这个担忧我们做过一些改进的措施,比如提供hint让用户可以手动指定底层查询并发度, 但是不是最理想的方案。
因此我们现在推出了一个极致方案: 每天自动、无缝地帮您把RDS里面的数据同步到OSS上面,并建立好相应的表结构 -- 跟RDS里面一样的表结构,让你可以基于OSS的数据进行无忧无虑的分析,这个功能我们称之为一键建仓。
一键建仓
首先打开DLA的Schema管理页面,这里显示了您所有的数据库。

点击“创建Schema”按钮进入建库向导选择页面,选择其中的“一键建仓”,点击“使用向导创建”

因为一键建仓其实是在打通你的RDS数据和OSS数据,因此我们需要您的RDS和OSS授权:

授予好权限之后点击下一步进入一键建仓配置的主页面:

这个页面的左边列出了你所有的RDS,这是我们要建仓的数据来源,选择其中您要建仓的RDS,右边的服务器名,端口会自动填上,然后您需要填上用户名,密码,以及要同步的RDS的库名。
照道理说这个RDS的库名应该提供一个下拉框直接选就好了,不过目前由于一些限制暂时只能手动输入。
RDS信息填写完毕之后可以点击“测试连接”验证一下填写是否正确。

数据来源搞定之后,下一步我们要填写“建仓配置”,这一块是我们数仓相关的配置,在DLA的场景下主要是OSS相关的一些配置, 主要有三个:
- Schema: 这份数据在DLA里面新建一个什么名字的Schema
- 数据位置: 这份数据放在您的哪个bucket的哪个路径下
- 同步时间: 每天几点帮您定时同步RDS的最新数据到OSS上面
这里同步时间要注意下,应该选择半夜业务低谷的时候进行同步,避免影响线上业务。另外选择数据位置的时候我们会对您赋予DLA的OSS操作权限进行校验,如果没有赋予足够的权限,我们会做提示:

一键建仓需要用户授予DLA对于所选择的路径有删除权限,因为我们每天会同步最新的数据到OSS上来,这里就涉及到要删除老数据的操作,关于如果赋予DLA OSS删除权限的详情可以参见这篇文章: 如何授权OSS删除权限给DLA。
为什么前面已经进行了OSS授权,这里又来检查一遍OSS权限?
上一步授权的只是OSS只读权限,因为OSS删除权限兹事体大,因此没有在默认的权限里面,需要用户单独手动授权。
所有输入框有输入完毕之后点击“创建”就完成了创建操作,然后我们可以去Schema列表去查看我们通过一键建仓创建出来的这个新的Schema:

点击“详细信息”进入这个Schema的详情页面,可以看出跟普通的Schema不一样,这个Schema的详情里面多了一个“配置”的选项卡,这个选项卡里面有一键建仓的详细配置。

如果有修改一键建仓配置可以点击更新。比较有意思的是这个“立即同步”的按钮,一键建仓建立好了之后,我们只是建立了一个空的数据库,没有马上进行同步,而是要等用户设定的时间才运行,以免影响线上业务。如果用户判断对线上影响不大,想立马把数据同步过来以进行分析,那么可以点击“立即同步”的按钮。点击之后可以去“监控中心”的“任务列表”查看正在运行的一键建仓任务:

这里可以看到执行的任务的类型,名称,状态,点击详情可以看到JSON格式的更详细的状态信息:哪些表正在同步,哪些表已经同步完成:

等这个任务执行完成之后再回去看这个Schema就会发现已经有表了:

来,我们再验证一下数据是不是真的过来了:

果然数据也有了,搞定!
总结
这里我们介绍了DLA最新引入的一键建仓的功能,一键建仓的作用就是为了让数据在RDS里面的客户可以方便、快速、没有后顾之忧地对业务数据进行分析,希望这个功能的引入能够让大家把RDS里面的数据更好的分析起来。