
1. 前言
从EMR-3.18.1版本开始,EMR将提供Spark Streaming SQL预览版功能。本次作为新特性的一部分,EMR将扩展现有Spark WebUI,支持Structured Streaming Query的统计信息查看。
2. 功能介绍
2.1 Query列表
我们在现有Spark WebUI上新增了streamingsql Tab,用于展示当前作业中进行中以及完成的Streaming Query。
URL地址:http://${baseUrl}/streamingsql
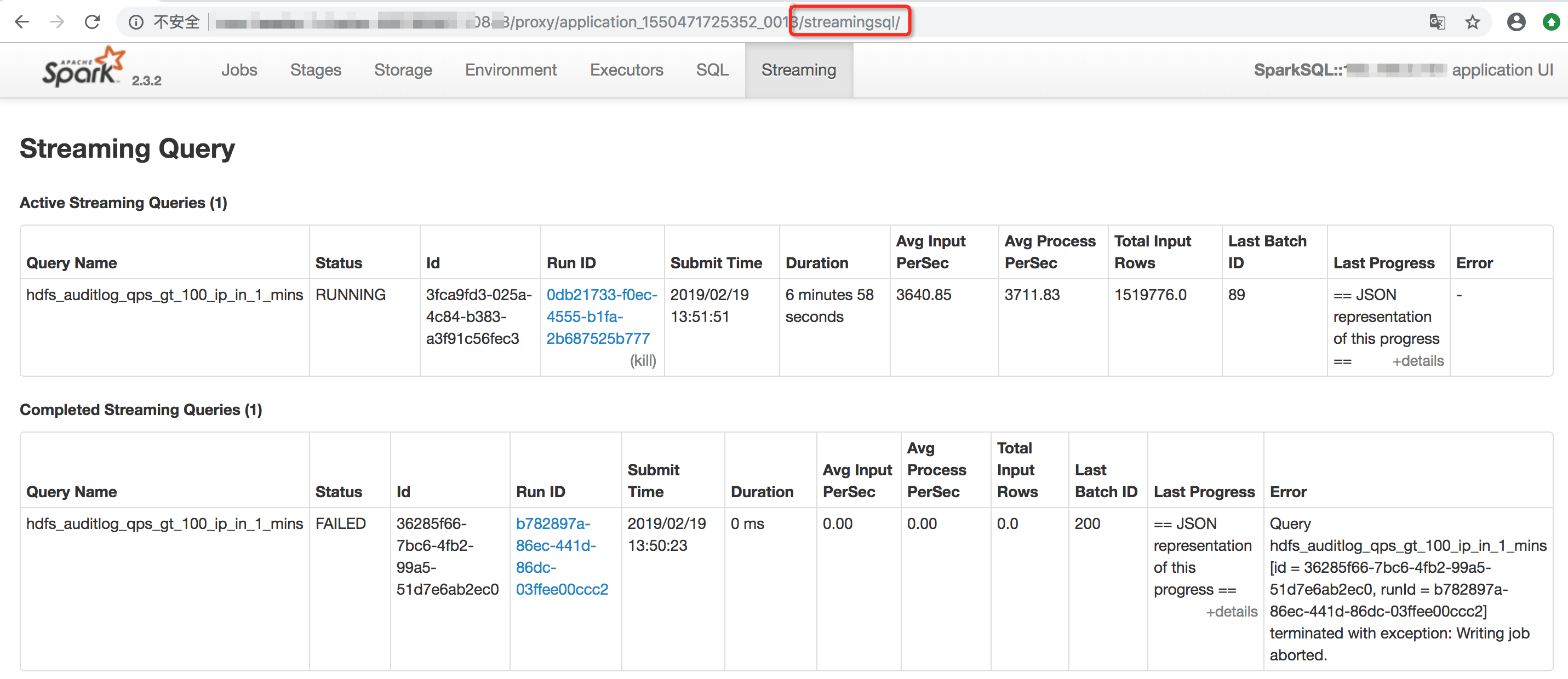
- Active Streaming Queries:当前正在运行的query
- Completed Streaming Queries:已完成的query,包括结束的和失败的query
支持在界面上kill某个query。

kill之后状态变为“FINISHED”:
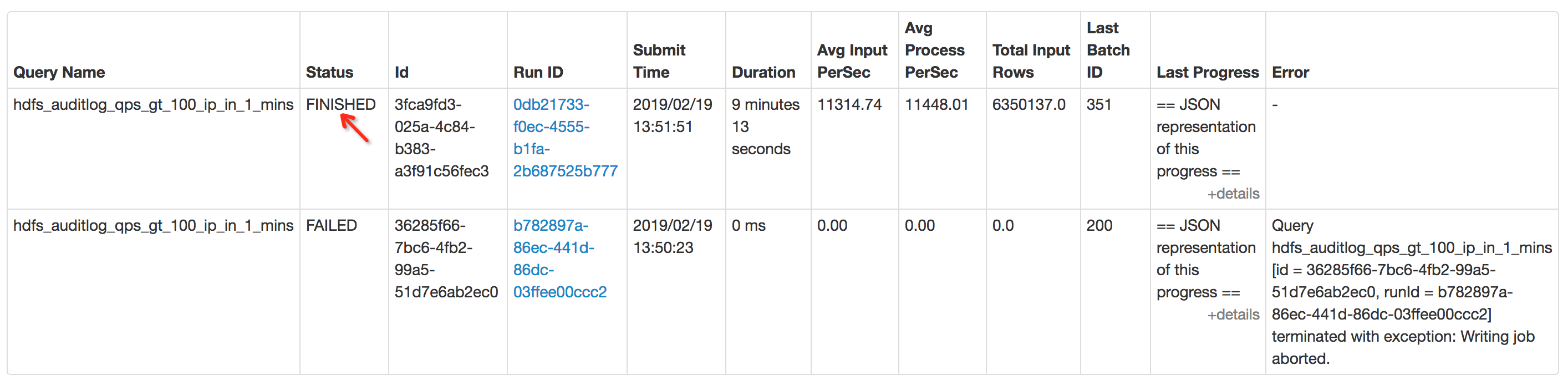
2.2 Query统计详情
通过点击Query的RunID,可以查看当前Query的运行统计信息,包括:Input Rate,Process Rate,Input Rows的时序变化,以及每个批次的Duration堆栈图,包括WalCommit,QueryPlanning,GetOffset,GetBatch以及AddBatch。
URL地址:http://${baseUrl}/streamingsql/statistics?id=9d7e9076-f96a-4d19-9f82-460b5af57daa
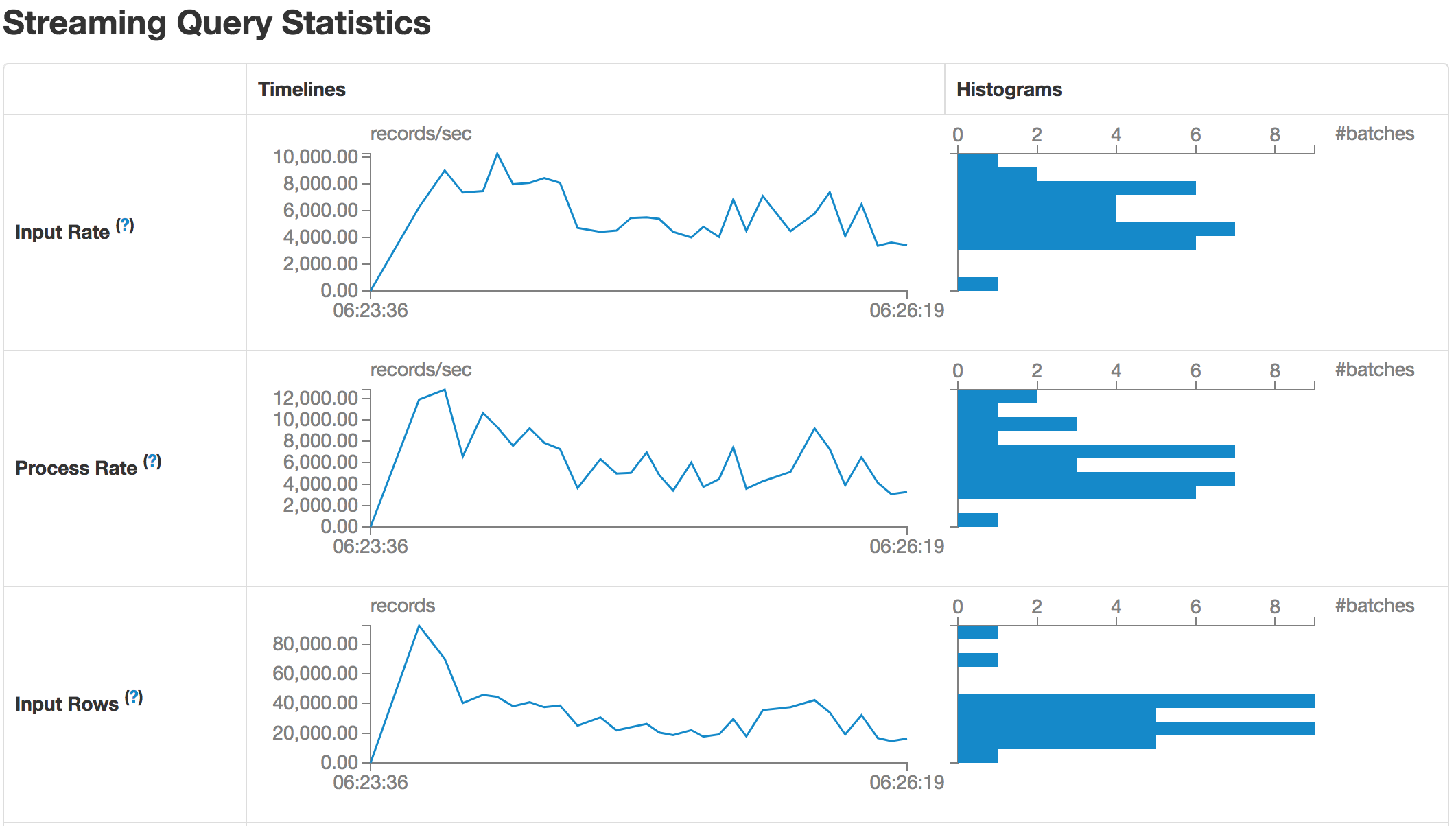
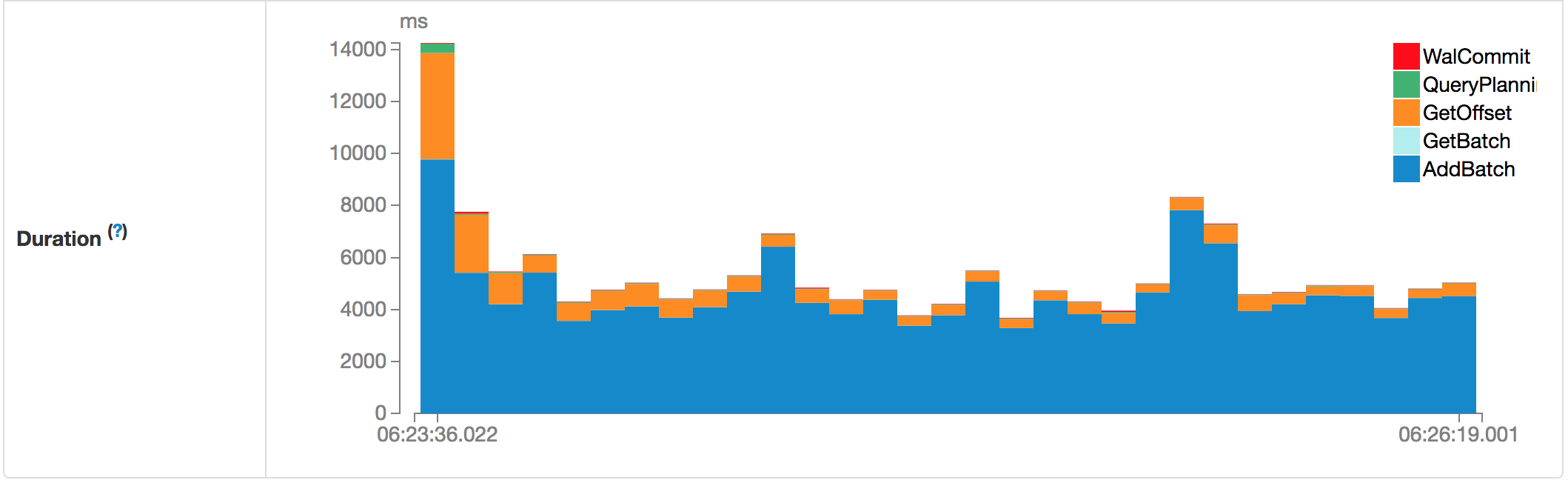
我们可以查看任意时间的Batch的各个执行阶段的时间消耗。
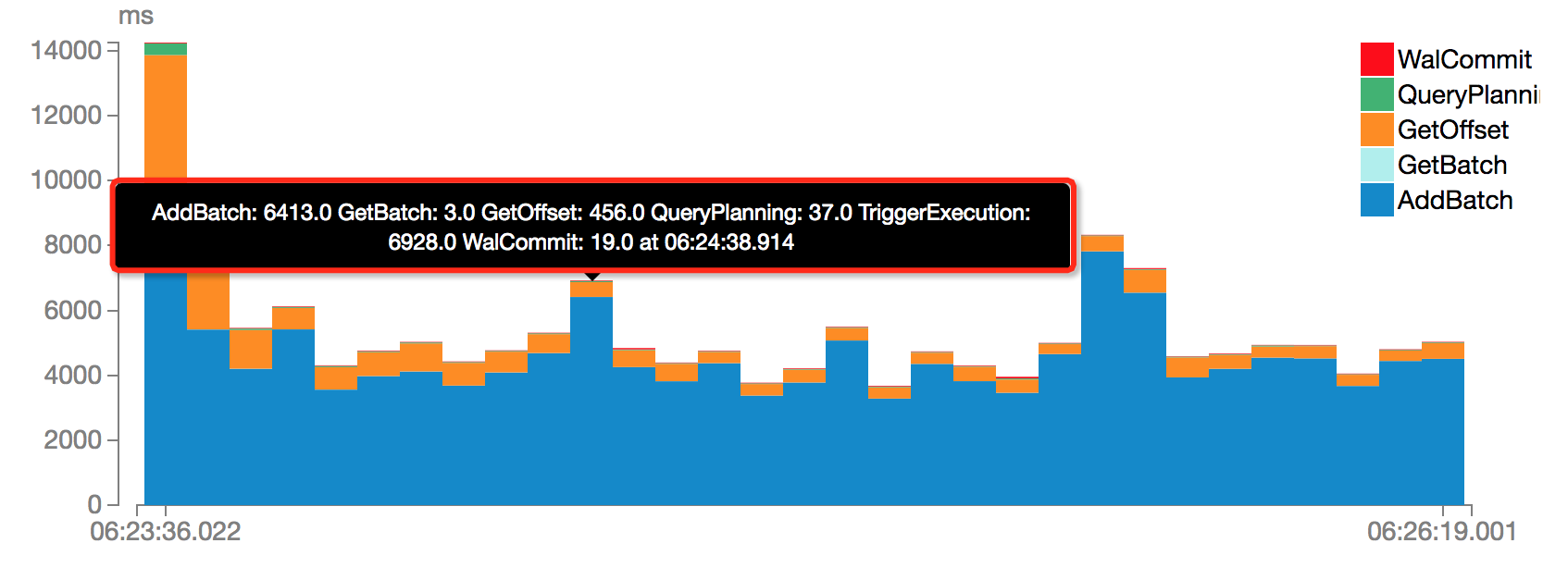
同样的,这里将只会展示“spark.sql.streaming.numRecentProgressUpdates”个Batch的统计信息。如果需要查看更长周期内的统计信息,可以设置“spark.sql.streaming.numRecentProgressUpdates”为更大值。需要注意的是,这会带来一定的内存开销。
3. 小结
以上简单演示了Structured Streaming Query的管理和统计信息查看功能。当前Spark Streaming SQL处于预览阶段,我们将在UI上集成更多有用的信息,方便大家查看和监控作业的运行状态。

