Linux之Pacemaker+Corosync【红帽7的高可用】
Pacemaker介绍:
corosync 是HA集群组件的一部分,专门负责消息的传递,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
pacemaker 是一个集群资源管理器,干的就是我们常说的CRM的活,它可以定义资源的组和次序。
corosync+pacemaker pacemaker负责心跳,corosync传递消息,两者合并组成一个完整的HA集群
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
Pacemaker是一个集群资源管理者。他用资源级别的监测和恢复来保证集群服务(aka.资源)的较大可用性。它可以用你所擅长的基础组件(Corosync或者是Heartbeat)来实现通信和关系管理
注意:配置了fence的时候,我们看到的现象是资源会回切(不一定),因为默认fence和配置资源的主机在不同的机器上
crmsh:命令行管理工具
crm
crm(live)# help
This is crm shell, a Pacemaker command line interface.
Available commands:
cib manage shadow CIBs
resource resources management
configure CRM cluster configuration
node nodes management
options user preferences
history CRM cluster history
site Geo-cluster support
ra resource agents information center
status show cluster status
help,? show help (help topics for list of topics)
end,cd,up go back one level
quit,bye,exit exit the program
资源 资源管理
配置 CRM集群配置
节点的 节点管理
选择 用户首选项
历史 CRM集群历史
网站 Geo-cluster支持
ra 资源代理信息中心
状态 显示集群状态
帮助,? 显示帮助(帮助主题列出主题)
结束,cd, 上升到一个水平
放弃,再见,退出 退出程序
我们现在来学习怎么使用crm:
在crm里面有个configure命令,表示配置集群 有众多子命令 子命令叫做show,显示集群配置信息,这个信息是.xml格式的,只是show把他显示为文本格式 show xml(可看到xml格式的文本)
show:
node dd6.example.com #节点信息
node dd7.example.com
property $id=“cib-bootstrap-options” #全局属性
dc-version=“1.1.10-14.el6-368c726”
cluster-infrastructure=“classic openais (with plugin)”
expected-quorum-votes=“2”
crm(live)configure# property #可用的全局属性
batch-limit= node-health-yellow=
cluster-delay= pe-error-series-max=
cluster-recheck-interval= pe-input-series-max=
crmd-transition-delay= pe-warn-series-max=
dc-deadtime= placement-strategy=
default-action-timeout= remove-after-stop=
default-resource-stickiness= shutdown-escalation=
election-timeout= start-failure-is-fatal=
enable-acl= startup-fencing=
enable-startup-probes= stonith-action=
is-managed-default= stonith-enabled=
maintenance-mode= stonith-timeout=
migration-limit= stop-all-resources=
no-quorum-policy= stop-orphan-actions=
node-health-green= stop-orphan-resources=
node-health-red= symmetric-cluster=
node-health-strategy=
stonith-enabled= 是不是必须要启动stonith设备,默认是必须
crm(live)configure# property stonith-enabled= (敲两下回车)
stonith-enabled (boolean, [true]): #接受boolean值,默认是ture
Failed nodes are STONITH’d
我们要把它设定为false,如果不设定会怎么样呢,我们查看configure的子命令
verify verify the CIB with crm_verify (查看有无语法错误)
crm(live)configure# verify
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
crm(生活)配置#验证
错误:unpack_resources:由于没有定义了STONITH资源,因此禁用了资源启动
错误:unpack_resources:要么使用启用了STONITH的选项配置一些或禁用STONITH
错误:unpack_resources:注意:共享数据的集群需要STONITH来确保数据的完整性
检查期间发现的错误:配置无效
property stonith-enabled=false
crm(live)configure# property stonith-enabled=false
crm(live)configure# verify #再次校验,发现没有报错
crm(live)configure#
在没有stonish设备时,要更改默认值
所有操作得提交才能生效 commit
node:
crm(live)node# help
Node management and status commands.
Available commands:
status show nodes' status as XML
show show node
standby put node into standby
online set node online
maintenance put node into maintenance mode
ready put node into ready mode
fence fence node
clearstate Clear node state
delete delete node
attribute manage attributes
utilization manage utilization attributes
status-attr manage status attributes
help show help (help topics for list of topics)
end go back one level
quit exit the program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
crm(生活)节点#的帮助
节点管理和状态命令。
可用命令:
状态 显示节点作为XML的状态
显示 显示节点
备用 将节点放入备用状态
在线 设置节点在线
维护 节点进入维护模式
准备 将节点放入就绪模式
篱笆 栅栏节点
clearstate 明确节点状态
删除 删除节点
属性 管理属性
利用管理利用属性
status-attr 管理状态属性
帮助 显示帮助(帮助主题列表)
结束 回到一个层次
退出 退出程序
crm(live)node# show #显示所有节点信息
dd6.example.com: normal
dd7.example.com: normal
crm(live)node# standby #要想把一个节点设定为standby或和online,就在哪个节点上设定
crm(live)node# show
dd6.example.com: normal
dd7.example.com: normal
standby: on
crm(live)node# online
crm(live)node# show
dd6.example.com: normal
dd7.example.com: normal
standby: off
resource:
Available commands:
status show status of resources
start start a resource
stop stop a resource
restart restart a resource
promote promote a master-slave resource
demote demote a master-slave resource
manage put a resource into managed mode
unmanage put a resource into unmanaged mode
migrate migrate a resource to another node
unmigrate unmigrate a resource to another node
param manage a parameter of a resource
secret manage sensitive parameters
meta manage a meta attribute
utilization manage a utilization attribute
failcount manage failcounts
状态显示资源状况
开始 启动一个资源
停止 停止一个资源
重启 重启资源
促进 主从资源的推广
降级 为主从资源
管理 将资源放入托管模式
unmanaged 将一个资源放入非托管模式
迁移 将资源迁移到另一个节点
不迁移 将资源迁移到另一个节点
param 管理一个资源的参数
秘密 管理敏感参数
元 管理一个元属性
使用 管理一个使用属性
failcount 管理failcounts
ra:资源代理
Available commands:
classes list classes and providers
list list RA for a class (and provider)
meta show meta data for a RA
providers show providers for a RA and a class
help show help (help topics for list of topics)
end go back one level
quit exit the program
1
2
3
4
5
6
7
可用命令:
类列表类和提供者
类(和提供程序)列表RA
为RA显示元数据
提供者为RA和类提供提供者
帮助显示帮助(帮助主题列表)
结束回到一个层次
退出退出程序
crm(live)ra# classes #显示出资源代理的类别
lsb #常用
ocf / heartbeat pacemaker #常用
service #服务
stonith #用于stonith设备
crm(live)ra# list lsb #查看lsb有哪些资源代理可用
auditd blk-availability corosync corosync-notifyd
crond halt ip6tables iptables
killall lvm2-lvmetad lvm2-monitor netconsole
netfs network nfs nfslock
pacemaker postfix quota_nld rdisc
restorecond rhnsd rhsmcertd rpcbind
rpcgssd rpcidmapd rpcsvcgssd rsyslog
sandbox saslauthd single sshd
udev-post winbind
crm(live)ra# list ocf
CTDB ClusterMon Dummy Filesystem HealthCPU
HealthSMART IPaddr IPaddr2 IPsrcaddr LVM
MailTo Route SendArp Squid Stateful
SysInfo SystemHealth VirtualDomain Xinetd apache
conntrackd controld dhcpd ethmonitor exportfs
mysql mysql-proxy named nfsserver nginx
pgsql ping pingd postfix remote
rsyncd rsyslog slapd symlink tomcat
crm(live)ra# list service (不要想复杂了 这里的service就是lsb)
auditd blk-availability corosync corosync-notifyd
crond halt ip6tables iptables
killall lvm2-lvmetad lvm2-monitor netconsole
netfs network nfs nfslock
pacemaker postfix quota_nld rdisc
restorecond rhnsd rhsmcertd rpcbind
rpcgssd rpcidmapd rpcsvcgssd rsyslog
sandbox saslauthd single sshd
info ocfIPaddr (查看某个资源代理具体怎么用)
有了这些基本概念,我们就可以尝试着在crm怎么配置资源了:
crm configure
primitiv:定义基本资源
group:组资源
clone:克隆资源
ms:主从资源
location:位置约束
colocation:排列约束
order:顺序约束
“”"
Pacemaker 的资源主要有两类,即 LSB 和 OCF。其中 LSB 即 Linux 标准服务,通常就是 /etc/init.d 目录下那些脚本。Pacemaker 可以用这些脚本来启停服务。在 crm ra list lsb 中可以看到。另一类 OCF 实际上是对 LSB 服务的扩展,增加了一些高可用集群管理的功能如故障监控等和更多的元信息。可以通过 crm ra list ocf 看到当前支持的资源。要让 pacemaker 可以很好的对服务进行高可用保障就得实现一个 OCF 资源
“”"
crm(live)configure# help primitive
primitive {[:[:]]|@}
primitive www8(资源名称) apache(资源代理)
params(资源代理传递的参数) configfile=/etc/apache/www8.conf
operations $id-ref=apache_ops (我们给这个资源额外的值)
示例:ha web service
vip:172.25.80.120
crm(live)configure# primitive vip ocfIPaddr2 params ip=172.25.80.120 nic=eth0 cidr_netmask=24
crm(live)configure# verify
crm(live)configure# commit
测试一下node (standby noline)
online后每转移 要是希望转移 就要执行位置约束,但我们没有设定阿
有的同学会想,那我把正在运行的节点上的服务停掉,资源不是就转移了么
但是我们发现 资源并没有启动
Current DC: dd6.example.com - partition WITHOUT quorum (两节点集群 票数小于等于半数)
在不引入仲裁机制的情况下
crm(live)configure# property no-quorum-policy= (在不拥有法定票数的情况下怎么办)
no-quorum-policy (enum, [stop] 枚举值 默认为stop): What to do when the cluster does not have quorum
What to do when the cluster does not have quorum Allowed values(可接受的参数): stop, freeze, ignore, suicide
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit
crm(live)configure# verify
crm(live)configure# show
node dd1.example.com
node dd6.example.com
attributes standby=“off”
node dd7.example.com
attributes standby=“off”
primitive vip ocfIPaddr2
params ip=“172.25.80.120” nic=“eth0” cidr_netmask=“24”
property $id=“cib-bootstrap-options”
dc-version=“1.1.10-14.el6-368c726”
cluster-infrastructure=“classic openais (with plugin)”
expected-quorum-votes=“2”
stonith-enabled=“false”
no-quorum-policy=“ignore”
在配置两节点的corosync集群时,记得设置次选项,否则,它不会在一个节点下线后进行资源迁移的
怎么样,资源定义很简单吧
那怎样管理资源呢
crm(live)# resource
crm(live)resource# show
vip (ocf:IPaddr2): Started
crm(live)resource# status vip
resource vip is running on: dd6.example.com
crm(live)resource# help migrate
Migrate a resource to a different node. If node is left out, the
resource is migrated by creating a constraint which prevents it from
running on the current node. Additionally, you may specify a
lifetime for the constraint—once it expires, the location
constraint will no longer be active.
Usage:
…
migrate [] [] [force]
…
crm(live)resource# migrate vip dd7.example.com
crm(live)resource# status vip
resource vip is running on: dd7.example.com
因为资源对每个节点的倾向性都为0:所有不存在什么回迁
crm(live)resource# unmigrate vip
crm(live)resource# status vip
resource vip is running on: dd7.example.com
crm(live)resource# status vip
resource vip is running on: dd7.example.com
crm(live)configure# primitive webserver lsb:httpd
crm(live)configure# verify
crm(live)configure# commit
查看:对于我们的集群节点来说,尽可能把资源平均分配在各节点上
[root@dd6 html]# crm status
Last updated: Tue Sep 26 10:41:22 2017
Last change: Tue Sep 26 10:41:01 2017 via cibadmin on dd7.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Online: [ dd6.example.com dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd6.example.com
[root@dd6 html]# crm
crm(live)# node
crm(live)node# standby
crm(live)node# exit
bye
[root@dd6 html]# crm status
Last updated: Tue Sep 26 10:45:10 2017
Last change: Tue Sep 26 10:45:02 2017 via crm_attribute on dd6.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Node dd6.example.com: standby
Online: [ dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd7.example.com
[root@dd6 html]# cfrm
-bash: cfrm: command not found
[root@dd6 html]# crm
crm(live)# node
crm(live)node# online
crm(live)node# exit
bye
仍然回到不同的节点:
[root@dd6 html]# crm status
Last updated: Tue Sep 26 10:45:28 2017
Last change: Tue Sep 26 10:45:23 2017 via crm_attribute on dd6.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Online: [ dd6.example.com dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd6.example.com
要让它们在一起怎么办:
crm(live)configure# group webgroup vip webserver
crm(live)configure# verify
crm(live)configure# commit
[root@dd6 html]# crm status
Last updated: Tue Sep 26 10:47:27 2017
Last change: Tue Sep 26 10:47:23 2017 via cibadmin on dd7.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Online: [ dd6.example.com dd7.example.com ]
OFFLINE: [ dd1.example.com ]
Resource Group: webgroup
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd7.example.com
dd6:
crm(live)# node
crm(live)node# standby
[root@dd6 html]# crm status
Last updated: Tue Sep 26 10:48:42 2017
Last change: Tue Sep 26 10:48:38 2017 via crm_attribute on dd7.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Node dd7.example.com: standby
Online: [ dd6.example.com ]
OFFLINE: [ dd1.example.com ]
Resource Group: webgroup
vip (ocf:IPaddr2): Started dd6.example.com
webserver (lsb:httpd): Started dd6.example.com
edit (可直接编译)
delete:直接删除资源 (资源删除之前 要stop)
[root@dd7 html]# crm
crm(live)# configure
crm(live)configure# delete webgroup
ERROR: resource webgroup is running, can’t delete it
crm(live)configure# delete webgroup
ERROR: resource webgroup is running, can’t delete it
crm(live)configure# cd …
crm(live)# resource
crm(live)resource# stop webgroup
crm(live)resource# cd …
crm(live)# configure
crm(live)configure# delete webgroup
crm(live)configure# show
node dd1.example.com
node dd6.example.com
attributes standby=“off”
node dd7.example.com or
attributes standby=“off”
primitive vip ocfIPaddr2
params ip=“172.25.80.120” nic=“eth0” cidr_netmask=“24”
primitive webserver lsb:httpd
property $id=“cib-bootstrap-options”
dc-version=“1.1.10-14.el6-368c726”
cluster-infrastructure=“classic openais (with plugin)”
expected-quorum-votes=“2”
stonith-enabled=“false”
no-quorum-policy=“ignore”
我们删除了组之后,发现它们又运行在不同的节点了,那这个时候,我们还想让他们运行在一起怎么办呢?
定义排列约束:
crm(live)configure# colocation webserver_with_vip inf: webserver vip
crm(live)configure# verify
crm(live)configure# commit
inf (无穷大之意 永远在一起)
顺序约束:
期望资源启动和关闭的约束
Usage:
…
order {kind|}: [:] [:] …
[symmetrical=] #对称 先启动的后关闭 后启动的先关闭
kind :: Mandatory(强制按张我们自己定义的) | Optional(怎么玩都行) | Serialize(串行化)
crm(live)configure# order vip_before_webserver Mandatory(限制): vip webserver
crm(live)configure# verify
crm(live)configure# commit
crm(live)configure# show
node dd1.example.com
node dd6.example.com
attributes standby=“off”
node dd7.example.com
attributes standby=“off”
primitive vip ocfIPaddr2
params ip=“172.25.80.120” nic=“eth0” cidr_netmask=“24”
primitive webserver lsb:httpd
colocation webserver_with_vip inf: webserver vip
order vip_before_webserver Mandatory: vip webserver
property $id=“cib-bootstrap-options”
dc-version=“1.1.10-14.el6-368c726”
cluster-infrastructure=“classic openais (with plugin)”
expected-quorum-votes=“2”
stonith-enabled=“false”
no-quorum-policy=“ignore”
如果我们希望这个资源倾向于一个节点怎么办?(希望运行在dd6上)
localtion:
两种方法:
location vip_on_dd6 vip rule 50: #uname eq dd6.example.com
location vip_on_dd6 vip 50: dd6.example.com
对dd7节点没指定倾向性,则默认为0
dd6 standby
[root@dd7 html]# crm status
Last updated: Tue Sep 26 11:18:50 2017
Last change: Tue Sep 26 11:18:26 2017 via crm_attribute on dd6.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Node dd6.example.com: standby
Online: [ dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd7.example.com
dd6 online
[root@dd7 html]# crm status
^[[ALast updated: Tue Sep 26 11:19:01 2017
Last change: Tue Sep 26 11:18:58 2017 via crm_attribute on dd6.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Online: [ dd6.example.com dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd6.example.com
webserver (lsb:httpd): Started dd6.example.com
但我们不希望它切来切去(不接受勾引)
crm(live)configure# property default-resource-stickiness=
default-resource-stickiness (integer, [0]):
crm(live)configure# property default-resource-stickiness=50
crm(live)configure# verify
crm(live)configure# commit
资源粘性大于倾向性(一个资源50 两个资源100)
dd6 standby
dd6 online
资源不会回切
我们演示一种场景:
我们不小心把正在运行节点上的服务给kill掉,我们发现资源没重启动,也没转移,还以为自己运行的好好的 高可用集群 默认只高可用节点 所有我们要监控
[root@dd7 html]# killall httpd
[root@dd7 html]# killall httpd
httpd: no process killed
[root@dd7 html]# crm status
Last updated: Tue Sep 26 11:26:02 2017
Last change: Tue Sep 26 11:23:11 2017 via crm_attribute on dd6.example.com
Stack: classic openais (with plugin)
Current DC: dd6.example.com - partition with quorum
Version: 1.1.10-14.el6-368c726
3 Nodes configured, 2 expected votes
2 Resources configured
Online: [ dd6.example.com dd7.example.com ]
OFFLINE: [ dd1.example.com ]
vip (ocf:IPaddr2): Started dd7.example.com
webserver (lsb:httpd): Started dd7.example.com
删除之前的操作:(首先stop 资源 )
crm(live)configure# primitive vip ocfIPaddr2 params ip=172.25.80.120 nic=eth0 cidr_netmask=24 op monitor interval=10s timeout=20s
crm(live)configure# verify
crm(live)configure# commit (有可能会有警告)
crm(live)configure# primitive webserver lsb:httpd op monitor interval=10s timeout=20s
crm(live)configure# verify
crm(live)configure# commit
尝试在当前节点重新启动:
[root@dd6 ~]# killall httpd
[root@dd6 ~]# netstat -antlpe|grep httpd
[root@dd6 ~]# netstat -antlpe|grep httpd
[root@dd6 ~]# netstat -antlpe|grep httpd
tcp 0 0 :::80 :: LISTEN 0 17085 3990/httpd
清理出错状态
crm(live)resource# cleanup webserver
Cleaning up webserver on dd6.example.com
Cleaning up webserver on dd7.example.com
Waiting for 1 replies from the CRMd. OK
添加存储:(这次我们玩一个新的 NFS 对外提供访问其文件系统的接口)
再开一台虚拟机:此时我们用dd5.example.com 注意hosts文件里面要有解析
yum install nfs-utils rpcbind -y
/etc/init.d/rpcbind start
/etc/init.d/nfs start
mkdir -p /web/htdocs
ll -d /web/htdocs/
chmod o+w /web/htdocs/
ll -d /web/htdocs/
vim /etc/exports
/web/htdocs 172.25.80.0/24(rw)
exportfs -r
showmount -e
cd /web/htdocs/
vim index.html
测试,dd6 dd7能否挂载:
mount -t nfs 172.25.80.15:/web/htdocs /mnt
Filesystem三个参数:
info ocfFilesystem
device* (string): block device
The name of block device for the filesystem, or -U, -L options for mount, or NFS mount specification.
directory* (string): mount point
The mount point for the filesystem.
fstype* (string): filesystem type
The type of filesystem to be mounted
带*号必选
注意 看一下官方给的默认监控参数,如果比官方小的话,会有警告
crm(live)configure# primitive webdata ocfFilesystem params device=“172.25.80.15:/web/htdocs” directory="/var/www/html" fstype=“nfs” op monitor interval=20s
将资源加到资源组里面
为了方便我们直接edit
group webgroup vip webserver webdata
然后启动资源
然后测试 节点standby
注意:经常清理报错信息(要不会对之后的操作有影响)
crm_mon (同步监控)
configure
show
property stonith-enabled=false (关闭fence) //因为启动的时候报错 说没有找到fence,手动关闭fence
commit(一定要保存)
primitive vip ocfIPaddr2 params ip=172.25.42.200 cidr_netmask=24
commit
primitive apache lsb:httpd op monitor interval=10s
commint
group website vip apache (使服务和正在工作的节点绑定)
commit
如果此时停掉一台虚拟机上的 corosync 服务 会发现 另一台也不工作 这是因为 corosync 自带的健康检查(认为这是两个节点的集群) 如果它检查到一台挂掉 就会认为 这个集群挂掉了
property no-quorum-policy=ignore
pacemaker+fence:
真机:
[root@foundation0 cluster]# systemctl status fence_virtd.service
● fence_virtd.service - Fence-Virt system host daemon
Loaded: loaded (/usr/lib/systemd/system/fence_virtd.service; disabled; vendor preset: disabled)
Active: active (running) since Sun 2019-04-14 10:56:47 CST; 6min ago
Process: 7849 ExecStart=/usr/sbin/fence_virtd $FENCE_VIRTD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 7854 (fence_virtd)
CGroup: /system.slice/fence_virtd.service
└─7854 /usr/sbin/fence_virtd -w
Apr 14 10:56:47 foundation0.ilt.example.com systemd[1]: Starting Fence-Virt s…
Apr 14 10:56:47 foundation0.ilt.example.com fence_virtd[7854]: fence_virtd st…
Apr 14 10:56:47 foundation0.ilt.example.com systemd[1]: Started Fence-Virt sy…
Hint: Some lines were ellipsized, use -l to show in full.
[root@foundation0 cluster]# systemctl restart fence_virtd.service
cd /etc/cluster/
dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
scp fence_xvm.key root@172.25.0.1:/etc/cluster/
scp fence_xvm.key root@172.25.0.2:/etc/cluster/
测试虚拟机:server1 server2
mkdir /etc/cluster
一定要注意:在做fence之前 我们的httpd资源一定要由监控
fence:(检查之前配置的fence 两个虚拟机 mkdir /etc/cluster 物理机发送key)
stonith_admin -I
yum provides */fence_xvm
yum install fence-virt-0.2.3-15.el6.x86_64
property stonith-enabled=true
注意:以上两个操作一定要在两台虚拟机上都完成
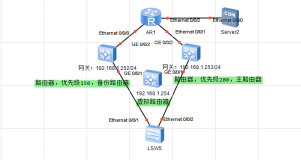
primitive vmfence stonith:fence_xvm params pcmk_host_map=“server2:server2;server3:server3” op monitor interval=1min (最好做监控)
注意注意:一定要注意的是:
server2:server2 冒号前面的是hostname 冒号后面的是物理机的名字(有可能学生的虚拟机名字和主机名字不一样)
Online: [ server2 server3 ]
Resource Group: website
vip (ocf:IPaddr2): Started server3
apache (lsb:httpd): Started server3
vmfence (stonith:fence_xvm): Started server2
fence应该和资源不在同一台主机上
测试:
/etc/init.d/httpd stop 发现 自己开启
echo c > /proc/sysrq-trigger
/etc/init.d/network stop
注意 corosync服务一定要开机自启
chkconfig corosync on
[root@server2 ~]# crm
crm(live)# configure
crm(live)configure# show
node server2
node server3
primitive apache lsb:httpd
op monitor interval=“10s”
primitive vip ocfIPaddr2
params ip=“172.25.0.200” cidr_netmask=“24”
primitive vmfence stonith:fence_xvm
params pcmk_host_map=“server2:server2;server3:server3”
op monitor interval=“1min”
group website vip apache
meta target-role=“Started”
property $id=“cib-bootstrap-options”
dc-version=“1.1.10-14.el6-368c726”
cluster-infrastructure=“classic openais (with plugin)”
expected-quorum-votes=“2”
stonith-enabled=“true”
no-quorum-policy=“ignore”
作者:若无其事的苹果
来源:CSDN
原文:https://blog.csdn.net/qq_36016375/article/details/94916165
版权声明:本文为博主原创文章,转载请附上博文链接!