【作者】 驭策(龚志刚) 笋江(林立翔)蜚廉(王志明) 昀龙(游亮)
近些年来,深度学习在图像识别,自然语言处理等领域快速发展。各种网络模型,需要越来越多的计算力来进行训练。以典型的中等规模的图像分类网络Resnet50为例,基准的训练精度为Top-1 76%, Top-5 为 93%,为达到此精度,一般需要将整个Imagenet数据集的128万张图片,训练90次(90 epoch). 这样的计算量,以单张P100的计算力需要6天才能训练完毕,而最近的NLP 领域取得突破的Bert 模型以及GPT-2的预训练,如果在单机上进行则需要数月甚至按年计。因此在实际的生产环境,引入分布式训练,大大降低模型训练所需的时间,提高模型迭代的速度成为紧迫的需求。基于这样的需求,各大深度学习框架,基本都实现了分布式训练的支持。
| 参数服务器(PS) | MPI(NCCL) | |
| Tensorflow | Y | Y (Horovod) |
| MXNet | Y | Y (Horovod) |
| Pytorch | N | Y (Horovod, Gloo) |
| Caffe | N | Y (NVCaffe) |
在实践中,我们发现在云环境中,现有训练框架的分布式有以下问题:
- 不同的框架支持分布式的具体形式均不相同,支持用户从单机到分布式的工作量和框架的种类成正比。
- 所有框架的分布式实现,在测试环境下扩展性均不理想,初步的profiling结果显示,网络带宽并未被有效利用。以Resnet50为例,Tensorflow + Horovod 四机32卡,batch size为128,GPU卡为P100,扩展性仅为86%,低于预期。
- 为了进行扩展性的优化,需要考虑对诸多不同框架的支持,面临巨大的重复性工作且难于维护。
以上3个问题都指向了一个方向,就是统一各框架的分布式通信到一个单一的架构中。我们也注意到开源的Horovod项目,部分解决了以上问题,目前已经支持Tensorflow,Pytorch和Keras,最近也加入了MXNet的支持。Horovod给了我们一个很好的参考,这种大统一的分布式通信框架是可行的,梯度的同步通信是完全可以被抽象为框架无关的架构的。但是Horovod最大的问题是没有解决云上的扩展性问题,我们经过讨论,决定开发一个完全独立的项目Ali-Perseus,在阿里云上打造一个高度优化的统一深度学习分布式通信框架。
通用分布式通信架构设计
基于阿里云的基础设施的特点,我们设计了一个完全自主的通用分布式框架,除了支持Horovod所支持的Tensorflow和Pytorch以外,我们根据阿里云的主要AI用户的需求,还增加了MXNet以及Caffe的支持。系统的架构如下图:
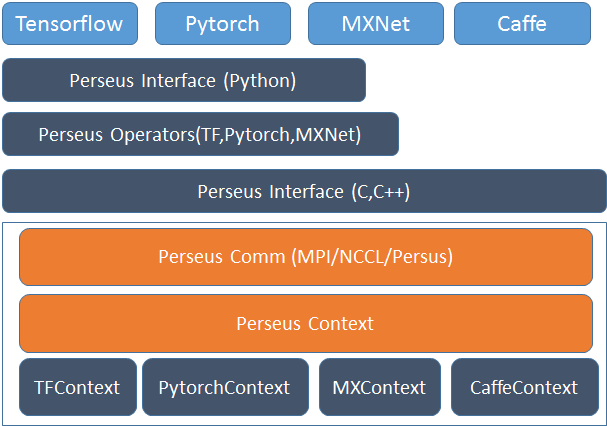
Ali-Perseus 训练通信框架整体模块图
系统设计的宗旨是将所有与实际通信相关的操作全部对上层训练框架保持透明,同时将对不同框架的支持切分为互相独立的模块。基于这样的宗旨,具体模块设计如下:
接口层
通信框架需要提供两类接口,一类为Python 接口,另一类为C接口。接口层的任务是对上层模型训练任务提供以下几个功能:
- 创建通信层以及对应的框架支持
- 获取当前进程的全局任务编号,全局任务规模,节点内任务编号,和节点内任务规模
- 关闭当前通信框架
为MXNet,Pytorch和Tensorflow需要准备对应功能的python接口,为Caffe只需要提供C的接口。各框架的Python接口部分的细节描述,见框架层。
通信层
我们将通信层的接口简化为两类API:
- 注册梯度
- 梯度通信
每个框架在进行梯度归约通信之前,必须先注册梯度,注册过程的参数是梯度的上层训练框架层的唯一标识的名称,内部会分配一个key值来代表改梯度;之后就可以进行梯度通信,接口是将对应的梯度加入到通信队列之中,并标明通信类别为广播或者是Allreduce,同时还需要注册一个回调函数,当分布式通信结束后,会调用回调函数通知上层训练框架梯度通信已经完成,可以进行后续的参数更新操作了。梯度通信的所有细节,都不需要暴露任何接口。
通信层内部模块图如下:
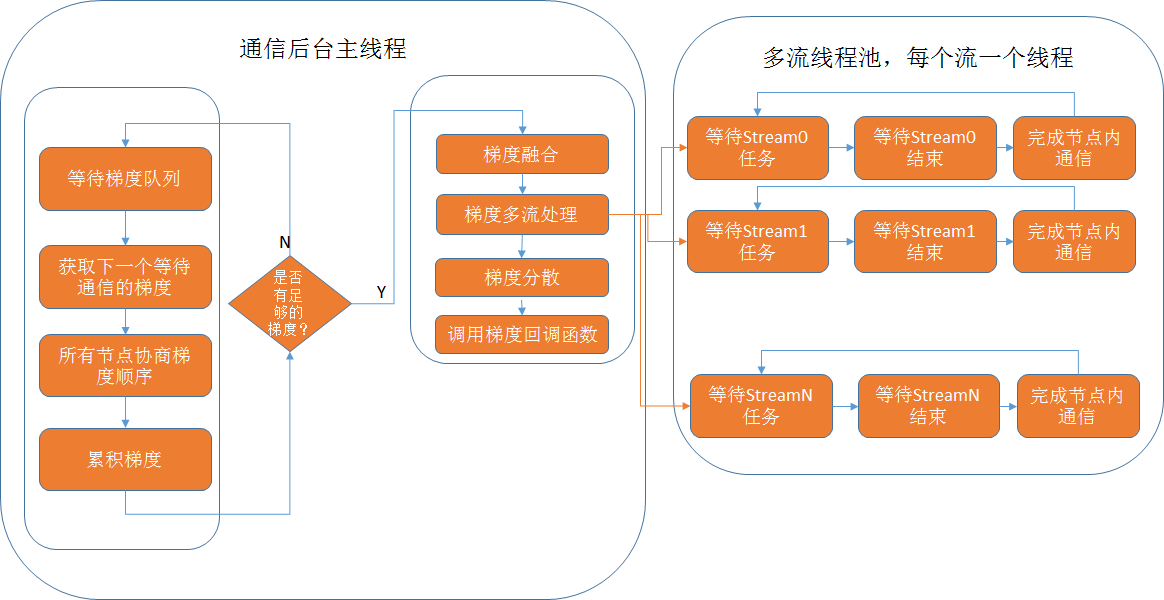
Ali-Perseus 通信模块图
通信的主要工作都是在后台主线程中完成,异步的等待在多流线程池中进行,这样的完全异步多流方式,将可能的单一慢连接对全局的影响降到最低。主要的步骤如下:
- 主线程中处理等待通信的梯度
- 多节点协商各梯度的状态,梯度是否就绪
- 确定各节点产生顺序完全一致的就绪梯度列表
- 各节点统计各自列表是否符合通信粒度需求
- 开始进行融合分片通信,这里需要处理与上层框架的同步关系,确保开始融合通信之前,上层框架已经产生对应的梯度输出。分片的多流资源是同步获取,若无可用流资源,则等待之前的某些流结束。若有流资源,则将该分片数据,使用该流发出,同时通知线程池中对应线程。
- 完成梯度的分散,对应片断的回调函数,在片断回调函数中会检查是否已经完整整个梯度,若是则通知上层训练框架,该梯度已经通信完成。
- 多流线程池
- 每个流有一个专用的线程,会等待主线程的通知。有通知后,等待NCCL 对应的cuda 流结束,确保上半部通信已经完成,生成下半部操作,加入对应队列。
在通信层中,对真正进行通信的更底层的原语进行了封装,目前支持下面两类通信模式:
- MPI带cuda支持
- MPI(非数据通道) + NCCL(数据通道)
框架层
Tensorflow 与Pytorch
对Tensorflow与Pytorch的支持,考虑到Horovod在社区的影响力,为了方便用户已有的模型代码能够无缝的整合到Ali-Perseus 通信库,经过讨论,对这两种框架的框架层支持的python接口部分,选择了与Horovod完全一致的接口,让用户的切换成本接近于零。而与框架层本身衔接的部分,需要定义各自的Tensor以及与Context的虚类的实现即可,均不复杂。
实现完毕之后,对于之前使用Horovod的分布式模型,只需要进行下面的替换即可:
# For tensorflow with horovod
sed -i 's/import horovod.tensorflow as/import perseus.tensorflow.horovod as/g' model.py
# For pytorch with horovod
sed -i 's/import horovod.torch as/import perseus.torch.horovod as/g' model.pyMXNet
MXNet 框架的支持细节可以参考Perseus MXNet这篇ATA文章,这里不再重复描述。
Caffe
由于Caffe本身的分布式支持比较原始,而且没有模块化,因此Caffe的支持是这四类框架相对困难的部分。前面3类框架的支持,除了MXNet需要对MXNet做少量修正外,其余的均不需要改变框架的任何代码,但是对Caffe,我们需要对Caffe的框架做不小的修改,这些修改主要有以下几个方面
- 将单Process 多GPU卡的模式改造为单Process单GPU卡,以MPI的方式来launch 多机多卡的训练
- 将梯度融合部分修改为使用Ali-Perseus的框架API来完成
- 需要构造callback机制,让Ali-Perseus通信框架能够通知Caffe框架整个batch的梯度均已通信完毕。
Ali-Perseus的Caffe框架部分也要增加相应的实现。最后整合才得以实现Caffe的多机多卡。
通信的优化
实现了以上架构后,我们成功的把所有训练框架的分布式通信部分整合到了同一个框架之中。接下来在这套通信框架之下的所有优化工作,都将直接使所有的训两框架受益。我们第一阶段的大部分优化工作都和VPC网络深度相关,这部分的优化总体可以分为两个类别
- 带宽优化
- 我们通过对Horovod的NCCL实现方式进行了Profiling,发现很难达到云上网络带宽的上限,经过分析我们确认,主要的原因是TCP网络,单流通信无法达到上限,使用Iperf也证实了这一点,因此我们决定实现分片多流的策略。在分片多流的过程中,相对单纯的分片方式是针对单次融合的梯度进行分片,然后多流通信。这种方式相对简单,不需要并行的处理不同的融合梯度集合,但是这种方式有一个弊端,就是在进行下一次通信之前,必须等待本次融合切分的所有片断都完成通信。我们进一步发现,多流通信下,每条流的通信速度差异极大,因此最后使得实际速度取决于最慢的一条流,使得加速效果不明显。因此最终采用的是完全的多梯度融合叠加多流的方式,在控制逻辑上会远比之前的逻辑复杂,整个处理过程不得不被切分为上半段和下半段。上半段负责融合以及节点内Reduce再加上节点间通信,下半段会回到节点内Broadcast结果到各节点。期间必须小心处理NCCL的多个流之间的关系,防止发生Hang。
- 延迟优化
- 在深度学习的分布式训练中,一般情况下延迟不是主要问题。但一种情况是例外,就是在大规模的分布式训练下。在进行梯度数据通信之间的梯度协商会创造出一个人为的单点热点,如果按照Horovod中的处理方式,所有的节点均与root节点协商,然后root节点再负责协调所有节点。Root节点的负担会随着节点数增加而大幅增加,我们在一个客户的CTR场景下,320个节点下,协商的overhead导致root节点完全丧失扩展性。通过改造协商的算法,弃用了Horovod中的点对点的中心协商模式,我们将梯度协商的复杂度降低了一至两个数量级。在CTR场景下也重新获得了扩展性。
在以上两大类优化之后,我们发现这里存在一些需要微调的参数,比如融合粒度与分流的粒度,我们最终发现这些参数很难离线的设定好,必须在动态中去寻找最优的配置。这里简要列举一下我们做的主要的通信相关的优化工作:
- 梯度融合的完全多流化,自适应化。多梯度的融合粒度以及融合后分片的粒度,均使用自适应的算法,在训练初期,从设定的一个参数空间中选择当前网络环境下最优的融合粒度以及分片粒度(即流数)
- 梯度压缩。目前仅支持FP16的压缩,可以根据需要,进行scaling,来防止精度损失。后续可以将梯度压缩插件化,允许用户定制各种深度的梯度压缩算法。
- 梯度协商的去中心化。Horovod所采用的点对点的梯度协商机制,在大节点时会遇到较严重的扩展性问题,Ali-Perseus实现的去中心化的梯度协商机制有效的消除了这一问题。
性能对比
在完成了整体架构实现,以及通信性能优化后,我们对比了所有框架下的分布式性能,发现对大部分网络模型,Horovod的性能优于框架本身的性能,而Ali-Perseus相对于Horovod都有一定的提升。总体来说,Ali-Perseus在以下两类状况下,会有非常显著的性能优势:
- 相对较大的网络模型,例如NLP中的Bert,以及人脸识别中的deep insight等;
- 16节点或者更大规模的分布式训练;
下面是我们在客户支持过程中,所做的一些性能测试和对比,部分网络模型配合Ali-Perseus已经运行于客户生产环境。
Tensorflow Bert Base Model
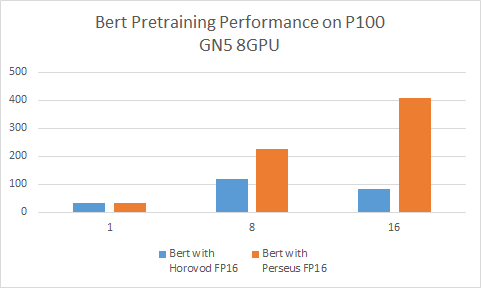
Tensorflow Resnet18
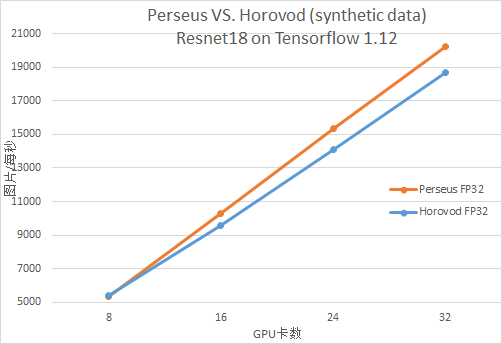
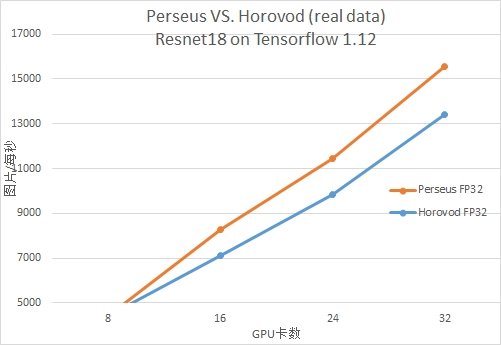
MXNet Resnet50
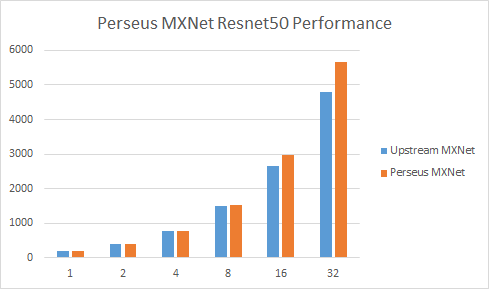
Resnet50 Ali-Perseus 四机32卡扩展性提升至91.9%(MXNet 为79.4%)
MXNet Insightface
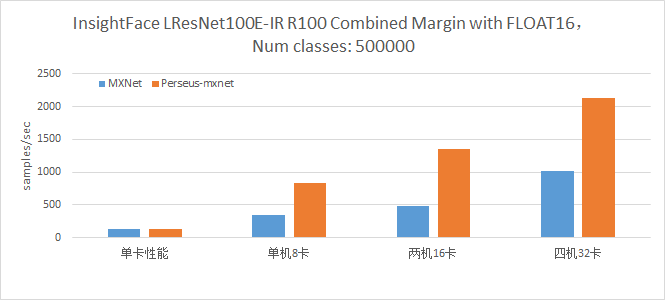
人脸识别模型 Ali-Perseus 性能为MXNet的2至2.5倍
客户案例
通用深度学习分布式通信框架的实现,让我们将各种深度学习框架的分布式优化与框架自身完全解除了耦合,让我们可以在一个统一的框架之下进行阿里云基础设施的深度优化。我们第一阶段在VPC网络上的深度优化,直接让Tensorflow,MXNet,Pytorch和Caffe全面提升了在阿里云上得多机扩展性,大大提升了我们平台优化的效率,也减轻了后期维护的工作量。目前为止,一些客户的状态如下:
- 客户A已经在使用Ali-Perseus+Tensorflow+Bert进行预训练
- 客户B在评测Ali-Perseus+MXNet,目前反馈,与客户的自有MXNet框架整合顺利,检测模型的4机32卡性能提升10%,性能上限接近线形,客户仍在进一步测试。
可以看到客户可以完全保留之前的开源训练框架不变的同时,享受到Ali-Perseus 通信框架的性能优势,对大部分客户来说,是比较容易接受的一种方案。对于客户购买的IaaS资源来说,会直接增加这些资源的性能,提升阿里云异构计算产品的性价比。
总结
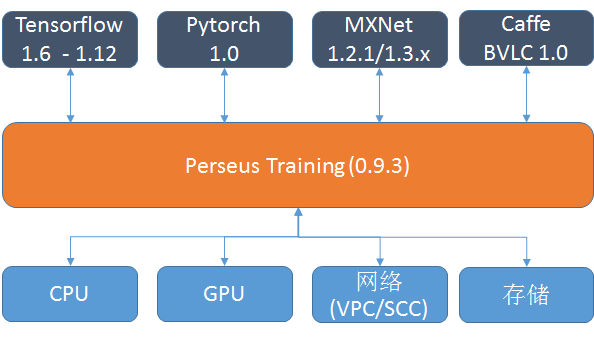
Ali-Perseus的最新Release版本为0.9.4,对框架支持的情况见下图,支持Python2.7以及3.6,支持Centos 7 以及Ubuntu 16.04。这里总结一下Ali-Perseus 通信框架几个主要特点:
- 多训练框架支持(Tensorflow,Pytorch,MXNet,Caffe)
- 与训练框架轻耦合,支持客户的私有训练框架
- 自适应网络优化,支持多流
- 梯度压缩(支持float16)
- 去中心化梯度协商
- NaN 检查功能