热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
BGP 技术连载:BGP基本介绍,BGP的特点、运行方式、角色
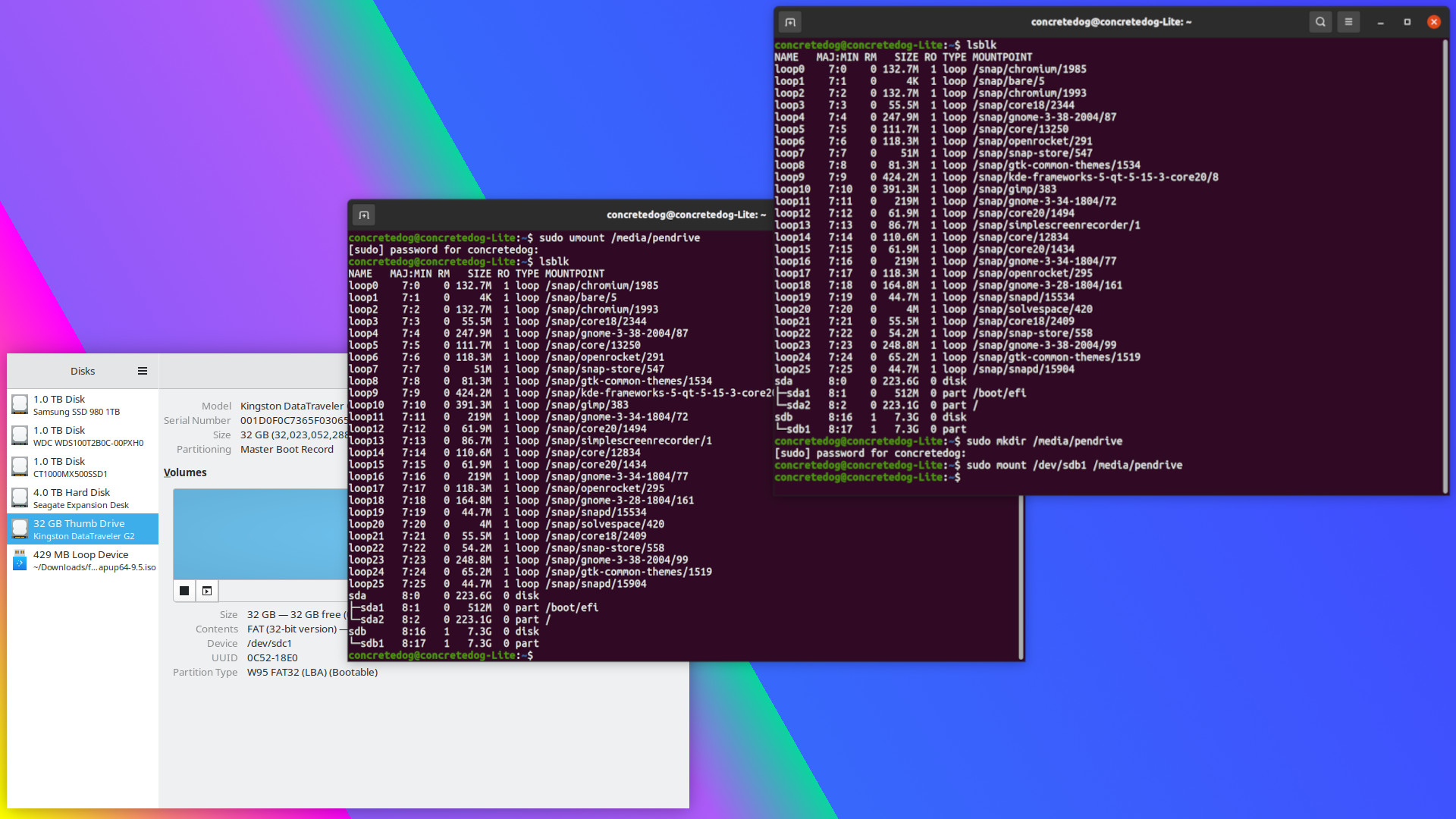
Linux mount命令怎么用?
探索现代Web应用中的性能优化策略
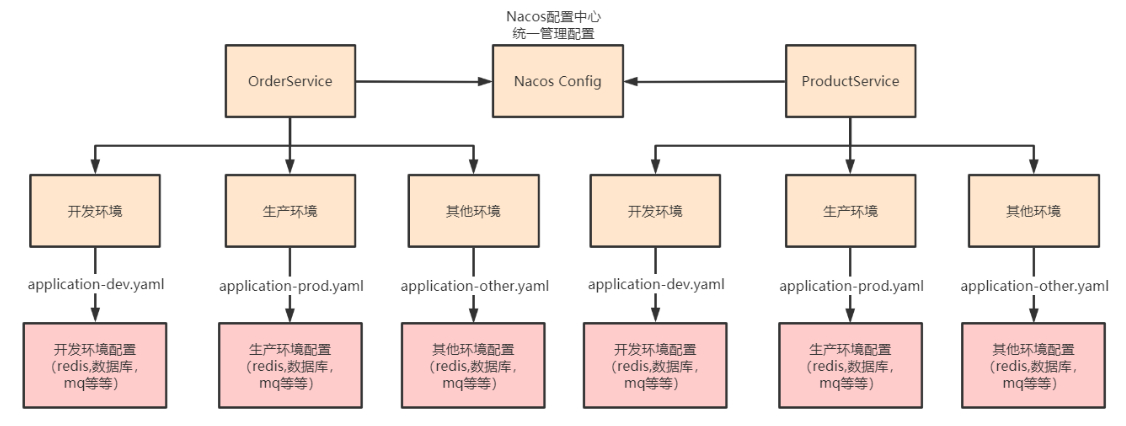
第十一章 Spring Cloud Alibaba nacos配置中心
什么是OSPFv3协议?与OSPFv2有啥区别?
软件体系结构 - 架构风格(2)管道/过滤器架构风格
利用Python进行情感分析:从入门到实践
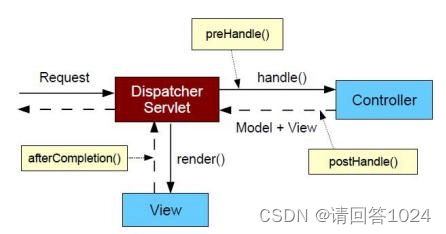
SpringMVC 拦截器
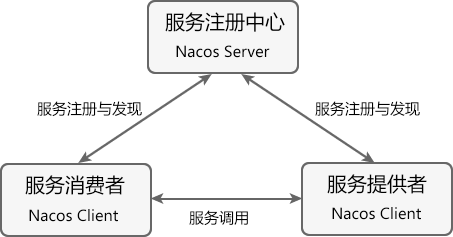
第十章 SpringCloud Alibaba 之 Nacos discovery
小小前端如何在AIGC领域“乘风破浪”
SpringMVC 文件上传和下载
SpringMVC HttpMessageConverter
软件体系结构 - 架构风格(1)批处理架构风格
Java 实现双链表
第九章 Gitlab使用
使用Selenium爬取目标网站被识别的解决之法
SpringMVC RESTful
一文浅谈CodeReview中的一些思考
什么是HTTP代理?HTTP代理的作用?HTTP代理怎么设置?
三种方法实现获取链表中的倒数第n个元素
在使用HTTP代理IP的需要注意什么?
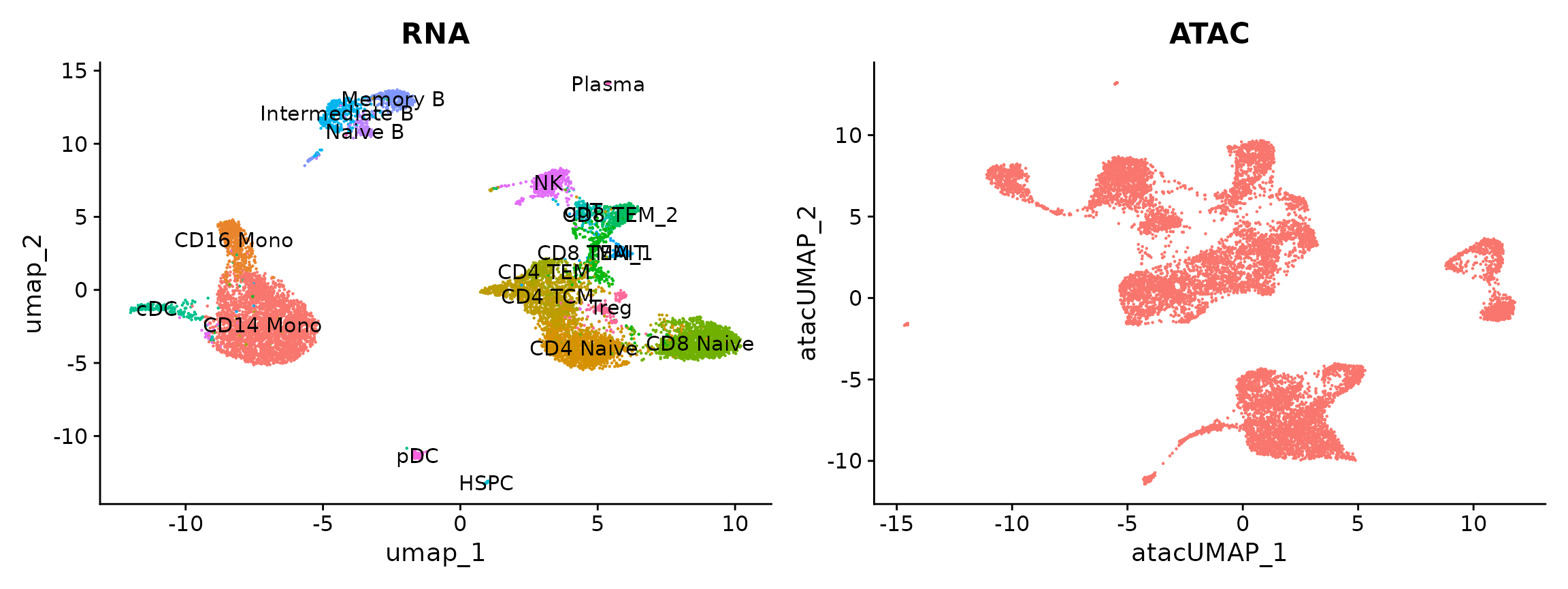
单细胞分析|整合 scRNA-seq 和 scATAC-seq 数据
Java 实现单链表
FOXBORO IDP10 I/A Series® 型电子差压变送器
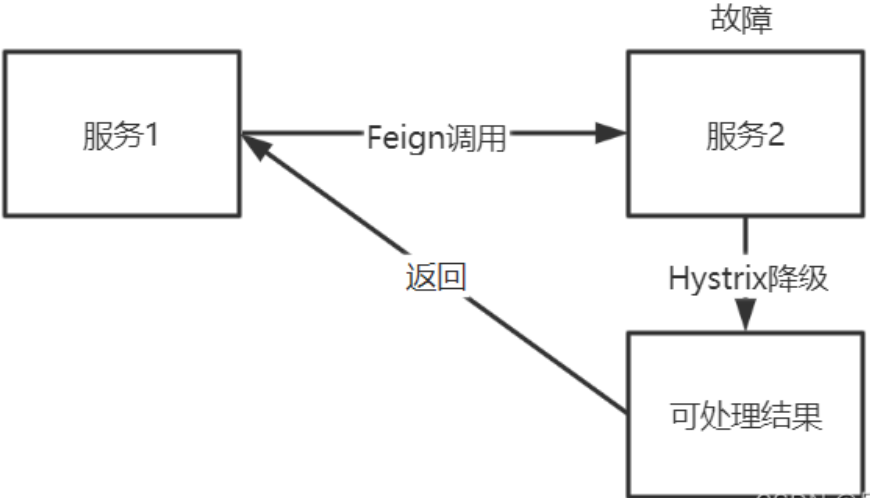
第八章 Spring Cloud 之 Hystrix
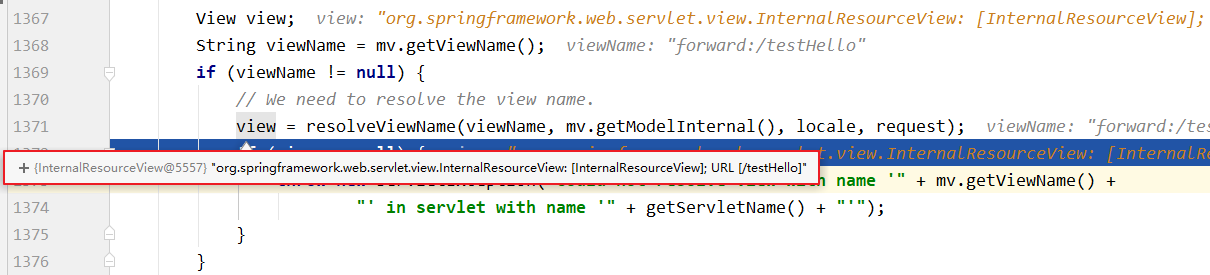
SpringMVC视图
SpringMVC 域对象共享数据
第七章 Spring Cloud 之 GateWay
关于跨域,和跨域问题的完整解决方案
GPU计算资源智能调度:过去、现在和未来
【spring】01 Spring容器研究
开源召集令
SpringMVC 获取参数
卓越体验的秘密武器:评测ToDesk云电脑、青椒云、天翼云的稳定性和流畅度
nginx: [warn] conflicting server name "proxy_set_header" on 0.0.0.0:80, ignored
计算机视觉快速入门:探索图像处理
第六章 Spring Cloud 之 OpenFeign
SpringMVC RequestMapping注解
[emerg] 15060#200: bind() to 0.0.0.0:80 failed (10013: An attempt was made to access a socket ......
第十二章 Shell脚本编写及常见面试题(二)
程序员35岁会失业吗
【SpringCloud】怎么在IDEA中显示RunDashboard
SpringMVC 写个 HelloWorld
【SpringCloud】详解Eureka注册中心
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker 避坑
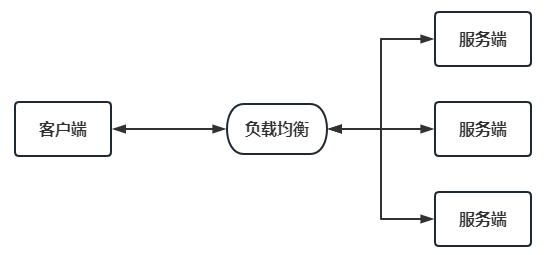
第五章 Spring Cloud Netflix 之 Ribbon