前言
在架构篇中我们介绍了现代IM消息系统的架构,介绍了Timeline的抽象模型以及基于Timeline模型构建的一个支持『消息漫游』、『多端同步』和『消息检索』多种高级功能的消息系统的典型架构。架构篇中为了简化读者对Tablestore Timeline模型的理解,概要性的对Timeline的基本逻辑模型做了介绍,以及对消息系统中消息的多种同步模式、存储和索引的基本概念做了一个科普。
本篇文章是对架构篇的一个补充,会对Tablestore的Timeline模型做一个非常详尽的解读,让读者能够深入到实现层面了解Timeline的基本功能以及核心组件。最后我们还是会基于IM消息系统这个场景,来看如何基于Tablestore Timeline实现IM场景下消息同步、存储和索引等基本功能。
Timeline模型
Timeline模型以『简单』为设计目标,核心模块构成比较清晰明了,主要包括:
- Store:Timeline存储库,类似数据库的表的概念。
- Identifier:用于区分Timeline的唯一标识。
- Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。
- Queue:一个Timeline内所有Message存储在Queue内。
- Message:Timeline内传递的消息体,也是一个free-schema的结构,可自由包含任意列。
- Index:包含Meta Index和Message Index,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
Timeline Store
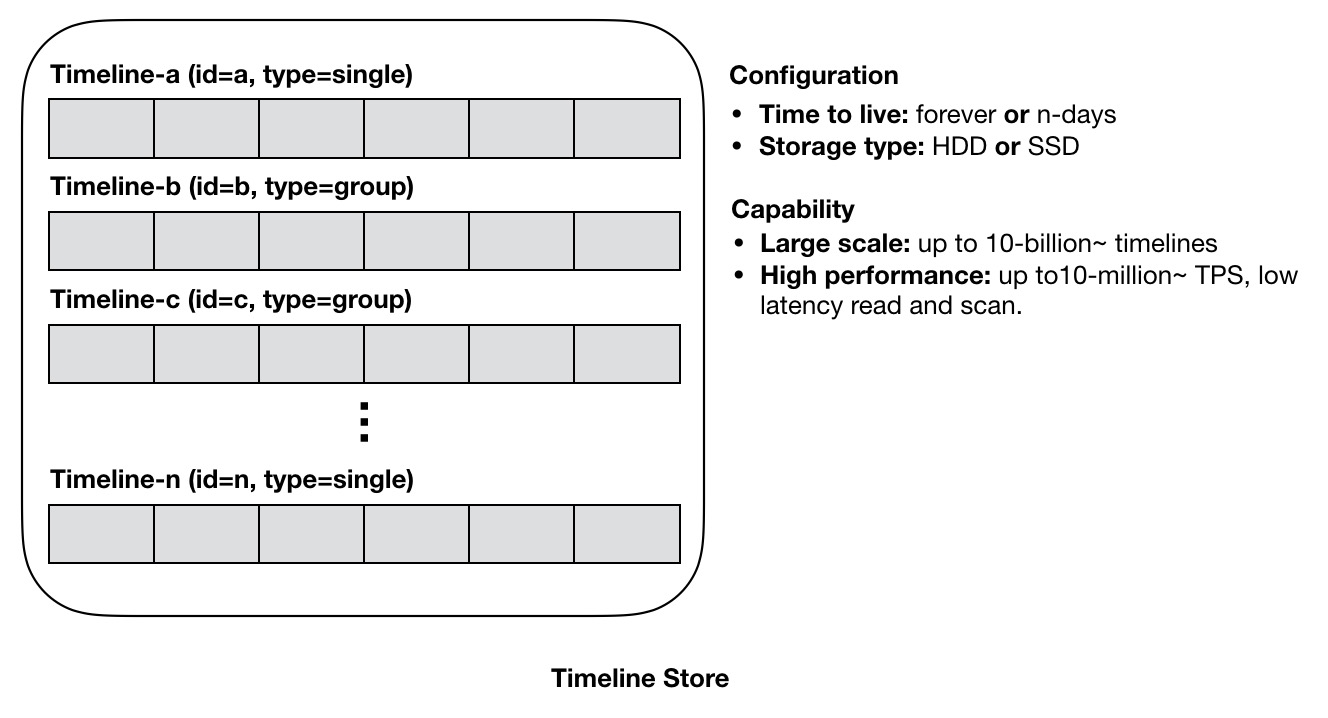
Timeline Store是Timeline的存储库,对应于数据库内表的概念。上图是Timeline Store的结构图,Store内会存储所有的Timeline数据。Timeline是一个面向海量消息的数据模型,同时用于消息存储库和同步库,需要满足多种要求:
- 支撑海量数据存储:对于消息存储库来说,如果需要消息永久存储,则随着时间的积累,数据规模会越来越大,需要存储库能应对长时间积累的海量消息数据存储,需要能达到PB级容量。
- 低存储成本:消息数据的冷热区分是很明显的,大部分查询都会集中在热数据,所以对于冷数据需要有一个比较低成本的存储方式,否则随着时间的积累数据量不断膨胀,存储成本会非常大。
- 数据生命周期管理:不管是对于消息数据的存储还是同步,数据都需要定义生命周期。存储库是用于在线存储消息数据本身,通常需要设定一个较长周期的保存时间。而同步库是用于写扩散模式的在线或离线推送,通常设定一个较短的保存时间。
- 极高的写入吞吐:各类场景下的消息系统,除了类似微博、头条这种类型的Feeds流系统,像绝大部分即时通讯或朋友圈这类消息场景,通常是采用写扩散的消息同步模式,写扩散要求底层存储具备极高的写入吞吐能力,以应对消息洪峰。
- 低延迟的读:消息系统通常是应用在在线场景,所以对于查询要求低延迟。
Tablestore Timeline的底层是基于LSM存储引擎的分布式数据库,LSM的最大优势就是对写入非常友好,天然适合消息写扩散的模式。同时对查询也做了极大优化,例如热数据进缓存、bloom filter等等。数据表采用Range Partition的分区模式,能提供水平扩展的服务能力,以及能自动探测并处理热点分区的负载均衡策略。为了满足同步库和存储库对存储的不同要求,也提供了一些灵活的自定义配置,主要包括:
- Time to live(数据生命周期):可自定义数据生命周期,例如永久保存,或者保存N天。
- Storage type(存储类型):自定义存储类型,对存储库来说,HDD是最好的选择,对同步库来说,SSD是最好的选择。
Timeline Module
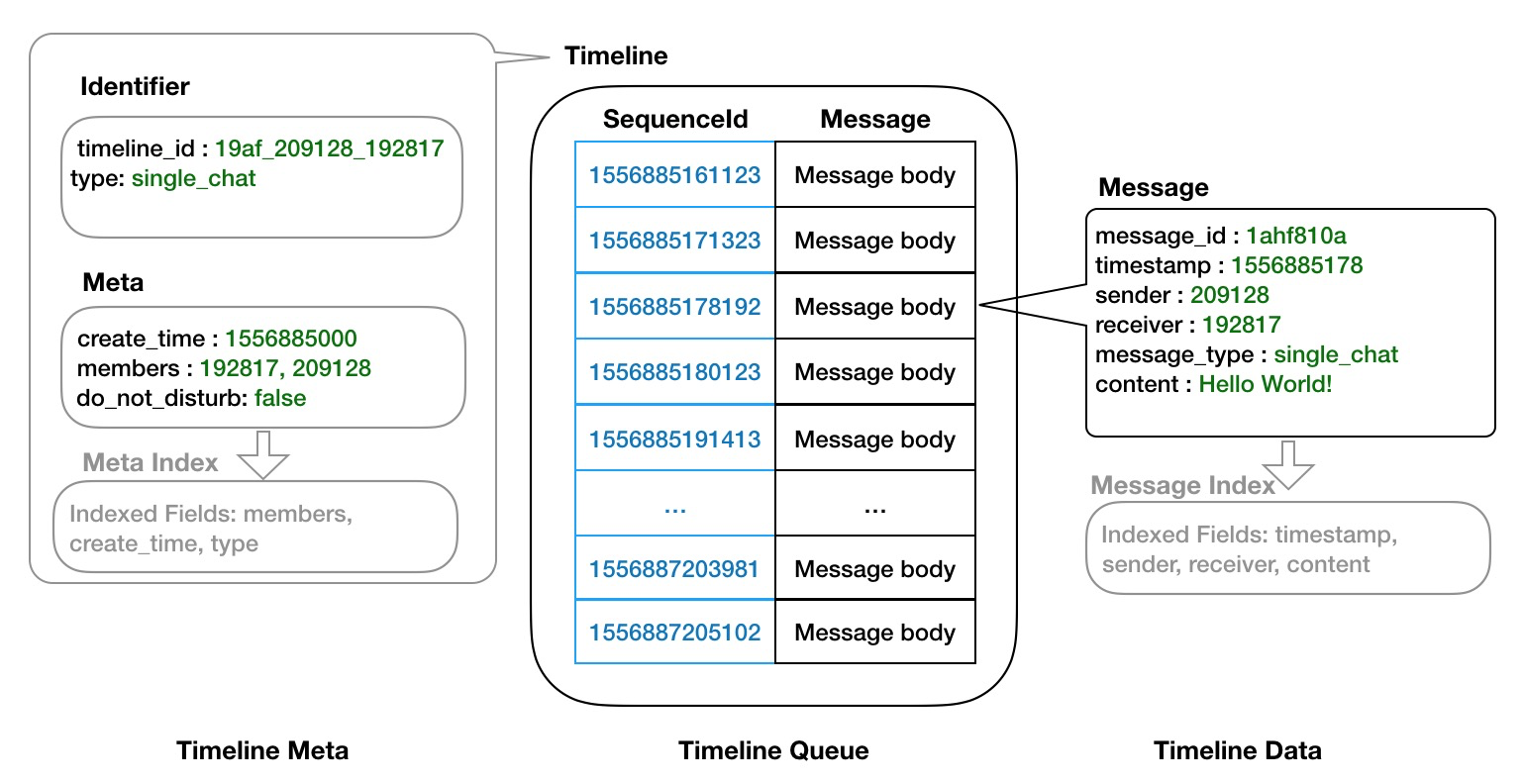
Timeline Store内能存储海量的Timeline,单个Timeline的详细结构图如上,可以看到Timeline主要包含了三大部分:
- Timeline Meta:元数据部分,用于描述Timeline,包括:
-
- Identifier:用于唯一标识Timeline,可包含多个字段。
- Meta:用于描述Timeline的元数据,可包含任意个数任意类型的字段。
- Meta Index:元数据索引,可对元数据内任意属性列建索引,支持多字段条件组合查询和检索。
- Timeline Queue:用于存储和同步消息的队列,队列中元素由两部分组成:
-
- Sequence Id:顺序ID,队列中用于定位Message的位点信息,在队列中顺序ID保持递增。
- Message:队列中承载消息的实体,包含了消息的完整内容。
- Timeline Data:Timeline的数据部分就是Message,Message主要包含:
-
- Message:消息实体,其内部也可以包含任意数量任意类型字段。
- Message Index:消息数据索引,可对消息实体内任意列做索引,支持多字段条件组合查询和检索。
IM消息系统建模
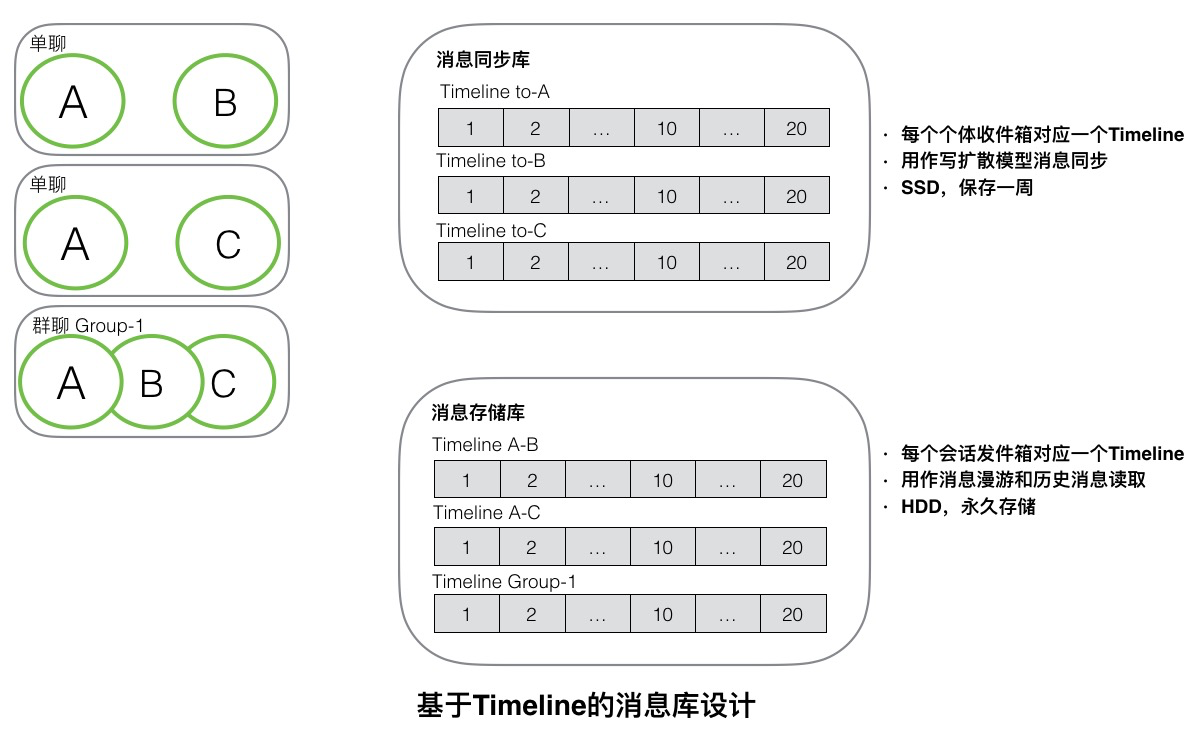
以一个简易版IM系统为例,来看如何基于Tablestore Timeline模型建模。按照上图中的例子,存在A、B、C三个用户,A与B发生单聊,A与C发生单聊,以及A、B、C组成一个群聊,来看下在这个场景下消息同步、存储以及读写流程分别如何基于Tablestore Timeline建模。
消息同步模型
消息同步选择写扩散模型,能完全利用Tablestore Timeline的优势,以及针对IM消息场景读多写少的特性,通过写扩散来平衡读写,均衡整个系统的资源。写扩散模型下,每个接收消息的个体均拥有一个收件箱,所有需要同步至该个体的消息需要投递到其收件箱内。图上例子中,A、B、C三个用户分别拥有收件箱,每个用户不同的设备端,均从同一个收件箱内拉取新消息。
消息同步库
收件箱存储在同步库内,同步库中每个收件箱对应一个Timeline。根据图上的例子,总共存在3个Timeline作为收件箱。每个消息接收端保存有本地最新拉取的消息的SequenceID,每次拉取新消息均是从该SequenceID开始拉取消息。对同步库的查询会比较频繁,通常是对最新消息的查询,所以要求热数据尽量缓存在内存中,能提供高并发低延迟的查询。所以对同步库的配置,一般是需要SSD存储。消息如果已经同步到了所有的终端,则代表收件箱内的该消息已经被消费完毕,理论上可以清理。但设计上来说不做主动清理,而是给数据定义一个较短的生命周期来自动过期,一般定义为一周或者两周。数据过期之后,如果仍要同步拉取新消息,则需要退化到读扩散的模式,从存储库中拉取消息。
消息存储库
消息存储库中保存有每个会话的消息,每个会话的发件箱对应一个Timeline。发件箱内的消息支持按会话维度拉取消息,例如浏览某个会话内的历史消息则通过读取发件箱完成。一般来说,新消息通过在线推送或者查询同步库可投递到各个接收端,所以对存储库的查询会相对来说较少。而存储库用于长期存储消息,例如永久存储,相对同步库来说数据量会较大。所以存储库的选择一般是HDD,数据生命周期根据消息需要保存的时间来定,通常是一个较长的时间。
消息索引库
消息索引库依附于存储库,使用了Timeline的Message Index,可以对存储库内的消息进行索引,例如对文本内容的全文索引、收件人、发件人以及发送时间的索引等,能支持全文检索等高级查询和搜索。
总结
本篇文章主要对Tablestore Timeline模型进行了详解,介绍了Timeline各模块包括Store、Meta、Queue、Data和Index等,最后以一个简单的IM场景举例如何基于Timeline来建模。在下一篇实现篇中,会直接基于Tablestore Timeline来实现一个简易版的支持单聊、群聊、元数据管理以及消息检索的IM系统,敬请期待。欢迎加入我们的技术交流群(钉钉:11789671),来与我们一起探讨。


