上一章介绍了万金油特征MFCC,相当于数据的输入已经确定了。 本章尽可能的介绍经典asr做法。其中涉及到的各种概念和思考,了解了之后,和相关专业的人交流,大概就不再迷茫了:D
传统方法也可以按 声学模型 和 语言学模型 的方式来划分。
声学模型主要的职责是,把一段音频处理成类似拼音的形式, 然后交给语言模型来猜: 能够发这些音的单词,怎么组合起来更常见一些。然后找到最可能的组合,便是asr的结果了。
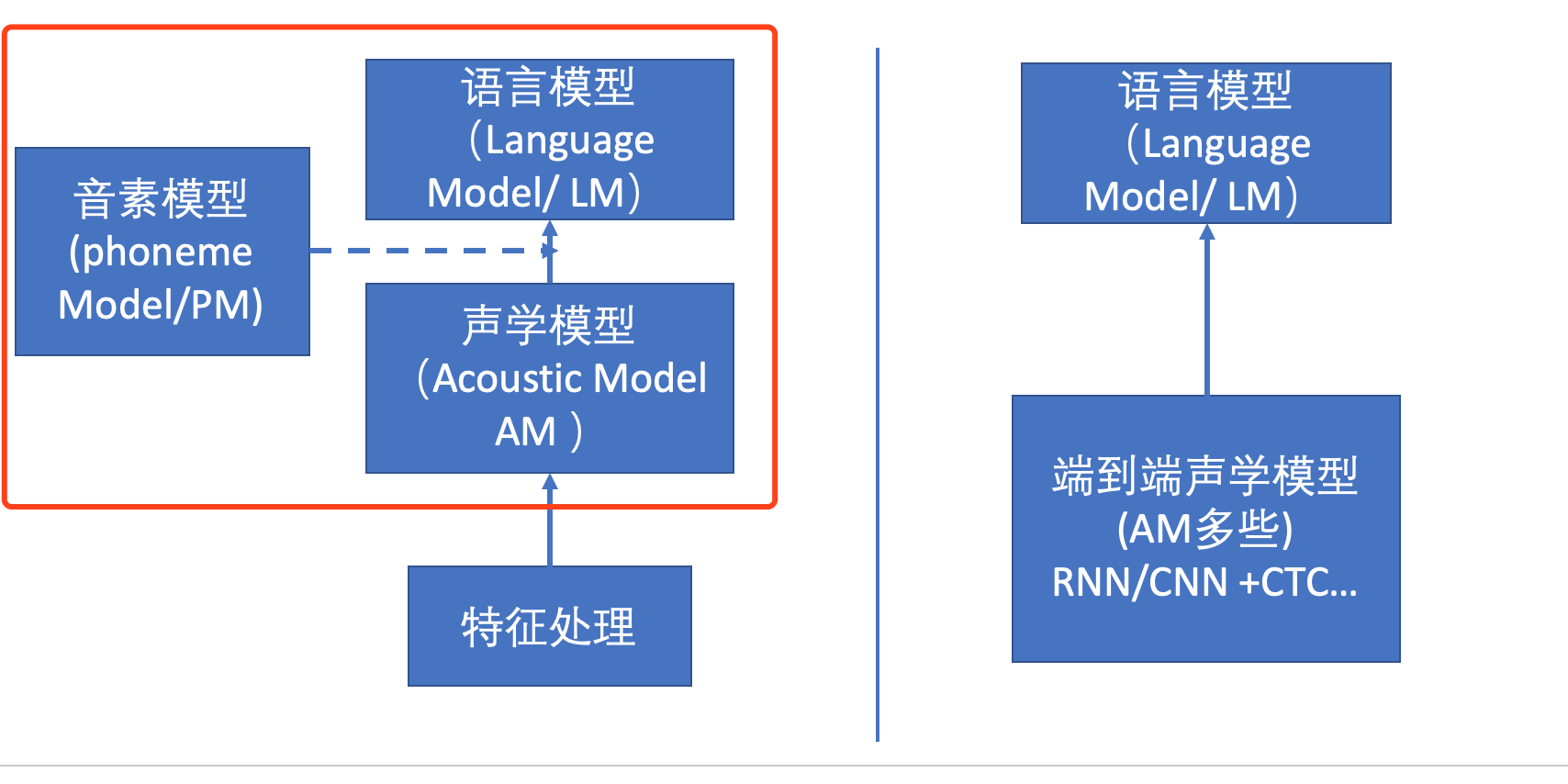
本章介绍的,其实是下图左侧的部分。
一、术语定义
介绍一个概念前,首先要把它依赖的术语说明白,其实asr领域的术语定义并不复杂,反而非常符合直观感觉。换句话说,定义基本是一眼就明白意思并且觉得没有毛病的样子。
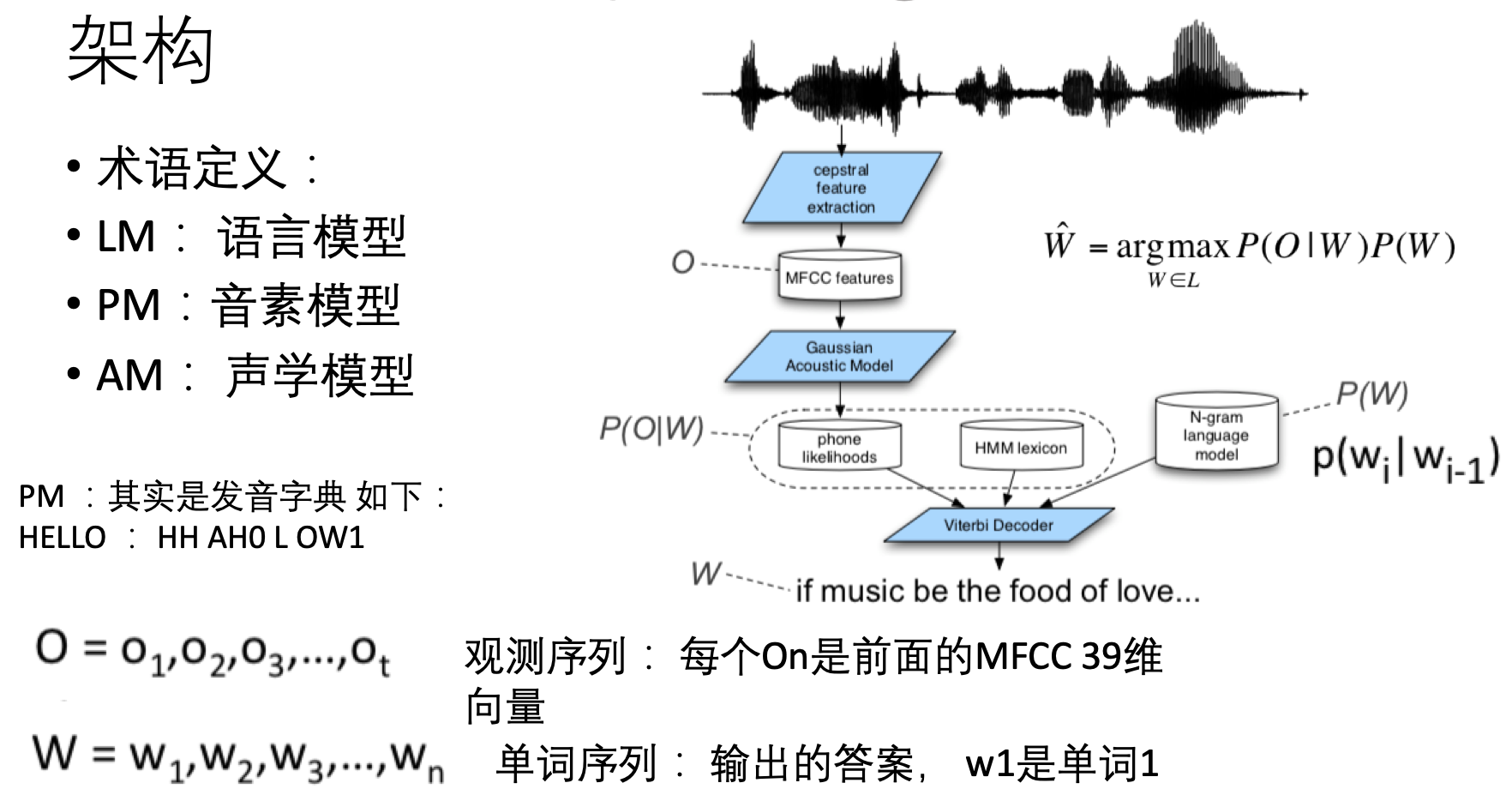
上图右侧是传统模型的大致处理流程。里面用到的术语基本都在左侧介绍了。架构解释了整体的处理逻辑: 已知一句话中的一系列单词W ,在MFCC发音序列下的概率分布情况P(O|W),又已知这句话本身的概率大小P(W), 那么二者相乘便是—— 这句话 发音 成 观测序列O 的概率。 那么如果知道所有的句子W‘ 对应的产生O的概率,找到最大的那个,此时的W很可能就是这段声音对应的文本了。
上面要注意的是,传统处理逻辑中,声学模型和语言模型之外,还多了个PM——音素模型。 这其实是个折衷。 语言模型的输出结果其实是一个个音素,可以理解为够成单词完整发音的基本组成单位。 1个或多个音素可以组成一个单词。 这里声学模型为什么不直接给出单词的发音呢? 因为单词的发音量基本是有多少单词就有多少种发音,种类太多了。 而音素就很少,算法代价很低。 而PM本身就不复杂了, 就是个map,类似查表,告诉你那几个音素放一起对应着哪个单词。
二 HMM
HMM是隐式马尔科夫模型的缩写。 在把HMM引入asr领域前,大名鼎鼎的贝尔实验室曾表示——根据声音来确定对应的文本,如同在大海里找一粒沙。。 基本不可能实现。 而HMM引入后,尤其是李开复最初搞的sphinx,一下子把准确率提升到了70%左右的水准。 之后有了深度模型之后,就提到了现在的95%,基本可商用化的地步。但相对于深度模型,HMM还是依靠着其简单粗暴可控等优良特性,可以短平快的处理不少事。 不仅仅是用在asr领域,炒股、做预测、搞多轮对话,基本都能使。
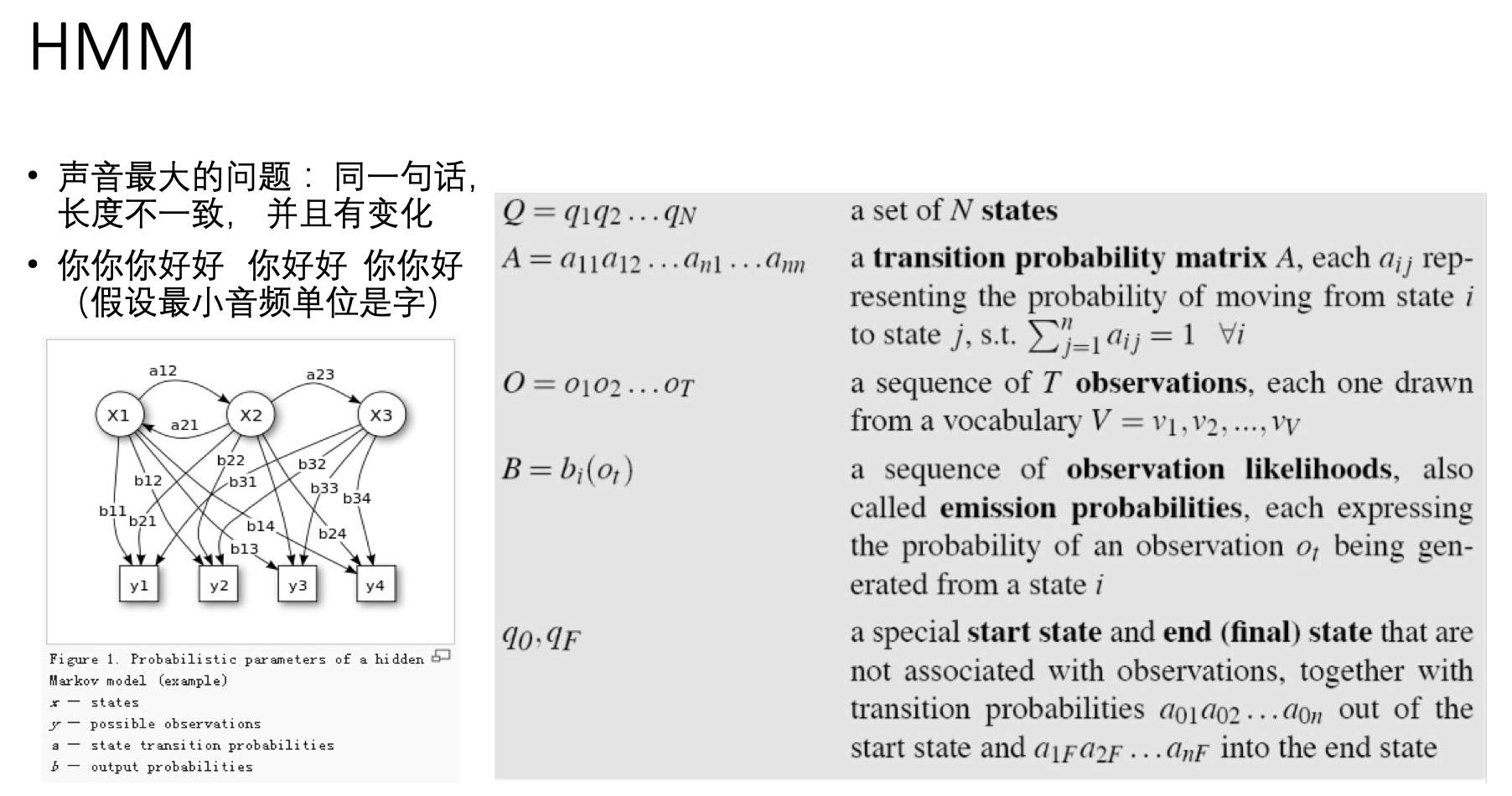
简单描述,以上图举例,假设小明有 吃冰淇淋(y1) 吃火锅(y2) 吃樱桃(y3) 吃柿子(y4) 四种表现, HMM假设这四种表现与3种(3是我们猜的)我们未知的状态有关:x1(可能是感觉很热) x2(可能是感觉很凉) x3(可能是再也不关心凉热了) , 每个状态均可以产生这4种表现 , 只是每种状态下,四种表现的概率不同(比如,x1 下 y1的概率就明显高b11的概率值高)。然后呢,这3中隐藏的状态直接也是可以互相转换的(图中边 a12 a21... ),但转换的概率不一样,比如,x1 比较容易和x2互相转换。 —— 如此一番假设后,加入假设成立,那么当我们得知了上图中各个箭头的概率值之后,就可以预测小明接下来是要吃冰淇淋还是吃樱桃了。 或者,当我们已经得知了小明的一些列表现,就能猜出起内在心态(x)经历了哪些变化。 后者,便是语音识别的原理了—— 当我们知道一系列发音的表现O之后,要猜说话人到底说了哪些音素( decoding 问题)。
给定一段音频的观测序列,比如 根据例子图中的 y1->y2->y4 得出小明的内心状态可能是经历了(x1->x2->x3 or x1->x2->x2,假设两条路径生成表现 y1->y2->y4的概率相同)。假设x是各个音素, 然后根据状态转移路径(比如 x1->x2->x3), 再把音素还原成单词,就得到了asr的结果了。
由于网上关于HMM模型的描述已经很多,知乎上很多大拿也解释得相当接地气了。这里就不再细说。有兴趣的同学可以自行百度下。
所以,通过上面的描述,我们可以得知,经典的asr任务,是在HMM的假设框架下,求出里面的 a 和 b两类边的概率值,然后使用它们。 接下来就分别就 a 类边(状态转移概率)和b类边(观测概率)的概率值的求解和使用分别来介绍。
三 状态转移概率的使用及语言模型的加入
这里不介绍状态转移概率的求解了,熟悉HMM的同学很容易就能发现求解的方法,很直白,就是给定按音素state标注好了的语料,然后使用HMM的官方求解方法,直接train就好了。
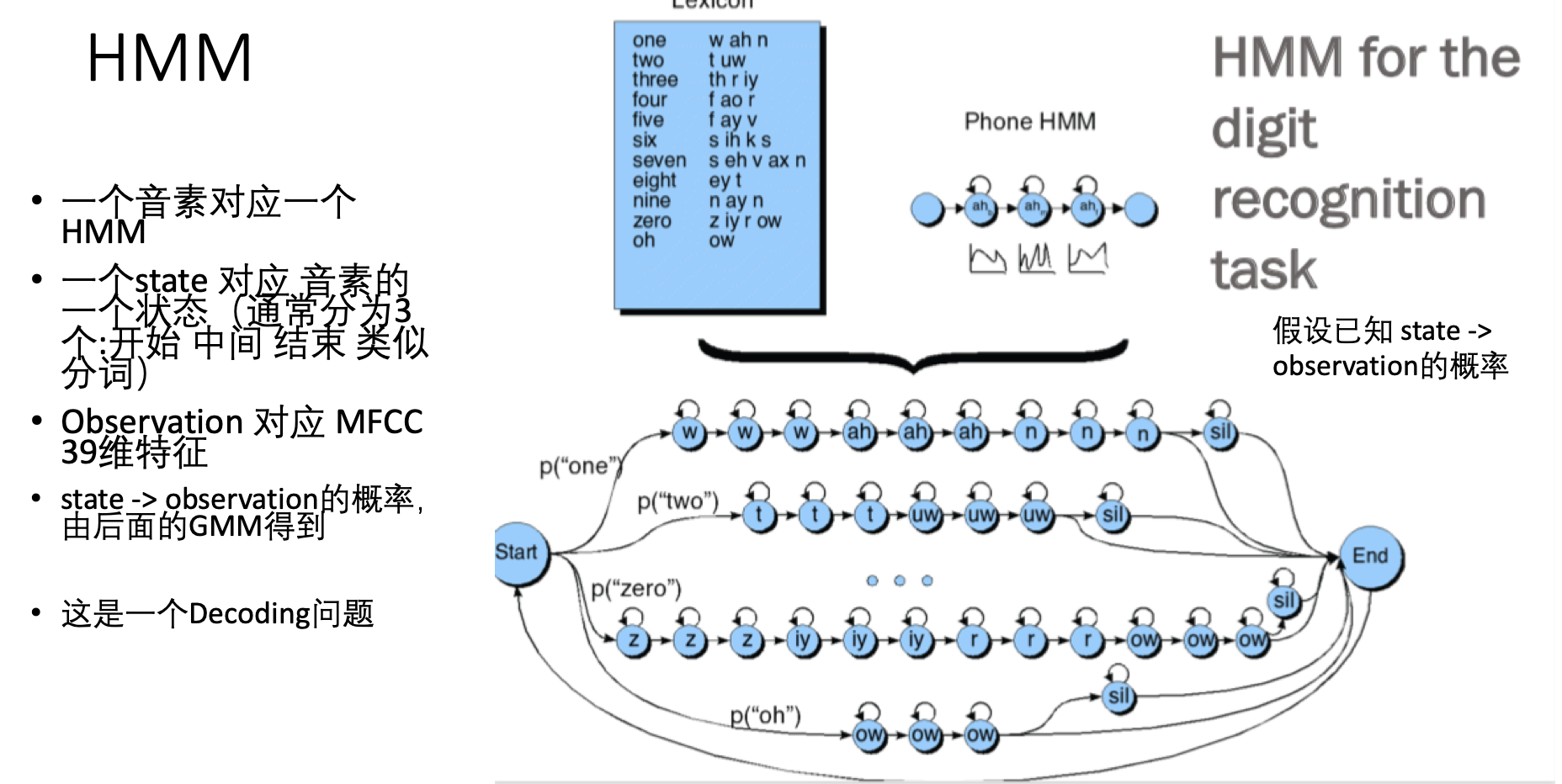
实际处理中,人们对声音的区分粒度显然比音素还要细,实际上,经常将音素分为多个state,然后每个state又分为: 发音开始,发音中间 以及 发音后期 3个部分。如下图(这里没有画出 上图中的y1 y2 y..):
但这里有个问题是,概率毕竟是概率,谁也没说,概率最大的那个状态路径上的值就是真实的情况。 这时问题就来了—— 可能那种总体概率稍微低一些的路径,也是要考虑的。 但是怎么考虑才能计算起来比较快呢? —— 维特比搜索
下图右侧,最底下一行是观测结果,每个观测结果o上面对应着可能产生它的隐藏状态q,所谓搜索路径,就是我要猜,到底怎样的q的组合能够较大概率的生成o的这种排序情况:
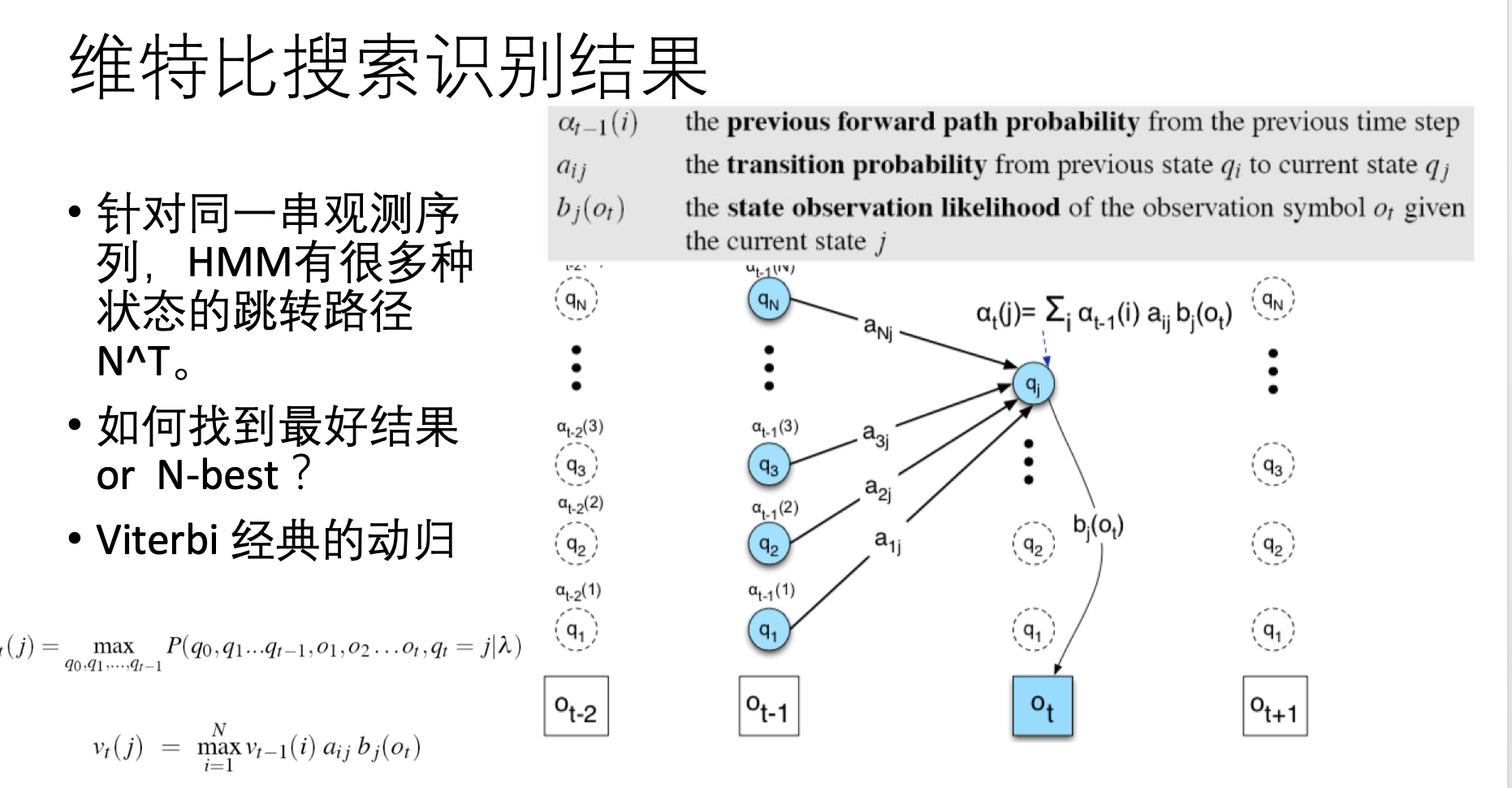
维特比算法的解决方案可以类比经典的工厂装配线动归问题。或者说LeetCode典型算法题,就是教科书上常用的例子。
加入语言模型
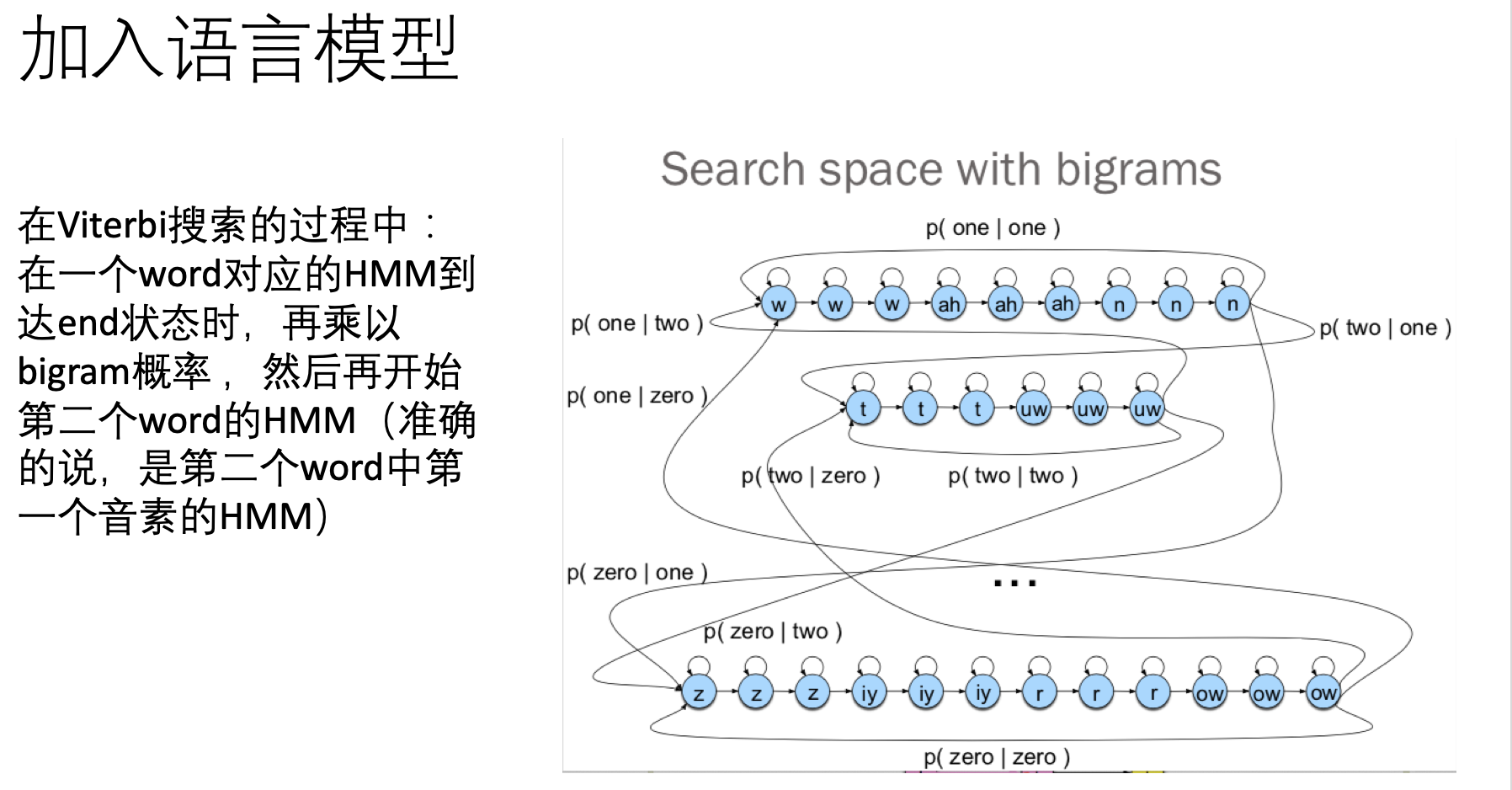
讲到这里,需要额外提及的一点是: 语言模型的结果是怎么加入进来的呢?
所谓的语言模型,就是给定一句话的第一个单词,这个模型会告诉你第二个单词的概率分布是怎样的;给定前两个单词,它会告诉你第三个单词的概率分布是怎样的。 或者说,就是接下来你挑哪个单词和前面的单词放在一起,看起来最像人话。。 最简单的语言模型—— bigram, 就是统计一大堆语料,把单词按滑动窗口两两组合, 计算前一个单词是w1 ,后面紧跟着w2的情况占所有前面是w1的组合的比例。 下图右侧实例从上往下看。描述的是 one two three 这句话加入语言模型后的判别方式。
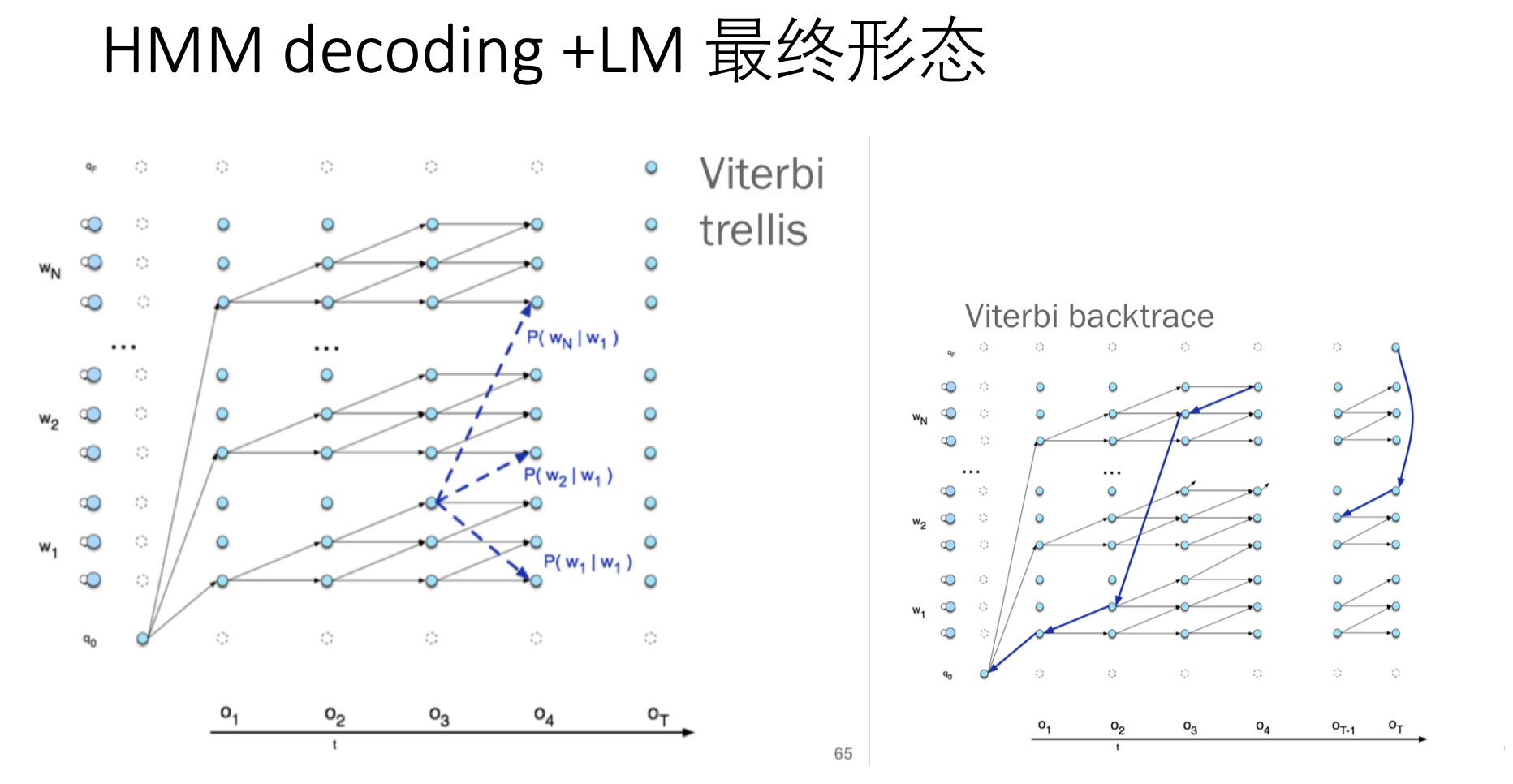
这里给出个总结性的最终形态(熟悉HMM的同学根据图述直接看懂问题不大):
其实是所有音素的HMM的 state是放在一起进行预测的 下图中的w可以理解为 音素 这里是把音素等价为 word 。
接下来做一下延伸:
AM 与 LM之间的权重问题
关于LM 与AM之间的权重问题, 既然这是两个模型,各自有各自的概率值,那么就自然存在着度量衡的问题。 同样是 0.5的概率, LanguageModel 和 Acoustic model,谁的0.5更重要? 解决方法自然是其中一个的概率再乘以一个系数了。。

解码过程中,面临的速度问题。
首先是上面提到的,我们最终要找的路径不止一条的话,那么怎么才能较快的找到其他几个概率值较高的路径呢? 一个是 bean search 一个是 viterbi beam search:

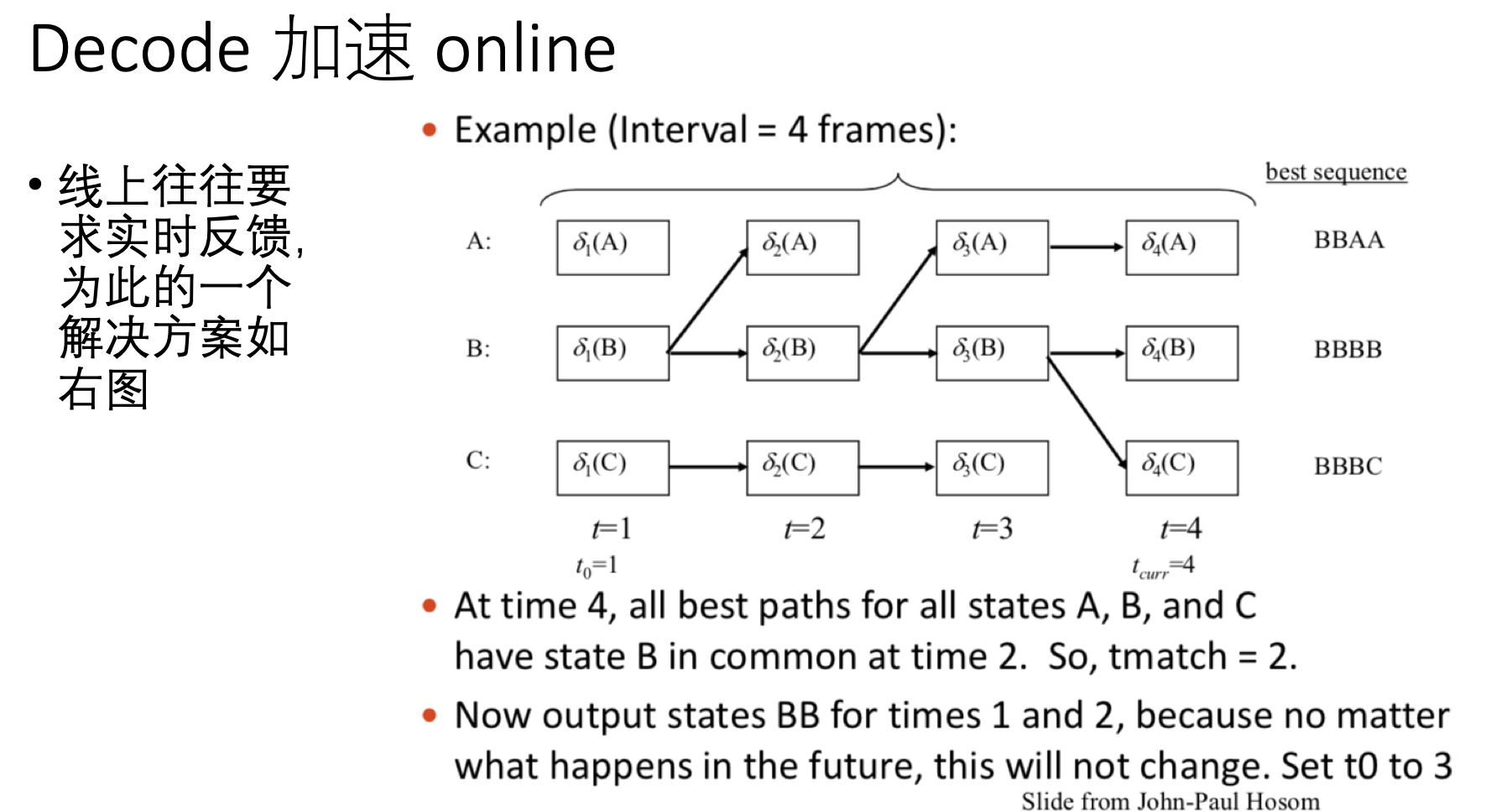
在线实时asr识别
除了速度之外,大家还留意到, 像搜狗输入法和讯飞输入法, 其 语音输入功能是实时输入文本的,并不是等你完全说完一句话才把文本解析出来。 而根据上面所提的方案,似乎得整句话ok了才能得到最终答案(LM的关系)。 事实上也是, 大家会留意到,你一句话说完的时候,这些输入法的答案可能会变, 这就是个直接证据。 但这并不妨碍实时的结果显示。 下面就是一种解决方案:
DFA优化
另一个加速方法,其实可以猜到。 既然上面已经把识别的过程看成是一个个状态的跳转了。 状态的跳转让人想到了 DFA ,有穷状态自动机。 那么自然就可以使用状态自动机的优化技术,把冗余的状态去掉。这样计算量自然也就降低了。
四 、观测概率(b 概率)的求解和使用
三 中讲了 a类概率的求解,而,根据一个观测的表现(即上一章提到的一个MFCC39维特征),它对应的音素的state的概率是多少呢? ,或者说,给定一个音素的state,其生成这个MFCC39维向量的音频的概率是多少呢?
为了求得这部分的概率,人们又再次细化模型假设,引入了另一个模型来求解这部分的值——GMM(高斯混合聚类模型)。
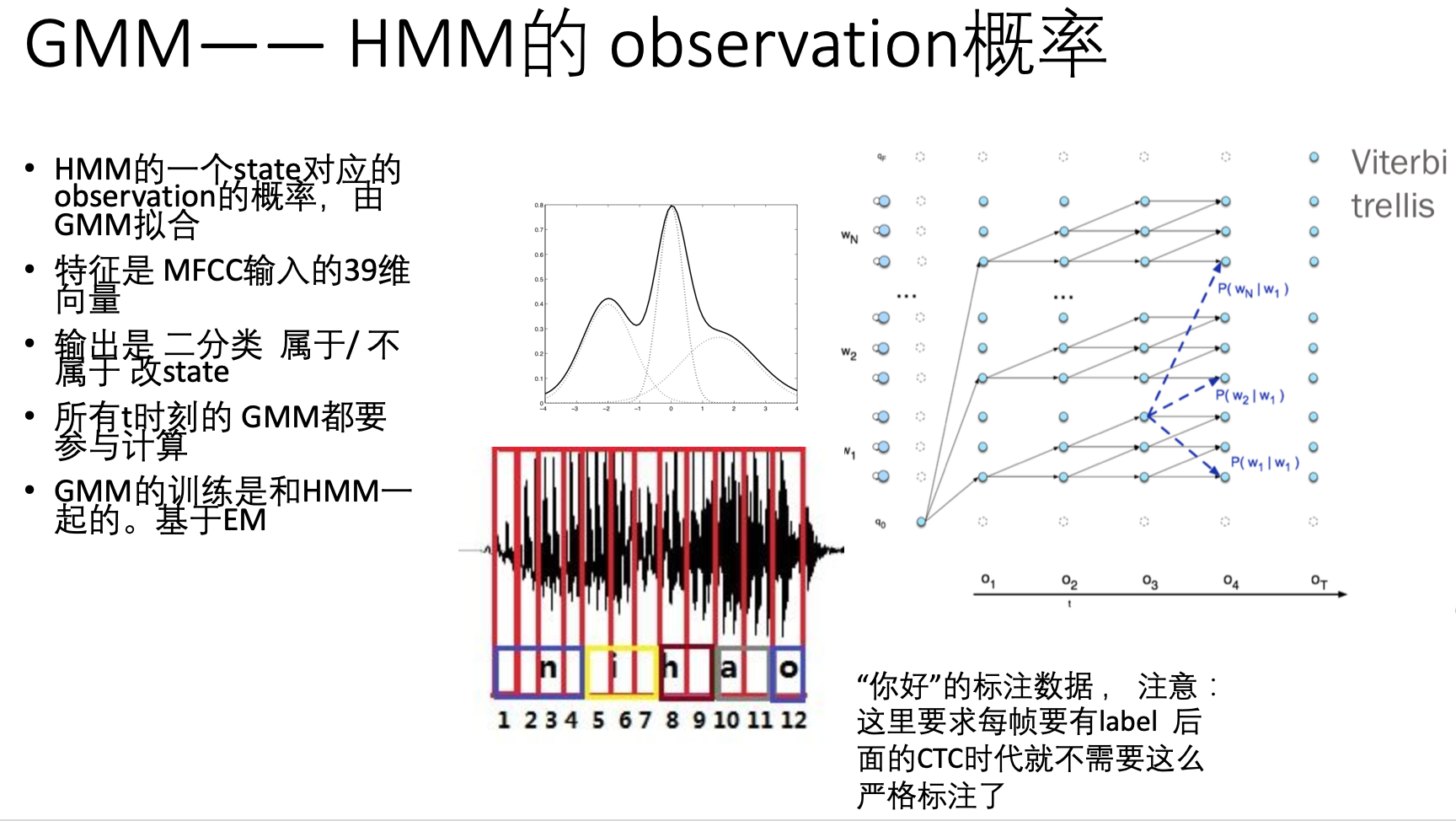
GMM模型的原理很简单。 它是由多个高斯模型组成的。 而高斯模型就是概率论最长提到的正态分布了。 不得不说,自然界的很多现象,比如考试成绩,比如工厂生产钢管的口径,量大了之后,都符合高斯分布。 即大概率是一个标准值,但多少有些误差。 那么声音特征自然也是,发 a 音的声音大致都是那么回事,但细微会有些差别。
然后为什么用多个高斯模型呢? 主要是防止假设的太理想化。 发音大致是那么回事,可是“那么回事” 本身是很难用数学语言准确定义的。 这个现象本身可能是多个子现象的综合表现。 那么每个子现象可能是个高斯分布。
考虑上下文的GMM
前面提到过,将音素对应为3个state ,然后每个state通过一个GMM来建立起和MFCC特征之间的关系。
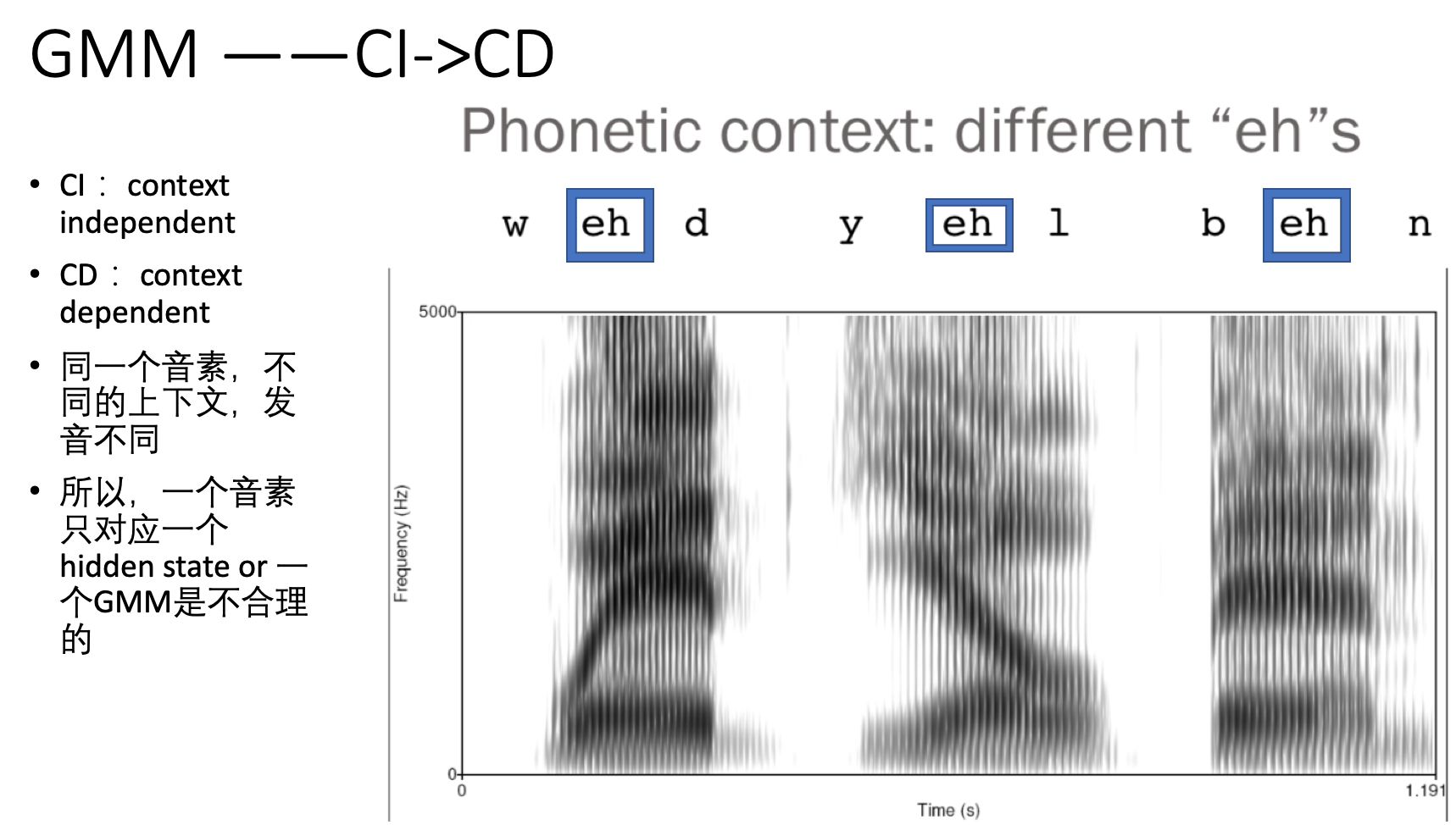
但在追求asr精度的过程中,人们不得不进一步细化问题的求解。 首先: “将一个音素对应为3个state”本身就值得细化—— 同一个音素,不同的上下文,其发音是可以不同的, 比如 同样是“a” ,有念“啊”,有时有时"爱"。 这么一来,一个音素只对应一个hidden state or 一个 GMM自然也就不合理了。 如下图:
GM 模型是不断发展的,最开始是HMM的一个state只对应一个音素,后来是一个音素根据发声位置不同,分为3个state,后来又发展,因为音素的发声还和上下文有关
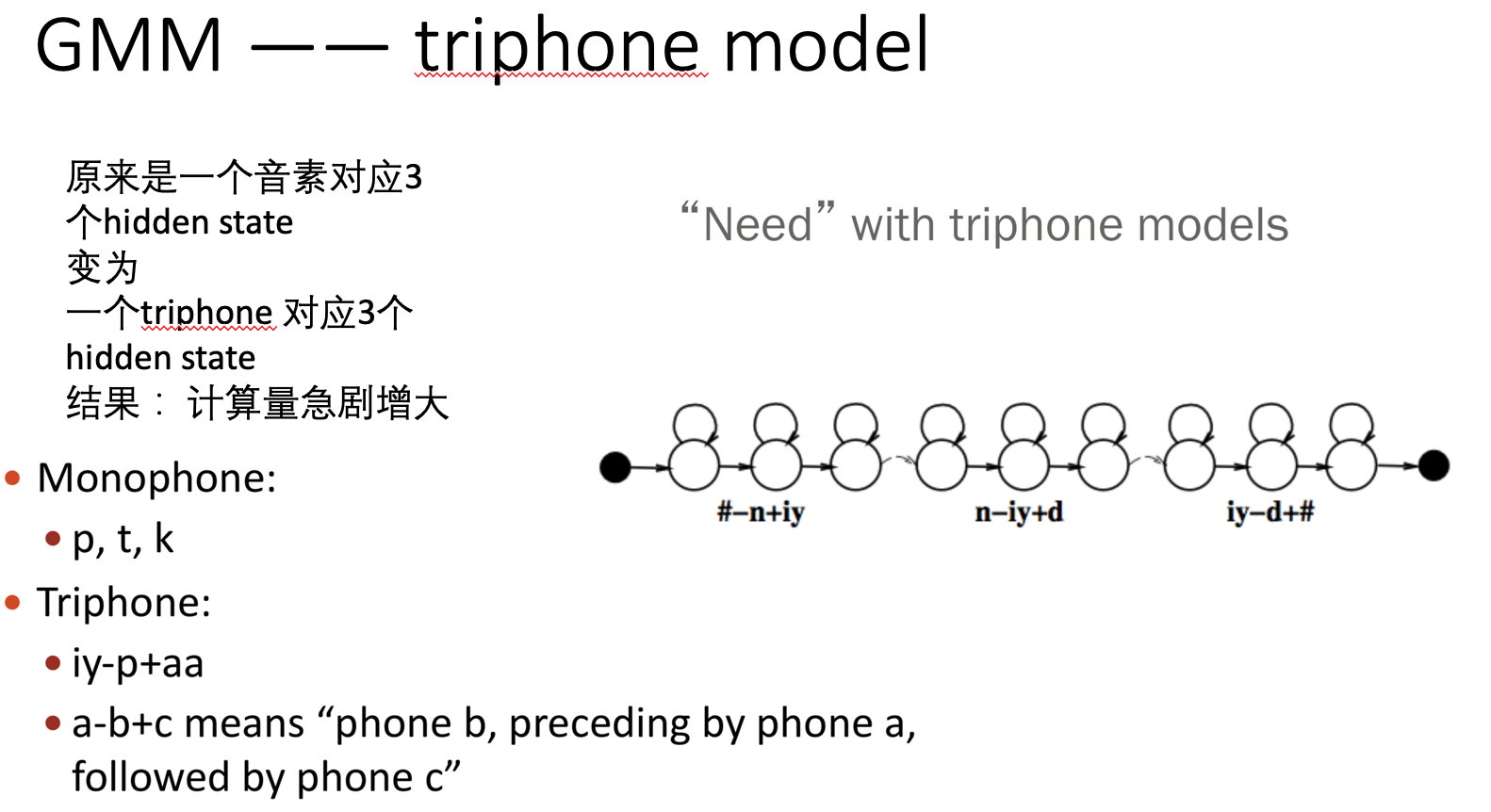
针对上述问题,人们提出了一个解决方案, 很类似自然语言领域的trigram(前面提到过bigram,这里可以同理类推) triphone model: 就是把三个音素的组合作为新的一个case来处理。这样的坏处也很明显,之前是 n个音素的计算量,现在是 n^3的计算量了(虽然没那么过分)。
triphone 的合并 —— State Tying
提出了triphone之后,紧接着又来了一个问题:

如上图所示,如果允许triphone跨单词存在,那么复杂度就进一步增加了,而且,训练的语料也不够了:

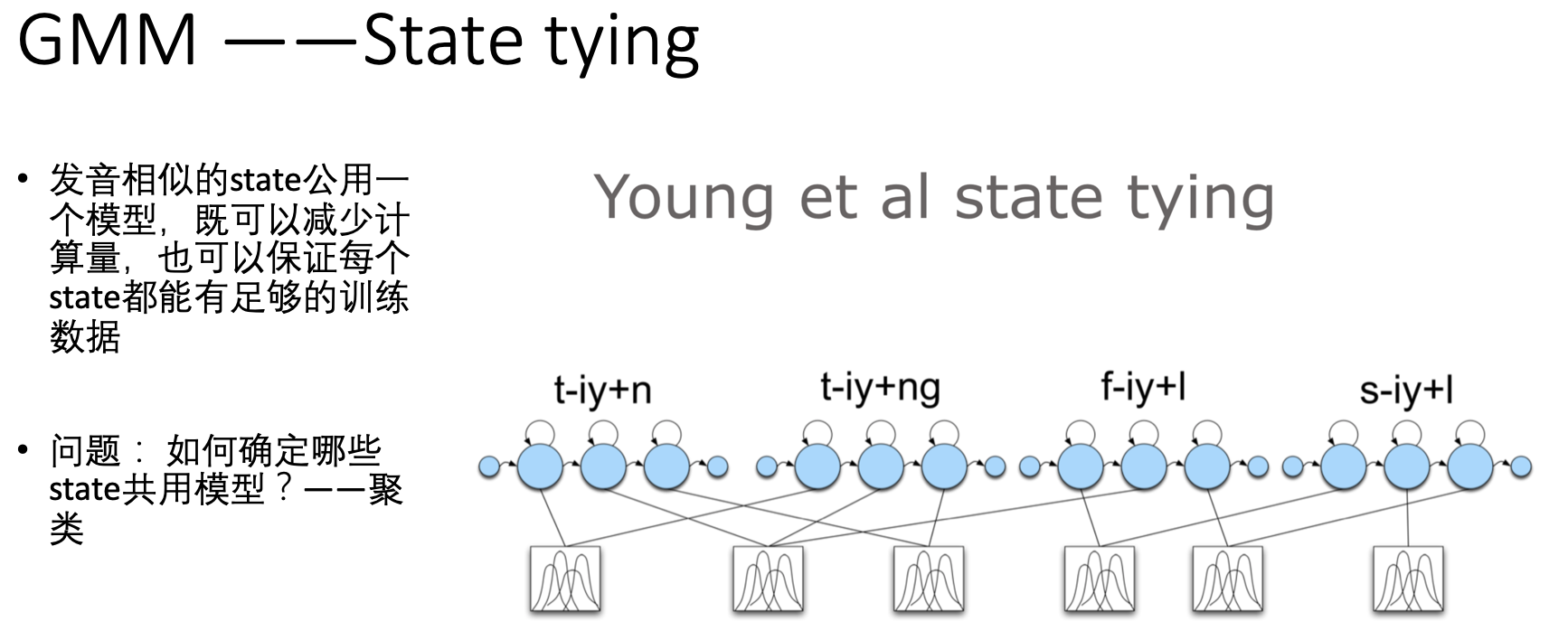
在上述情况下,triphone很多种,给每一种配一些列的GMM不太现实。 但很多事情 分分和和, 于是又提出了合并的解决方案——generalize model 。 就是把上面复杂到爆的triphone ,对发音相似的,就公用一个GMM:state tying

既然上图提到的state tying 看起来是个解决方案,那么问题来了,怎么找到相似的state 呢? —— 聚类:
聚类主要使用的是决策树的方式,效果如下图,值的一提的是,这些决策树中的条件判断,多是人工指定的,这里又涉及到了很多语音学的知识。
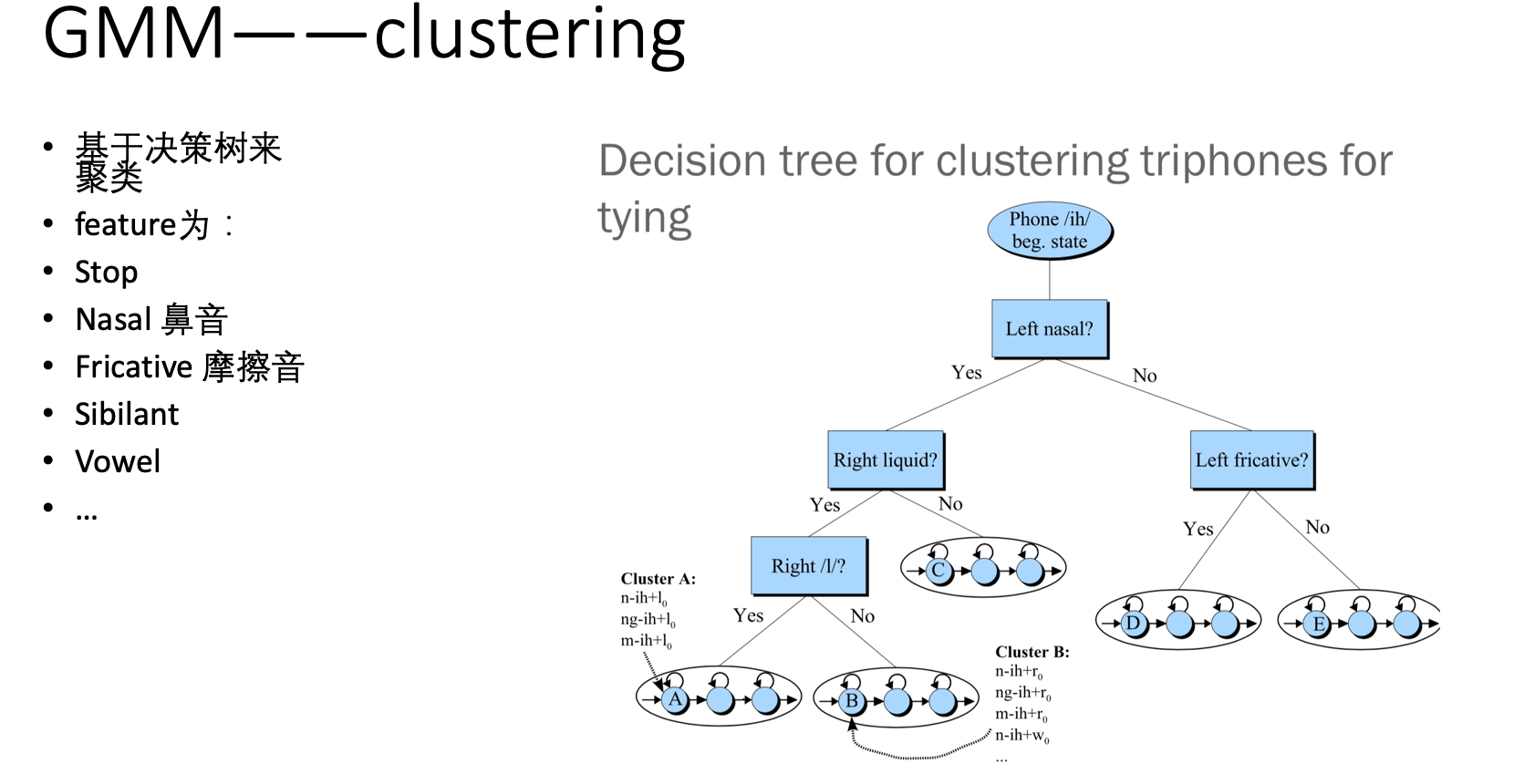
下面给出
上述操作的一个具体的流程:
首先,先不管triphone的情况,先就只针对每个音素的state 训练好高斯模型。 然后再映射为triphone,triphone使用 mononphone的结果作为初始状态。紧接着对triphone进行聚类,相似的state共享一个高斯模型。之后,扩展高斯模型,变成GMM,真正训练:
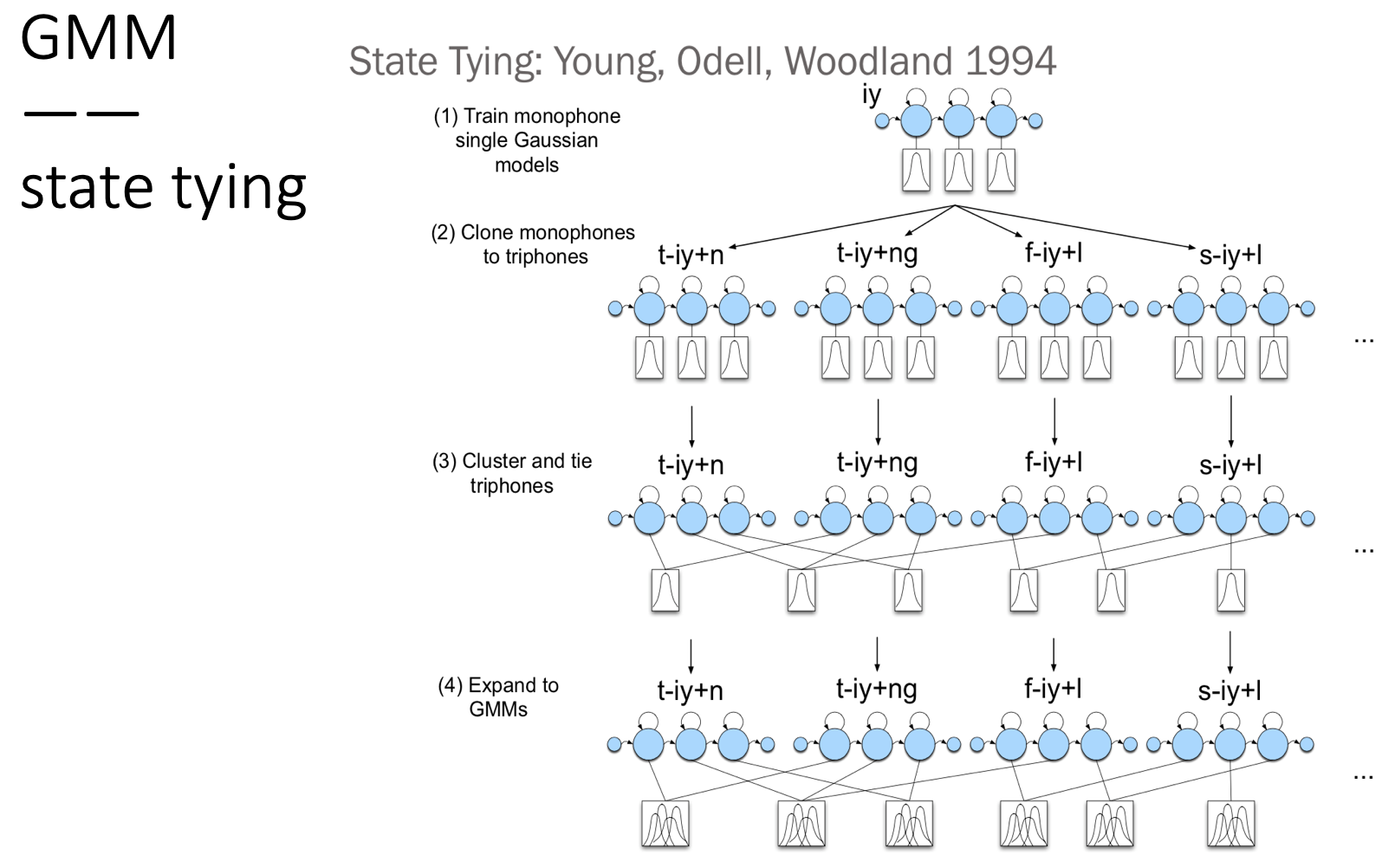
接下来提一下
小预料的适应问题

五 评价准则
紧跟着来个 asr模型好坏的评价准则(也是比较容易理解,就是edit distance 比上所有要预测的单词的数目):

以上便是传统的asr处理步骤了。 接下来会介绍现代化的处理方式。


