由于MaxCompute SQL本身不提供类似数据库的select * from table limit x offset y的分页查询逻辑。但是有很多用户希望在一定场景下能够使用获取类似数据库分页的逻辑,对查询结果进行分页/分批获取结果,本文将介绍几种方法,来实现上述场景。
1. 借助row_number()函数作为递增唯一标识进行过滤查询
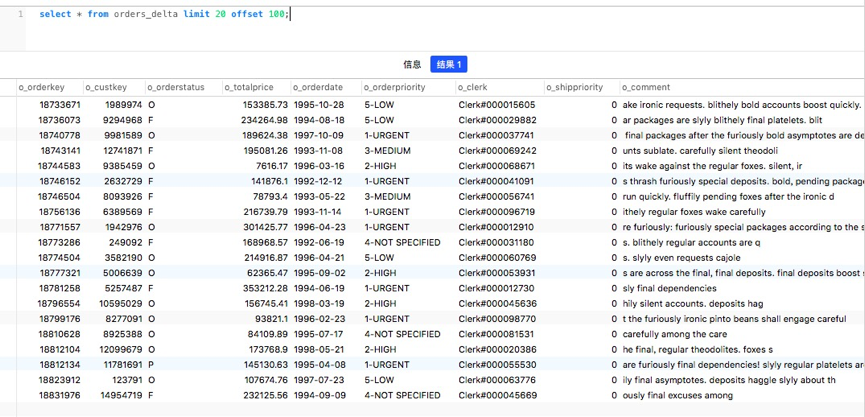
select * from (select row_number() over() as row_id,* from orders_delta)t where row_id between 10 and 20;

通过row_number()对数据进行排序及唯一标识编号,然后根据该标识选取每次查询的分页范围。
2. 利用Java SDK的InstanceTunnel在下载结果时进行分批下载
MaxCompute JavaSDK提供了SQLTask + InstanceTunnel直接导出select的数据集的方法,具体可以参考《使用 Instance Tunnel 获取 Maxcompute Instance 的执行结果》
该案例中,提供了通过InstanceTunnel来下载用户自定义SELECT查询的方法。
Odps odps = OdpsUtils.newDefaultOdps(); // 初始化 Odps 对象
Instance i = SQLTask.run(odps, "select * from wc_in;");
i.waitForSuccess();
// 创建 InstanceTunnel
InstanceTunnel tunnel = new InstanceTunnel(odps);
// 根据 instance id,创建 DownloadSession
InstanceTunnel.DownloadSession session = tunnel.createDownloadSession(odps.getDefaultProject(), i.getId());
long count = session.getRecordCount();
// 输出结果条数
System.out.println(count);
// 获取数据的写法与 TableTunnel 一样
TunnelRecordReader reader = session. openRecordReader (0, count);
Record record;
while ((record = reader.read()) != null) {
for (int col = 0; col < session.getSchema().getColumns().size(); ++col) {
// wc_in 表字段均为 STRING, 这里就直接打印输出
System.out.println(record.get(col));
}
}
reader.close(); 这里通过了SQLTask提交了1条自定义select查询,然后使用InstanceTunnel.DownloadSession直接对该查询结果进行下载。其中,openRecordReader方法支持指定本次读取记录的起始位置和读取数量,通过openRecordReader(start,long)的参数设定,可实现分批下载的逻辑。
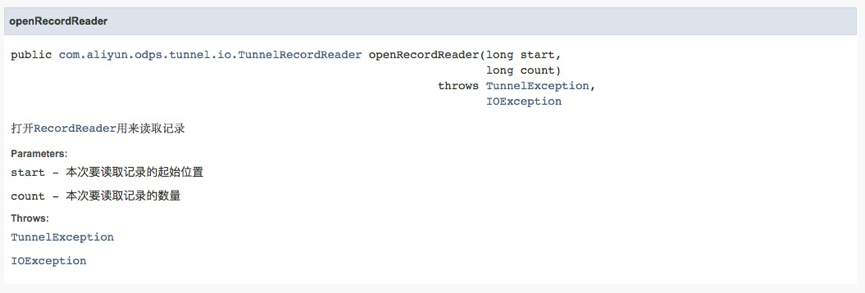
例如,将上面例子中openRecordReader (0, count)修改为用户想获取的起始位置和获取记录数量:
TunnelRecordReader reader = downloadSession.openRecordReader(100, 20);
参考内容:MaxCompute SDK Java Doc的InstanceTunnel.DownloadSession类的openRecordReader方法。
由于MaxCompute所处理表的数据量往往都非常大,以上的方法一般不建议使用在报表的交互分页查询场景上。对于交互时查询有需求的用户,可以考虑通过MaxCompute的交互式分析(Lightning)来查询。
3. 利用MaxCompute交互式分析(Lightning)的limit/offset语法实现分页
MaxComput SQL不支持limit/offset语法,但开发者可以借助MaxCompute交互式分析(Lightning)来使用limit/offset。
MaxCompute交互式分析能够在相同的权限体系下,以PostgreSQL协议和语法快速查询MaxCompute数据。利用PostgreSQL的limit offset语法可以实现与数据库查询相同的分页效果。