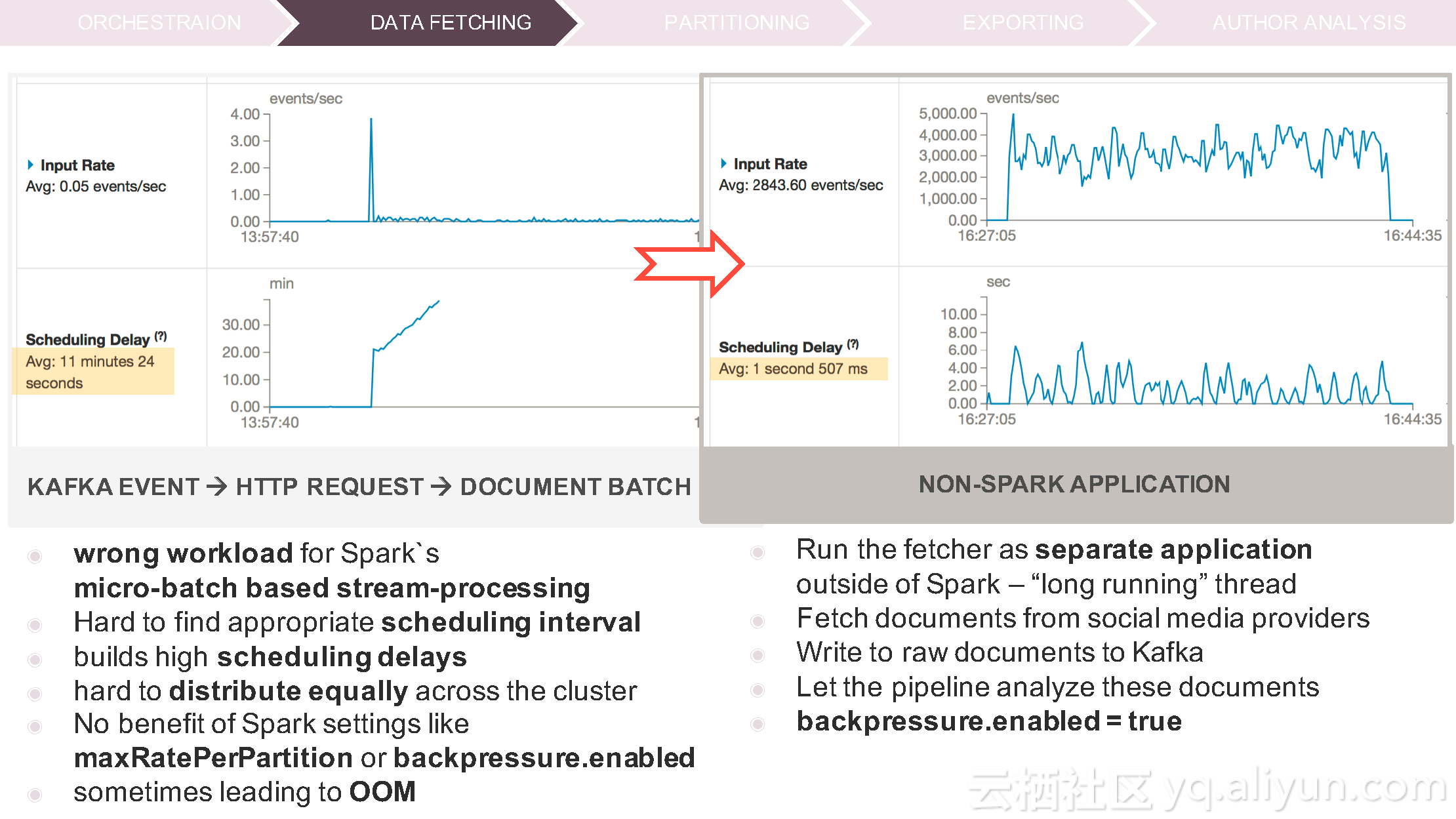
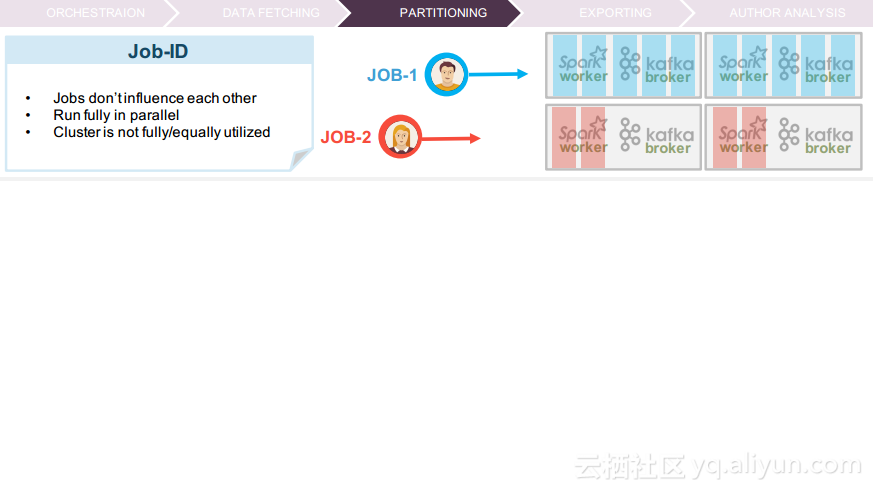
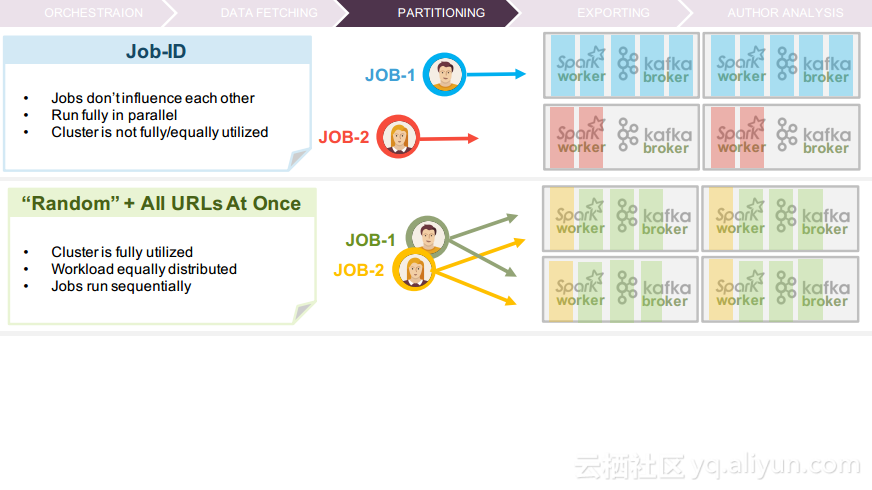
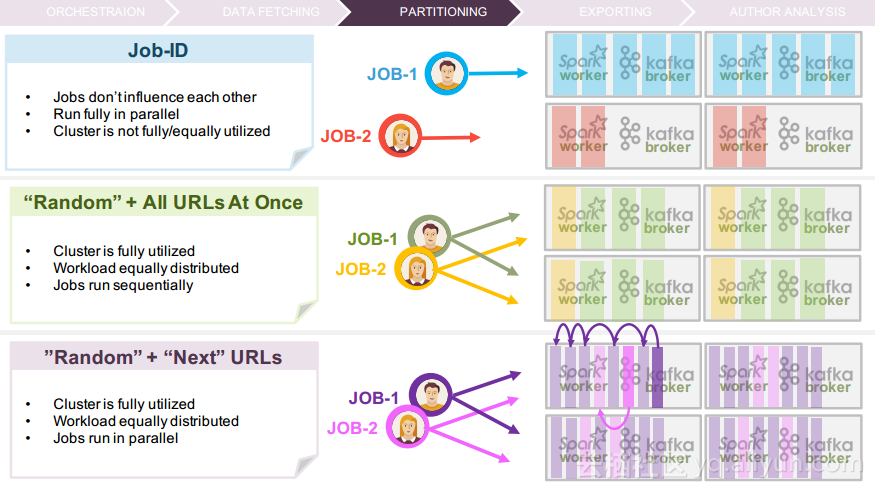
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
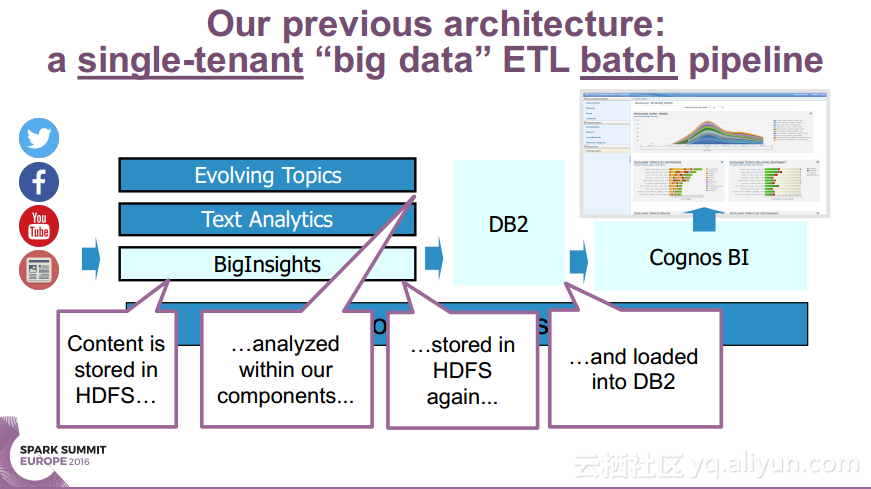
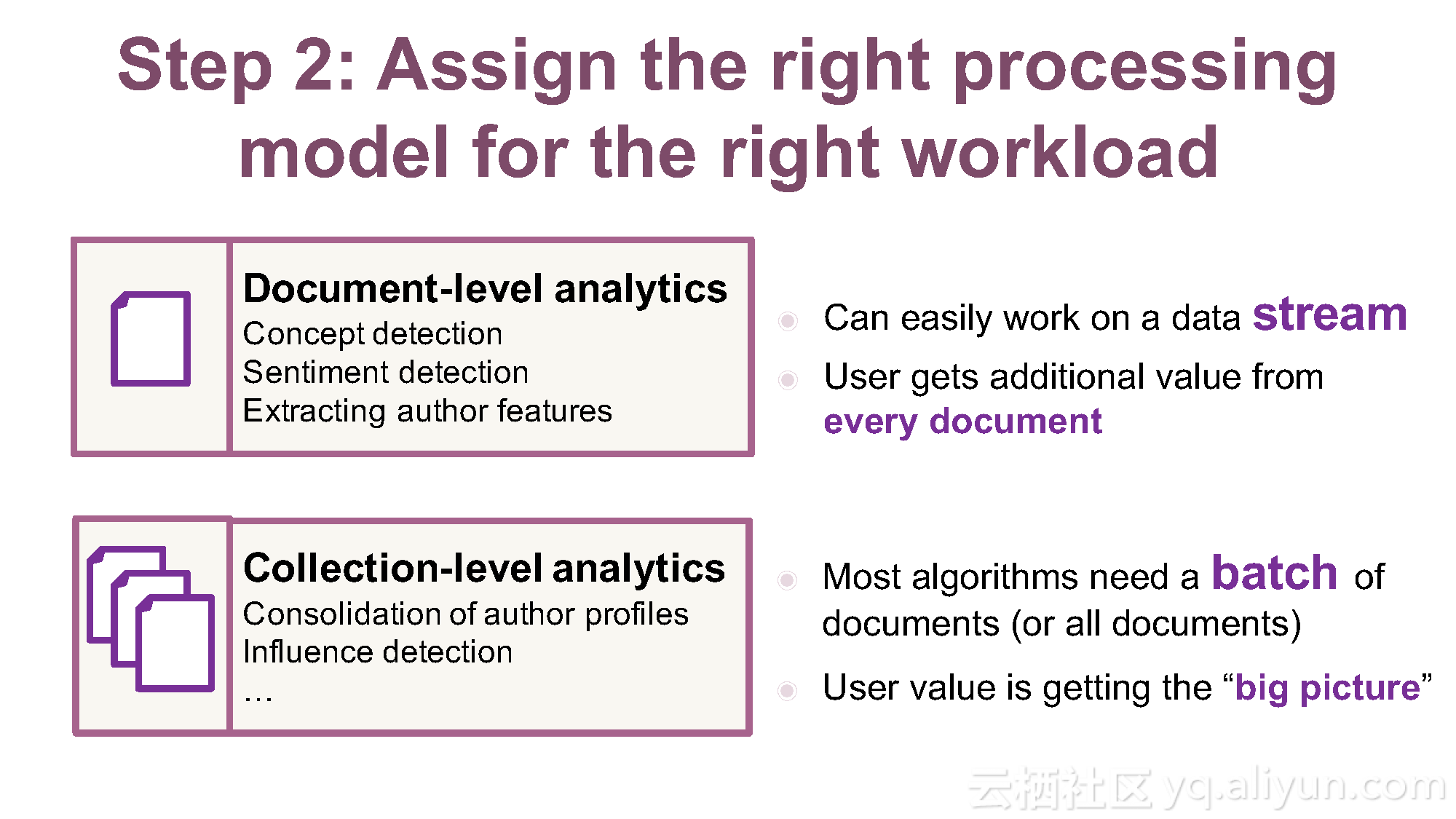
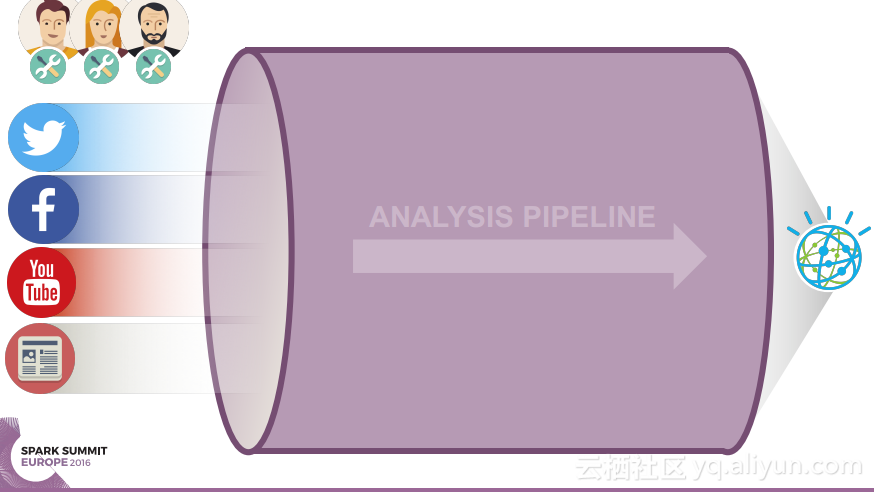
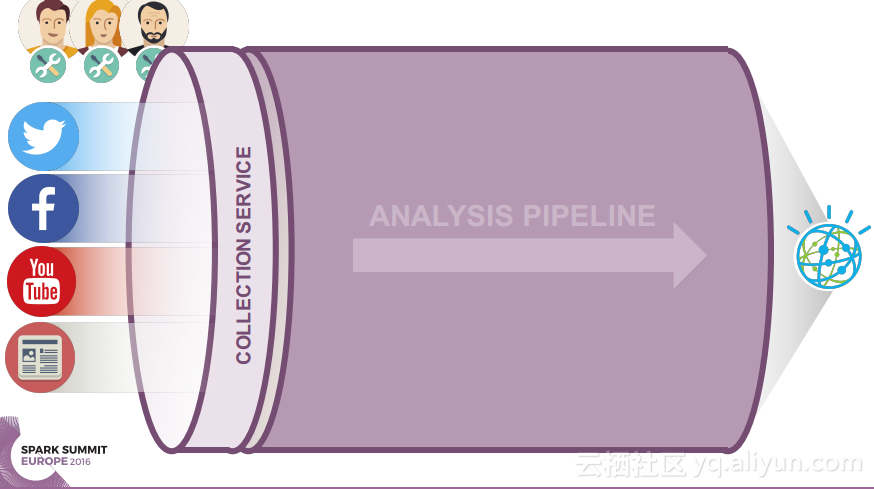
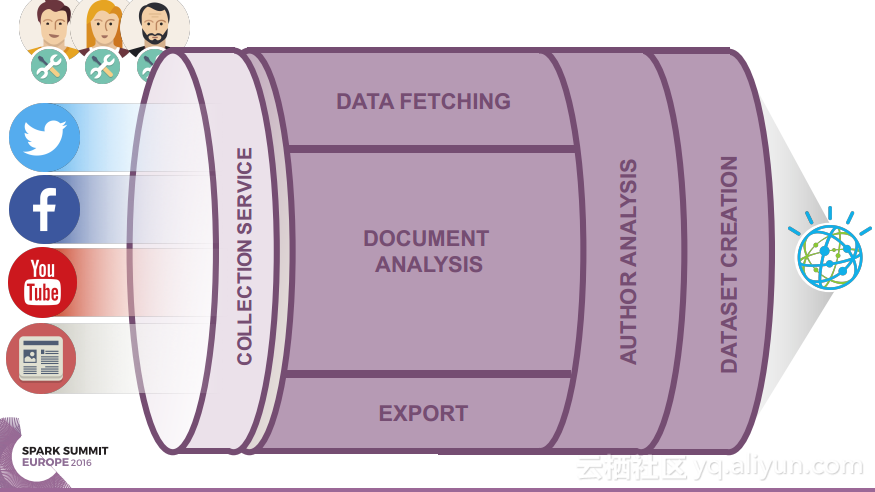
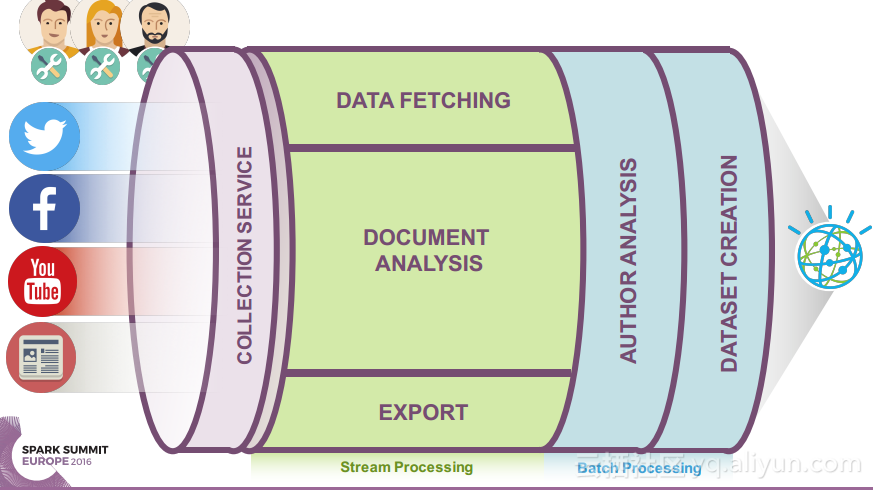
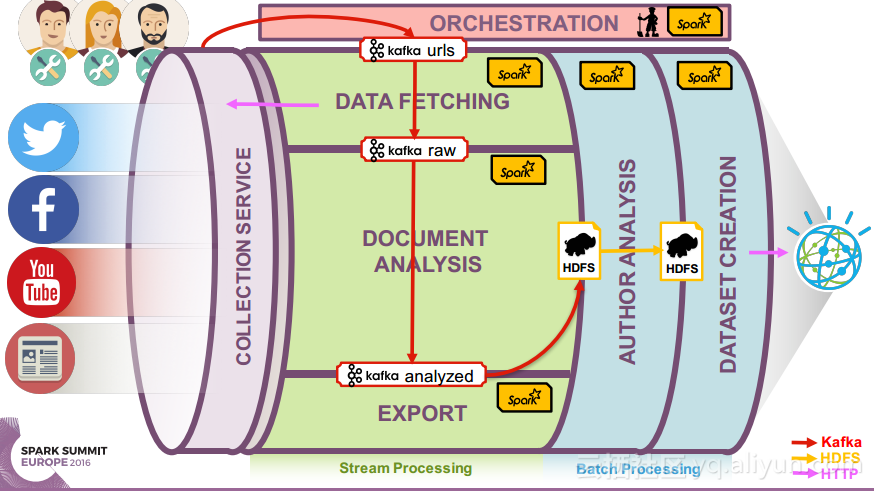
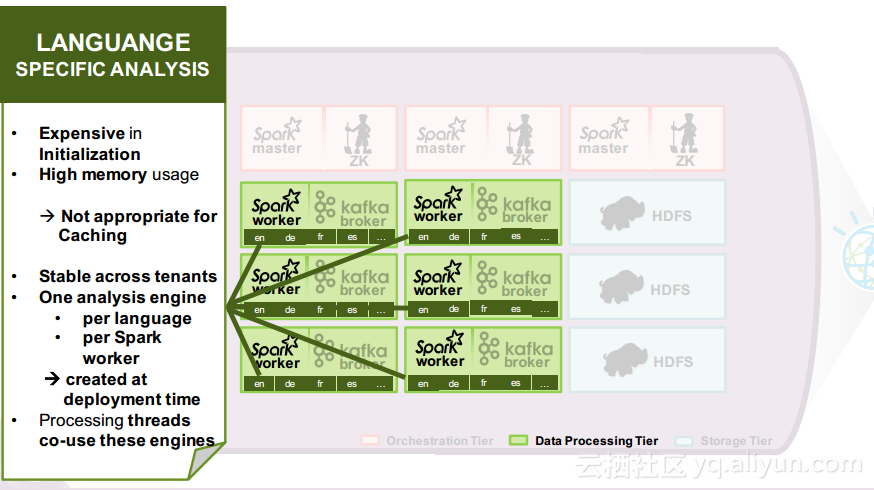
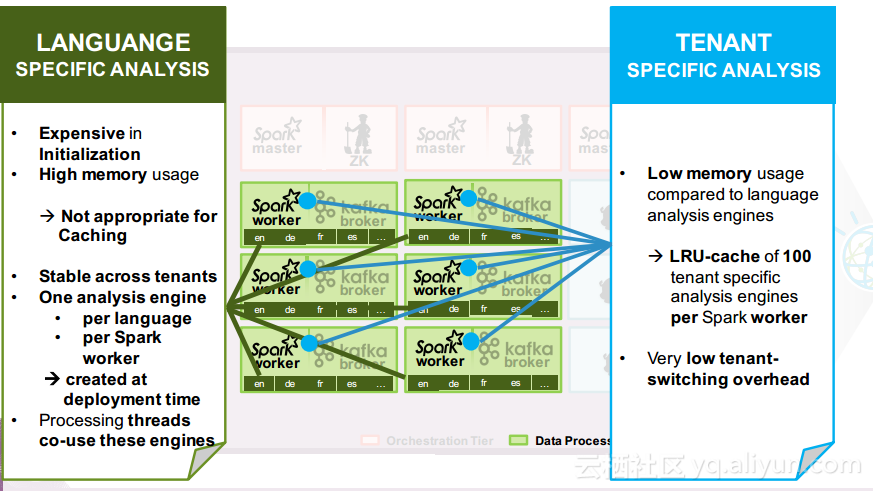
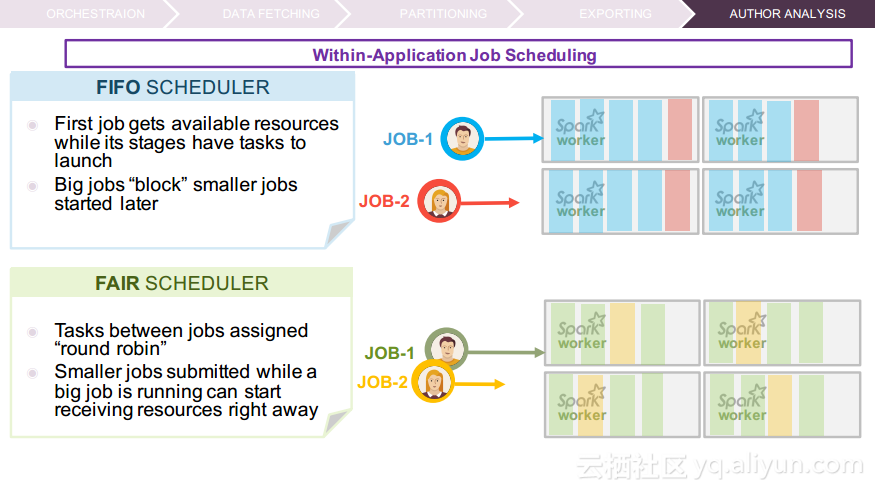
本讲义出自Ruben Pulido和Behar Veliqi在Spark Summit EU 2016上的演讲,主要介绍了IBM公司的沃森媒体分析系统,介绍了该系统之前针对于单租户的架构,所需面对的多租户挑战和面对该挑战产生出的新系统架构。
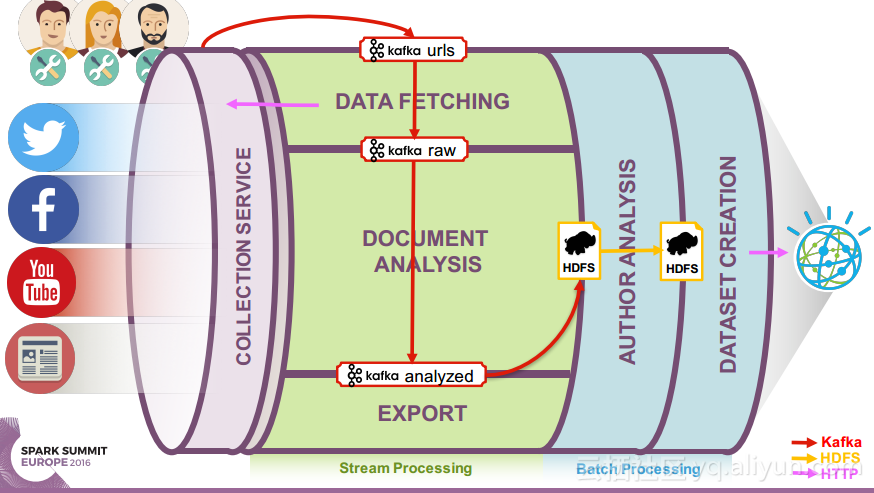
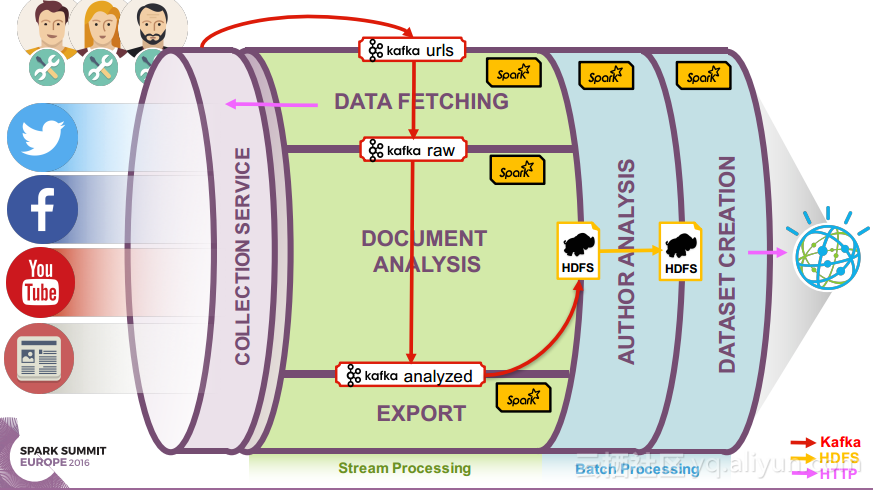
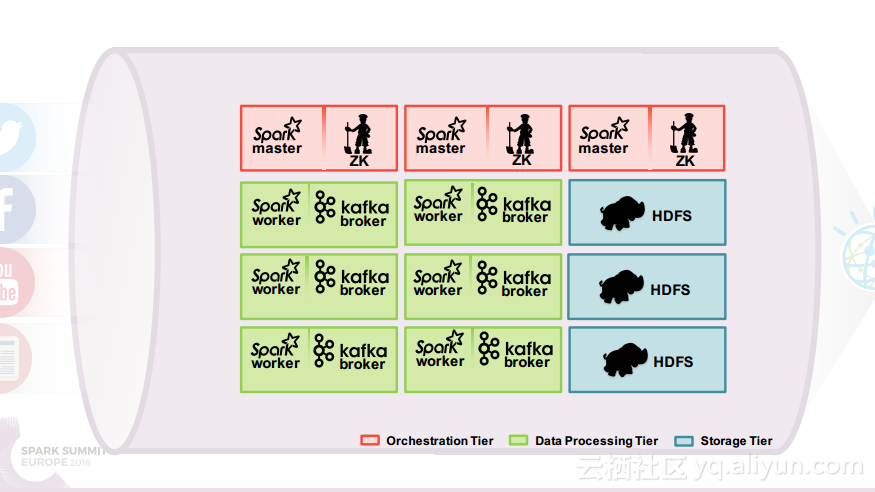
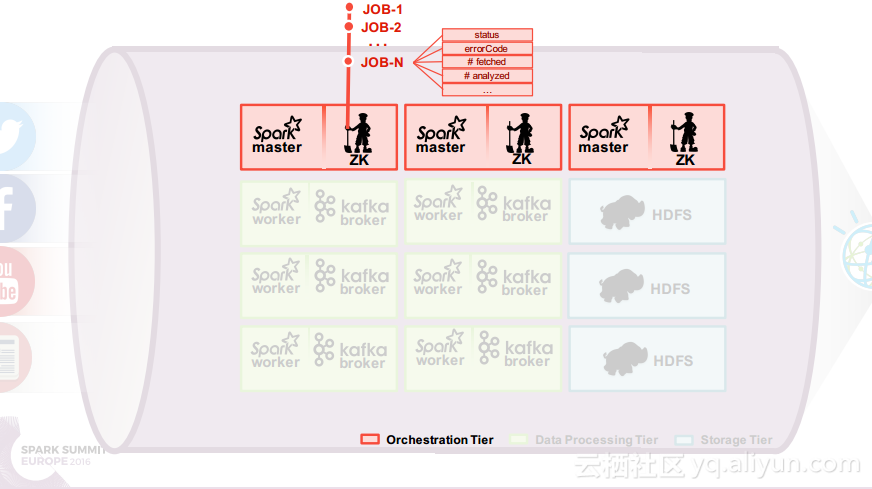
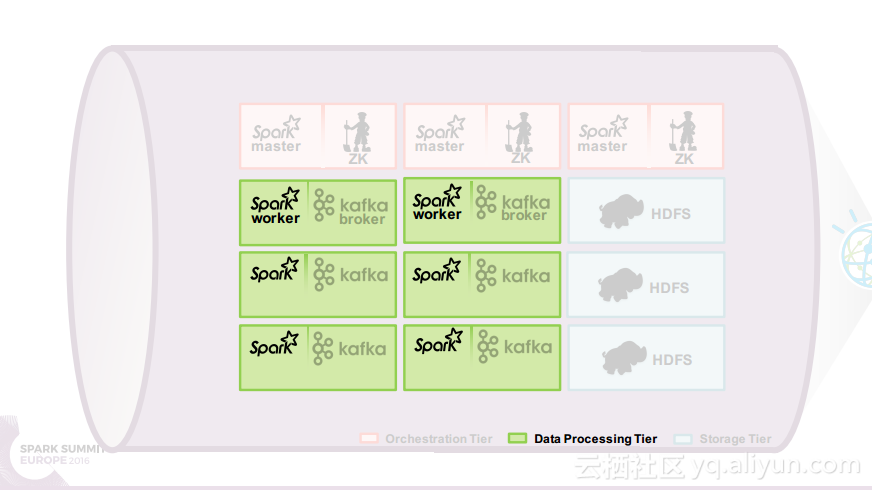
在讲义的最后Ruben Pulido和Behar Veliqi总结了从沃森媒体分析系统架构演变过程中所获取的经验,新的发展途径可能会基于Spark、Kafka和Zookeeper,并将具有健壮性的特点,能够满足延迟和吞吐量的需求,并且能够支持更多的分析。