作为日志服务的采集 agent,Logtail 目前已运行于上百万的机器,为万级别的应用提供服务,每天采集的数据已达到 PB 级别,这些实战的打磨使得 Logtail 在稳定性和性能上都已非常出色,在机器、网络等环境不变的情况下,配置完成后基本不再需要进行任何运维。但对于一些业务,仍旧存在着对 Logtail 进行状态监控的需求,以应对随着时间变化所带来的不确定因素。
本文将从多个层次对 Logtail 的状态进行分析,罗列各个层次所需要的一些常用监控场景,同时,我们将介绍如何通过服务日志、查询分析、告警、API 等日志服务的功能,来实现对这些场景的监控和告警。
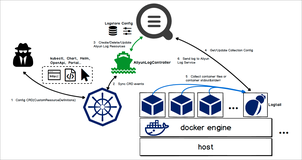
Logtail 状态层次
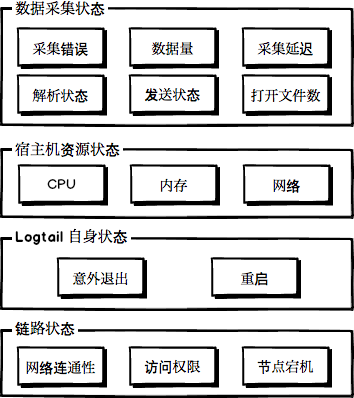
如上图所示,Logtail 状态在大体上可分为四个层次,一般来说,只有在下层状态正常时,对上层状态的监控才会更有意义。这四个层次自底向上分别为:
- 【建议】链路状态:此处具体是指 Logtail 和日志服务之间的链路状态,包括 Logtail 访问日志服务所使用的网络是否正常、Logtail 是否具有足够的访问权限乃至 Logtail 所在节点是否已宕机等。
- 【建议】Logtail 自身状态:Logtail 自身的运行状态,包括是否发生了异常退出、是否发生了重启等。
- 【可选】宿主机资源状态:Logtail 运行所占用的宿主机资源,包括 CPU、内存、网络等。
- 【可选】数据采集状态:数据采集过程中产生的一系列状态,包括发生的采集错误、采集的数据量、数据采集的延时等。
以下我们将分别介绍如何对各个层次的相关状态进行监控以及告警。
日志服务功能简述
Logtail 的状态监控会使用到日志服务的一系列功能,包括服务日志、查询分析、告警、API 等,所以在开始前,我们先简单地概述一下这些功能的作用。
服务日志
前文在介绍 Logtail 状态层次时所提及的大部分状态由 Logtail 主动收集并上报(不包含用户数据),对于一些量比较大的状态,它会在发送前进行聚合。为了能够获取并操作这些日志,我们首先需要开通服务日志功能,具体的开通步骤可以参考此文档。 在开通时,只要不勾选操作日志,则此功能完全免费。
开通时请注意所选择的存储位置(project),日志服务会将 Logtail 相关的状态信息分发到名为 internal-diagnostic\_log 的 logstore(开通时自动创建),其中包含了多种类型的日志。为了避免混淆,不同类型的日志具有不同的主题(\_\_topic\_\_ 字段)。在本文中,我们仅关注其中的三种数据,它们的主题分别是 logtail\_status、logtail\_profile 以及 logtail\_alarm。
通过上述的介绍可以发现,通过此功能获取的日志在本质上和用户日志没有区别,因此,我们可以利用日志服务的查询分析功能从中挖掘我们所需要的信息。
查询分析
日志服务提供大规模日志实时查询与分析能力(LogSearch/Analytics,简称查询分析),该功能提供了简单的查询语法并复合上了符合 SQL92 标准的分析语法,因此,我们可以像操作关系数据库那样通过 SQL 来对数据进行查询分析。
告警
在通过查询分析功能提取到所需要的数据后,我们可以对它们进行持续性地监控,当发现满足某些条件(比如超过或低于期望阈值、变化幅度过大等)时,通过短信、邮件、钉钉等渠道进行通知。
日志服务的告警功能即可满足此需求。基于查询分析语句的结果,设置所需的告警表达式和触发间隔等参数后,即可实现对数据的持续监控,日志服务将在结果满足所设置的表达式时进行告警通知,支持短信、邮件、钉钉、WebHook 等通知方式。
API
当控制台提供的功能无法满足需求时,我们还可以尝试通过自行调用 API 来实现。事实上,日志服务控制台的大部分功能也基于同一套 API 实现。
常用状态监控
在本章中,我们将分别介绍四个层次中的一些常用状态监控,并提供为它们配置监控和告警所需要的代码、查询语句、操作步骤等,你可以直接根据本章的内容来进行实际的操作。
链路状态
链路状态是保障 Logtail 正常工作的基础,一般我们会假设在首次配置成功后就不会出现问题。但事实上,虽然概率较低,但依旧有多种原因可能导致链路出现问题,比如:
- 节点宕机:这个不必多说。
- 网络:除了网络链路物理上失效的情况以外,对于存在防火墙的网络拓扑,如果防火墙策略发生不当变更,同样可能导致这一条件被破坏。
- 鉴权:一般会在自动化运维时遇到此问题,简单举个例子:自动化运维配置了通过 API 新建 ECS 并安装 Logtail,且在之后会将新增节点添加至日志服务 project 的机器组以获取配置采集数据。对于非本人 ECS,日志服务要求在节点上配置目标 project 拥有者的主账号 Aliuid 来进行鉴权,此时,如果新增的机器非本人 ECS 而又运维规则中未按照要求进行设置,则新增的机器将鉴权失败。
- 运维:不当的运维操作停止了 Logtail 或者误杀 Logtail 进程(包括 daemon 进程)。
通过上述的一些场景可以发现,链路状态出现问题的概率很低,但是一旦出现问题,将导致 Logtail 无法采集任何数据。因此,如果有条件的话,我们建议大家均对此状态进行监控。
使用机器组 API 监控链路状态
显然,此状态异常的情况下,Logtail 无法正常工作甚至无法访问日志服务,因此,通过服务日志不能实现对此状态的监控。对此,目前比较好的方式是基于 Logtail 心跳实现,当心跳正常时,则链路状态一定正常。
实现上可以借助机器组相关 API,基本思路如下:
- 通过 GetMachineGroup 获取机器组配置信息,从而获取机器组所包含的机器列表。
- 调用 ListMachines 获取机器组当前状态,该 API 会返回机器组内所有机器的最近心跳时间,配合上合理的阈值,即可断定指定机器的心跳是否正常。
- 周期性地调用 1、2 两步进行检查。
以下是基于 CLI 的 Python 实现。
# -*- coding:utf-8 -*-
import commands
import time
import json
class MachineGroupValidator:
def __init__(self, projectName, machineGroupName, threshold):
self.__projectName = projectName
self.__machineGroupName = machineGroupName
self.__threshold = threshold
def Check(self):
configMachineIPs, ret = self._GetMachineGroup()
if not ret: return []
machineStatusList, ret = self._ListMachines()
if not ret: return []
if len(machineStatusList) != len(configMachineIPs):
print '[Error] Must be equal.'
return []
currentTimestamp = int(time.time())
print 'Current timestamp', currentTimestamp
failedMachines = []
for machine in machineStatusList:
if currentTimestamp - machine['lastHeartbeatTime'] > self.__threshold:
failedMachines.append(machine)
return failedMachines
def _GetMachineGroup(self):
cliCmd = 'aliyunlog log get_machine_group --project_name={} --group_name={}'.format(
self.__projectName, self.__machineGroupName)
status, result = commands.getstatusoutput(cliCmd)
if status != 0:
print 'GetMachineGroup failed, command: {}, result: {}'.format(
cliCmd, result)
return [], False
config = json.loads(result)
if config["machineIdentifyType"] != "ip":
print 'Only IP based machine group can get IP list.'
return [], False
return config["machineList"], True
def _ListMachines(self):
cliCmd = 'aliyunlog log list_machines --project_name={} --group_name={}'.format(
self.__projectName, self.__machineGroupName)
status, result = commands.getstatusoutput(cliCmd)
if status != 0:
print 'ListMachines failed, command: {}, result: {}'.format(
cliCmd, result)
return [], False
return json.loads(result).get('machines', []), True
if __name__ == '__main__':
"""
Usage: python monitor.py <project_name> <machine_group_name> <threshold_in_seconds>
"""
import sys
validator = MachineGroupValidator(sys.argv[1], sys.argv[2], int(sys.argv[3]))
failedMachines = validator.Check()
print 'Failed machines count: {}'.format(len(failedMachines))
for m in failedMachines:
print 'IP: {}, last heartbeat time: {}'.format(m['ip'], m['lastHeartbeatTime'])参考以上代码,根据需要配置合理的阈值(公有云上 Logtail 默认心跳周期为 30s 左右,可适当增大阈值至 1-3 分钟),然后定期执行即可实现对机器组状态的监控。对于定期执行的环境,可以使用函数计算的定时触发进行构建。
注意: 上述代码的前提是监控的目标为 IP 类型的机器组,对于自定义标识类型的机器组,GetMachineGroup 无法获取到 IP 列表,从而无法判断 ListMachines 返回的 IP 列表是否完整。不过如果机器的 IP 不会发生变化的话,可以直接基于 ListMachines 返回的结果进行判断(即忽略代码中的 len(machineStatusList) != len(configMachineIPs))。
除了检查以外,我们还需要在发现失败机器时进行通知告警。对于这个需求,我们无需自行构建一套告警系统和通知渠道,可直接通过以下步骤复用日志服务的告警功能:
- 创建一个专门用于告警的 logstore。
- 当检查发现失败机器时,利用 CLI/SDK/API 向该 logstore 中写入一条日志(CLI 可以参考 put_logs 命令)。
- 为该 logstore 配置告警,当发现日志时(查询语句
* | select count(*) as c,告警表达式c > 0),进行告警。
至此,我们完成了一个通过 CLI 访问日志服务 API 来实现对链路状态监控的示例,通过简单地修改,即可实现监控特定机器以及多个机器组等需求。
链路状态异常排查
对于链路状态异常的排查,在一定程度等价于 Logtail 心跳异常的排查,可以参考此文档进行排查。
Logtail 自身状态
除链路状态以外,Logtail 自身状态的正常也是保证数据采集正确的必要条件。此处的自身状态正常是指 Logtail 持续运行,未发生任何的意外退出以及重启等情况,这些情况主要由以下几种场景引起(本节不讨论 Logtail 完全退出的情况,它属于链路状态的范畴):
- 【极少】所使用的 Logtail 版本存在缺陷,触发了未发现的 bug 引起 worker 进程退出。
- 【较少】错误的运维操作导致误杀了 Logtail 的 worker 进程(比如说发现其占用了资源或文件句柄)。
- 【常见】 资源超限导致 Logtail 主动退出后重启。
Logtail 进程的意外崩溃重启有可能会引起数据丢失、数据重复(checkpoint)等问题,因此我们也建议有条件就对此进行监控。
在默认情况下,Logtail 采用的是 daemon/worker 的双进程模式,daemon 进程逻辑简单,一般不会出现错误,所以在 worker 进程挂掉之后,它能够重新拉起新的 worker 进程。因此,对 Logtail 自身状态的监控也就转化为对重启状态的监控,随后再根据额外的信息来分析重启原因。
以下将介绍如何使用服务日志中的两类主题日志进行重启状态的监控。
使用 logtail_status 监控重启
logtail\_status 是服务日志的一部分,它记录了 Logtail 的基本状态,每分钟会记录并上报一次。
为了监控重启,我们需要使用该日志提供的以下字段进行分析:
- hostname:Logtail 所在节点的主机名。
- ip:Logtail 所在节点的 IP。
- instance_id:Logtail 在启动时生成的随机实例 ID,包含随机 UUID、IP、时间戳等部分,基本上不会冲突。
在 Logtail 正常运行期间,它的 instance\_id 将保持不变,因此,所有来自同一个节点的日志应该具有相同的实例 ID,但如果发生了重启的话,一段时间内就会出现两个以上的实例 ID。基于此思路,我们可以使用 hostname+ip 来标识机器(group by),然后统计机器在一段时间内不同的实例 ID 数量。详细地操作步骤如下:
- 进入 logstore internal-diagnostic\_log 的查询控制台。首先找到先前开通服务日志时指定的 project,进入该 project 后找到此 logstore,点击查询进入控制台。
- 在控制台中输入查询语句(
__topic__: logtail_status | select hostname, ip, count(DISTINCT instance_id) - 1 as "重启次数" from log group by hostname, ip HAVING "重启次数" > 0 ORDER by "重启次数" desc),如果所选时间范围内有重启节点,执行效果如下。结果中的每一行都对应一个时间范围内发生重启的节点,包括其主机名、IP、重启次数。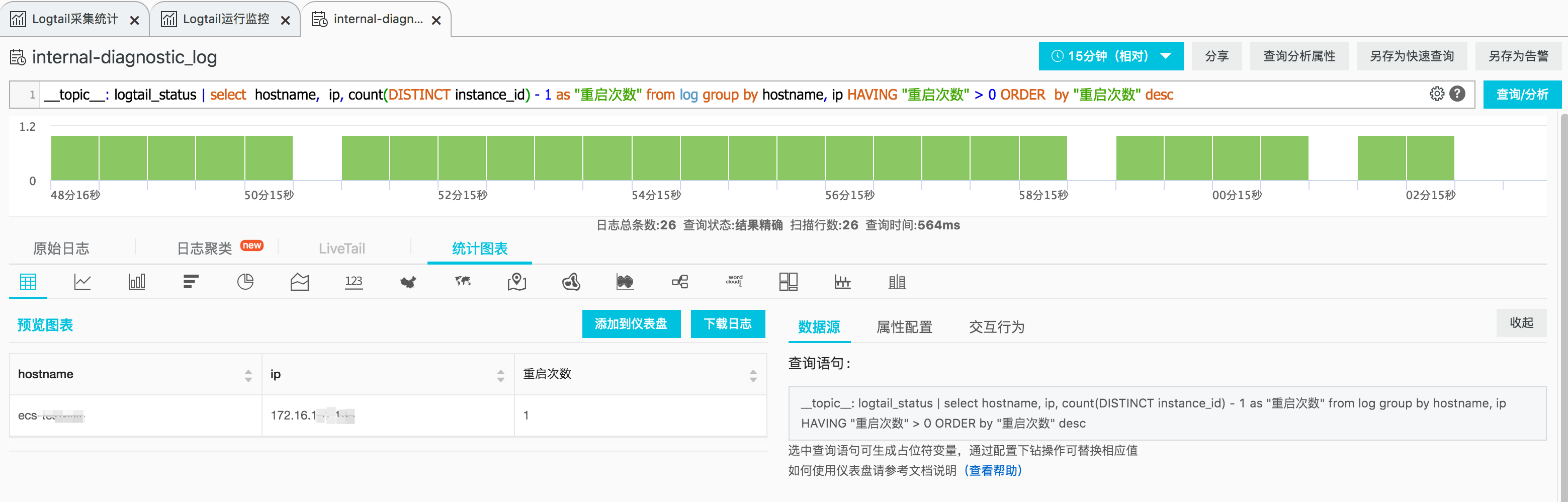
- 为了进行告警配置,我们需要调整一下查询语句,对上一个查询语句的结果进行聚合,得到一个总的数量(
__topic__: logtail_status | select count(1) as c from (select hostname, ip, count(DISTINCT instance_id) - 1 as "重启次数" from log group by hostname, ip HAVING "重启次数" > 0 ORDER by "重启次数" desc))。效果如下。可以看到,结果被聚合成了一个数值字段(c),当该值大于 0,则说明存在发生了重启的节点,需要告警。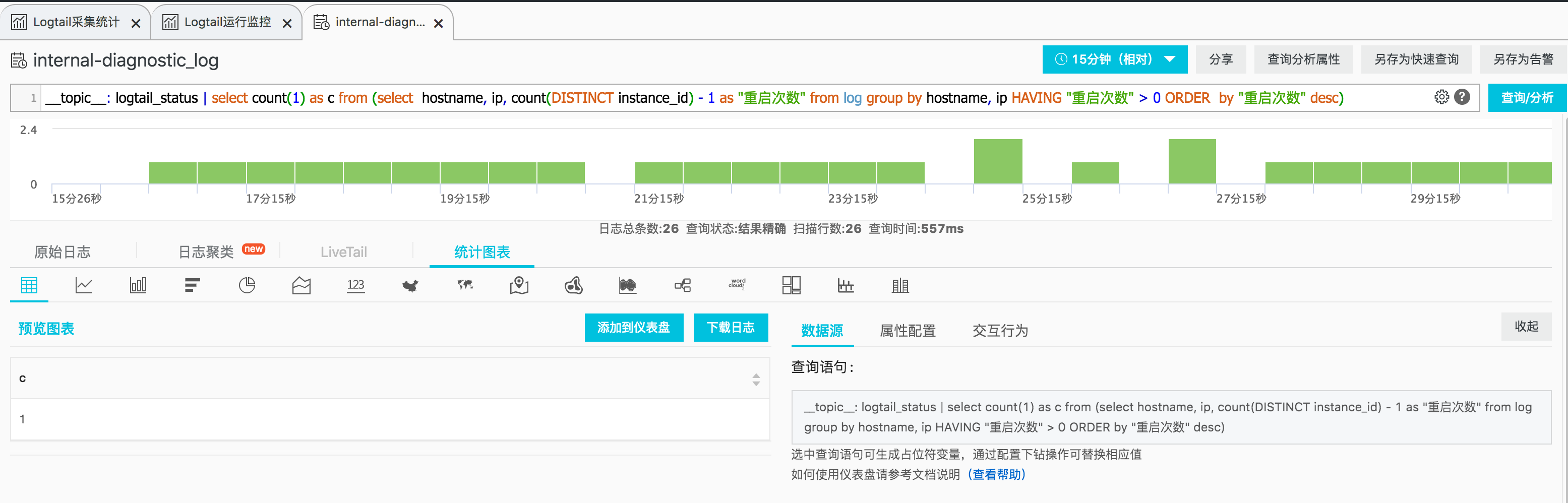
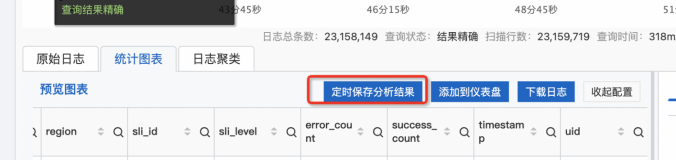
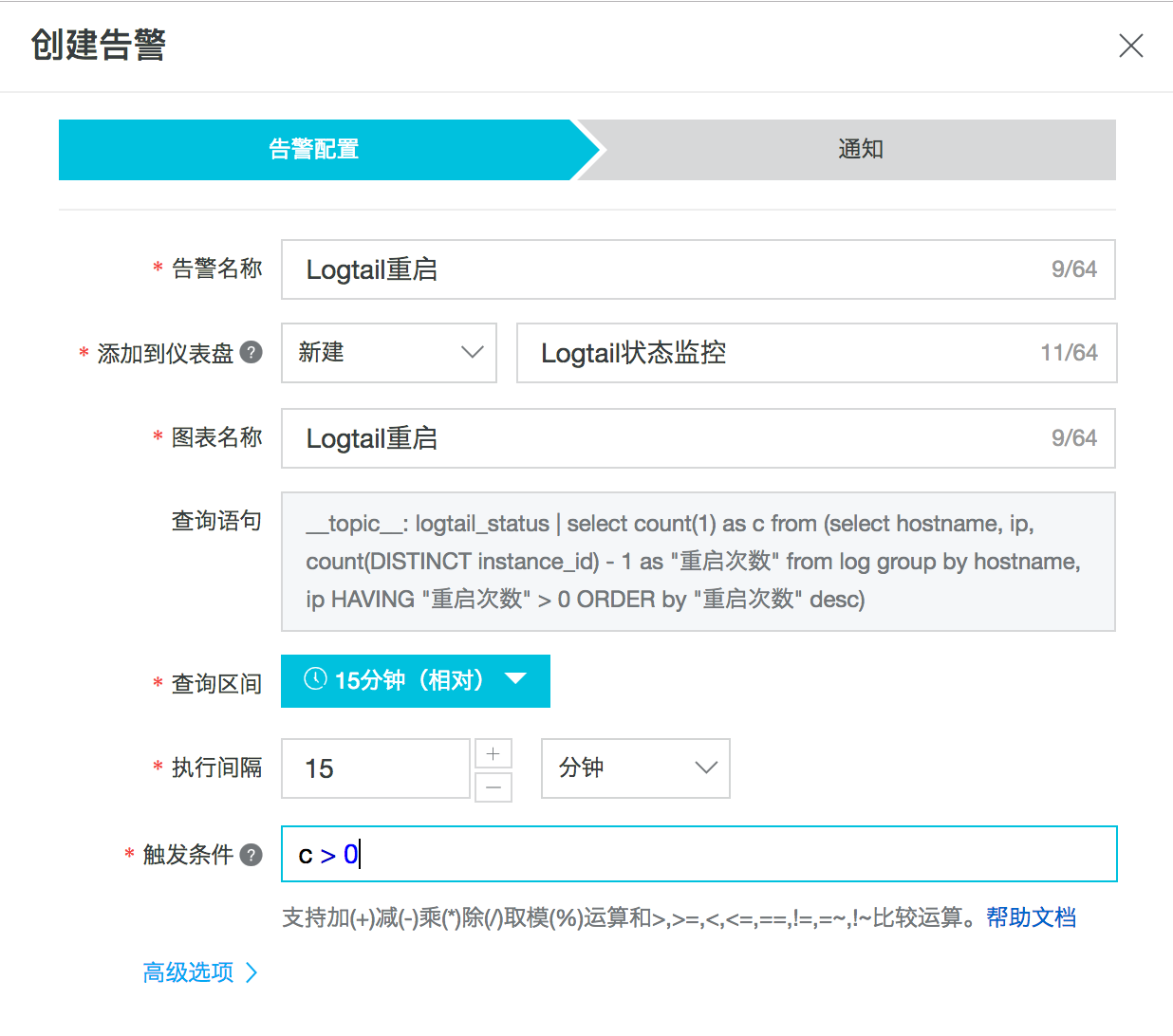
- 告警创建。在得到了目标的查询语句后,点击界面右上角的另存为告警,即可进行告警创建,如下图所示。
使用 logtail_alarm 监控重启
除了 logtail\_status 以外,我们还可以通过 logtail\_alarm 来部分实现这一需求(因为资源超限场景不会产生 alarm)。logtail\_alarm 也是服务日志的一部分,它记录了 Logtail 上报的错误日志,每 30 秒记录并上报一次,30 秒内重复出现的错误类型只记录错误总和,错误消息则随机选择一条。
文档日志采集错误类型记录了 Logtail 所上报的所有错误类型,其中与重启相关的错误有 LOGTAIL\_CRASH\_ALARM 和 LOGTAIL\_CRASH\_STACK\_ALARM 两个。简单来说,只要发生了 worker 进程异常退出,前者就会上报,如果是因为崩溃引起的退出且生成了 coredump,后者就会被上报。
由于先前已经给出过详细操作步骤的示例,此处我们就不再赘述,只给出用于设置报警的查询语句,如下:
__topic__:logtail_alarm and (alarm_type : LOGTAIL_CRASH_STACK_ALARM or alarm_type:LOGTAIL_CRASH_ALARM) | select count(*) as c重启原因分析及解决思路
为了分析重启原因,可以在告警触发后,回到 internal-diagnostic\_log logstore 的查询控制台,将时间切换到告警对应的范围,执行对应的查询语句来定位引起告警的机器(根据原始日志中的 IP 信息),再具体分析相关的原因。
资源超限
登录 Logtail 所在机器,查看 Logtail 安装目录(比如 /usr/local/ilogtail)下的 ilogtail.LOG 以及其轮转文件,以关键词 [error](大小写不敏感)进行搜索,如果发现重启时间点附近有如下日志即说明是资源超限引起的重启。
*** Resource used by program exceeds upper limit:prepare restart Logtail
cpu_usage:*** mem_rss:***对于此问题,需要根据引起超限的资源类型来区分对待:
CPU
- Logtail 中对于 CPU 开销较大的部分为解析部分,最常见的 CPU 过高的场景是正则表达式性能过差(包括基于正则表达式的 Nginx、Apache 等日志的采集)。对此,可以到 regex101 等网站上使用样本数据测试一下正则的性能。
- 另外,通过比较重启时间点前后的 logtail\_status 日志,看看是否是突然的大数据量到来导致 CPU 飙升(burst),如果是的话,排查一下原因。
内存
- 正常情况下,即使数据量很大,因为内部队列长度有限,Logtail 的内存一般不会超过 1G。
目前引起内存超过 1G 的最常见情况是指定的目录中内容过多,导致 Logtail 轮询占用过多内存。
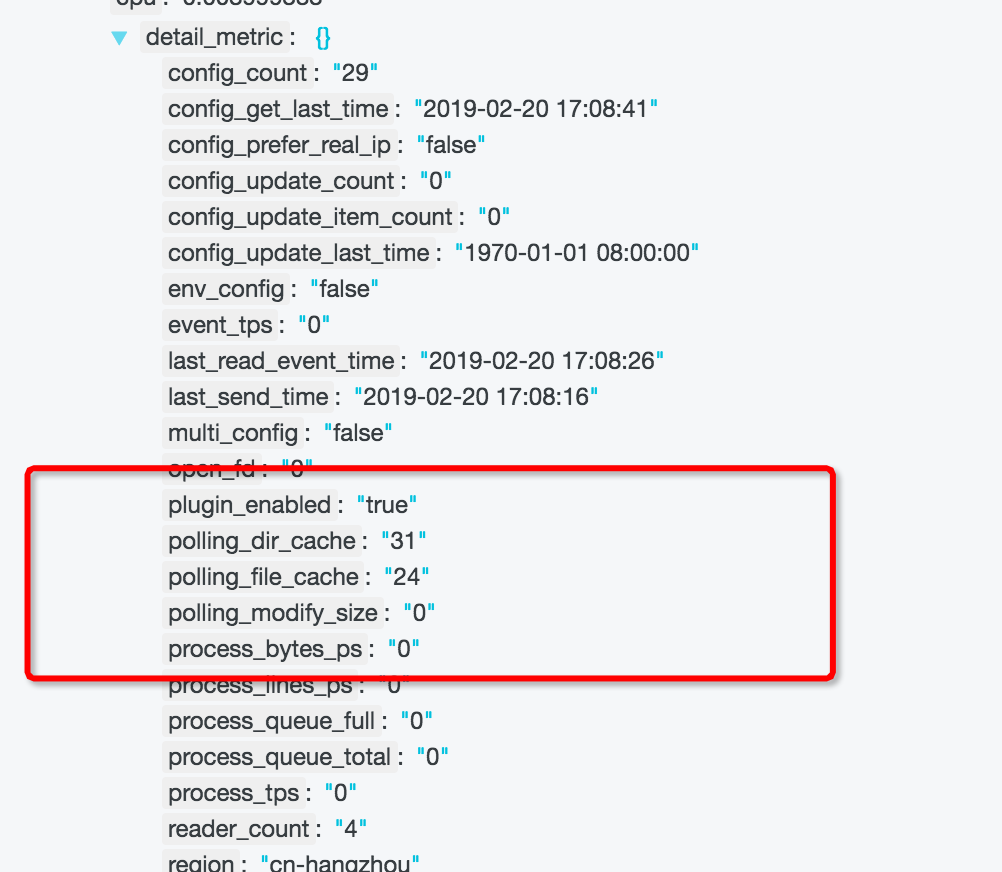
- 此问题可以通过查看 logtail\_status 来确定,在该日志中,有一个 JSON 类型的 detail\_metric 字段,其中有 polling_dir_cache 和 polling_file_cache 两个整数值。如果连续的几条日志中,该值很大(最大为 100000)或者有些日志中字段缺失(说明一分钟内未轮询完),则很大可能发生了此问题。
- 对于这个问题,可以重新调整一下采集配置的根目录和递归深度进行解决。
- 此问题可以通过查看 logtail\_status 来确定,在该日志中,有一个 JSON 类型的 detail\_metric 字段,其中有 polling_dir_cache 和 polling_file_cache 两个整数值。如果连续的几条日志中,该值很大(最大为 100000)或者有些日志中字段缺失(说明一分钟内未轮询完),则很大可能发生了此问题。
如果确定资源超限并非异常引起或者已无更好的优化办法,则需要上调 Logtail 所使用的资源限制,可以参考此文档。
代码缺陷 or 意外退出
如果在 logtail\_alarm 中发现了 LOGTAIL\_CRASH\_STACK\_ALARM,则证明一定是代码缺陷导致的崩溃。如果只有 LOGTAIL\_CRASH\_ALARM,除了则需要排查一下是否是运维或者其他程序误杀。
宿主机资源状态
对于一些资源比较紧张的节点,我们不能够让 Logtail 占用过多的宿主机资源以避免影响到业务的正常运行,因此,我们需要对这些资源状态进行监控。
上一章所提及的资源超限一定程度上限制了 Logtail 的资源使用,但是资源超限需要持续地达到一定的时间(默认 10 分钟)才会触发重启,这期间 Logtail 会持续地占用资源(内部的资源控制无法完全保证其降低),有可能会影响到业务的正常运行。更糟糕的情况是在每个 10 分钟周期内,90% 的时间占用了过多资源,而 10% 的时间恢复正常,这种情况下,Logtail 将不会超限重启,但是 90% 的时间内占用了过多资源,影响业务。
以下我们将分别介绍如何利用 logtail\_status 日志来实现对 CPU、内存、网络流量进行监控。出于篇幅,我们将直接给出查询语句,不再赘述其他的步骤。
CPU
CPU 的监控需要使用到 cpu 字段,它表示上报此条日志时 Logtail 最近一次的 CPU 占用状态(目前仅支持 Linux)。基于它我们可以实现如下的一系列监控需求:
-- 监控所有 Logtail 的平均 CPU:
__topic__: logtail_status | select round(avg(cpu) * 100, 2) as total
-- 监控 CPU 占用最高的 Logtail:
__topic__: logtail_status | select round(max(cpu) * 100, 2) as total
-- 监控特定 Logtail 的平均 CPU 占用:
__topic__: logtail_status and hostname:xxx | select round(avg(cpu) * 100, 2) as total内存
类似地,memory 字段表示上报此条日志时 Logtail 最近一次的内存占用状态(MB 为单位)。
-- 监控所有 Logtail 的平均内存:
__topic__: logtail_status | select round(avg(memory) , 2) as total
-- 监控内存使用最高的 Logtail:
__topic__: logtail_status | select round(max(memory) , 2) as total
-- 监控特定 Logtail 的平均内存:
__topic__: logtail_status and hostname:xxx | select round(avg(memory) , 2) as total网络
基于 detail\_metric 中的 send-net-bytes-ps 实现。
-- 监控所有 Logtail 在这段时间内的平均网络流量(MB/s)
__topic__: logtail_status | SELECT round(avg("send-net-bytes-ps") / 1024.0 / 1024.0, 3) as total from log
-- 特定 Logtail 在这段时间内的平均网络流量(MB/s)
__topic__: logtail_status and hostname:xxx | SELECT round(avg("send-net-bytes-ps") / 1024.0 / 1024.0, 3) as total from log数据采集状态
以网络协议栈来做一个可能不太恰当的类比,之前所属的三层就像是应用层以下,而数据采集状态则是应用层。在前三层状态正常的情况下,数据采集状态包含 Logtail 根据用户配置去执行数据采集、数据解析、数据发送等过程中,所产生的统计、错误等信息。
采集错误
日志采集错误类型中的大部分错误都与数据采集状态相关,对错误状态的及时告警和处理有助于我们修复日志采集中潜在的错误。
监控采集错误的查询语句非常简单,如下:
-- 单个错误
__topic__: logtail_alarm and alarm_type:TYPE_NAME | select count(*) as c
-- 多个错误
__topic__: logtail_alarm and (alarm_type:TYPE_NAME1 or alarm_type:TYPE_NAME2) | select count(*) as c以下我们简单地介绍几个比较重要以及常用的采集错误(可能原因和处理方式可参考文档),建议为它们均设置上相应的监控:
数据解析出错
- REGEX\_MATCH\_ALARM:正则解析错误。配置时可利用它来辅助正则调整,运行时如果出现此告警,则说明日志文件格式可能不统一,无法使用单一正则表达式进行解析。
- PARSE\_LOG\_FAIL\_ALARM:分隔符、JSON 日志解析错误。作用类似于 REGEX\_MATCH\_ALARM。
数据丢失
- SEND\_DATA\_FAIL\_ALARM:数据发送失败被丢弃。
- DROP\_LOG\_ALARM:同一个文件的轮转队列过长,一般是由于配置 Logtail 使用的 CPU 资源不够或是网络发送流控导致数据积压引起的。
- OUTDATED\_LOG\_ALARM:日志被视为过期日志(落后 12 小时)而被抛弃。Logtail 默认只采集增量数据,可参考文档进行历史数据采集。
- DISCARD\_DATA\_ALARM:数据被抛弃。
数据延迟
- READ\_LOG\_DELAY\_ALARM
如果一开始实在不知道如何设置的话,可以先直接监控所有的错误,然后后续再根据需要进行调整(比如过滤掉一些可忽略的错误),如下:
-- 监控所有的
__topic__: logtail_alarm | select count(*) as c
-- 剔除掉一些
__topic__: logtail_alarm not alarm_type:TypeA not alarm_type:TypeB | select count(*) as c统计状态
logtail_profile 也是服务日志的一部分,它记录了 Logtail 的文件采集统计信息,每 10 分钟上报一次。基于它可以实现一些对文件采集状态的细节监控,以下我们简单地介绍一些常用场景。
文件采集延迟
理想情况下,文件新增的数据应该在它被更新时就采集并发送到日志服务,但因为网络、CPU 资源限制等原因,可能会出现一定的延迟,但延迟如果超过一定阈值的话,则说明可能存在一些问题。因此,我们需要对文件采集延迟进行监控。
在 logtail\_profile 中,有一个 read\_avg\_delay,它会在 Logtail 每次读取文件时被更新,记录下当前已读取 offset 和文件大小之间的差距,即当前未读内容的大小,以此来表示 delay。因此,我们可以使用如下的查询语句来获取最近时间内各个文件的采集延迟:
__topic__: logtail_profile AND not file_name : logstore_statistics | select file_name, avg(read_avg_delay) / 1024 / 1024.0 as delay from log group by file_name order BY delay DESC效果如下所示:

可以看到,延迟最大的文件达到了 72M,为了进行监控,我们可以对如上语句进行一个聚合,比如说监控延迟最大的文件,当它超过 1M 时即进行告警。查询语句如下:
__topic__: logtail_profile AND not file_name : logstore_statistics | select max(delay) as m from (select file_name, avg(read_avg_delay) / 1024 / 1024.0 as delay from log group by file_name order BY delay DESC)特定文件异常监控
当采集对应的文件很敏感时,我们可以为它建立单独监控,当发现任何的解析失败、发送失败以及过大的延迟时,进行告警。查询语句如下:
__topic__: logtail_profile AND not file_name:logstore_statistics | select parse_failures as pf, send_failures as sf, read_avg_delay as r from log where file_name='/path/to/your_file'设置告警时可使用此表达式: pf > 0 || sf > 0 || r > 1024*1024。
自定义状态监控
在常用状态监控这一部分里,我们给大家介绍了各层状态中的一些常用场景,以及如何为它们编写查询语句和设置告警。一般来说,直接按照该部分进行设置就能够满足大部分的监控告警场景的需求,但我们依旧可以通过自行编写一些特殊的查询语句来满足业务所需。比如希望有一个大盘来对业务中使用 Logtail 进行采集的文件状态进行直观地展示,那么自定义一些查询语句、选择所需的图表来构建一个仪表盘更能满足所需。
预设仪表盘
在开通服务日志的时候,会同时创建两个名为 Logtail采集统计 和 Logtail运行监控 的仪表盘,其中包含了一系列的预设图表,我们可以以它们为参考(包括所使用的查询语句、图表配置等),根据自身业务需要,进行相应的修改。
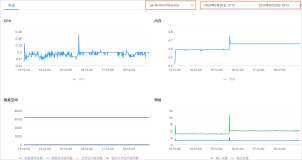
如下是 Logtail运行监控 仪表盘的截图。


我们可以通过如下方式查看一个图表关联的查询语句:首先将鼠标悬停到目标图表上方,然后悬停在右上角出现的省略号上,点击弹出菜单的查看分析详情即可跳转到对应的查询窗口,如下图所示。
使用更多字段
事实上,服务日志还提供了不少的字段,前一部分中提及的查询语句并没有完全的覆盖。通过阅读文档,利用这些字段,能够更好地实现我们的需求。
以下我们简单地举一些使用这些日志字段的例子。
使用 project/logstore 字段
之前提及的三类日志都拥有一个 project 字段,我们可以利用它来筛选出所关注的 project,比如说一个 Logtail 节点同时采集了多个 project 下的配置,如果有些 project 下的数据重要程度并不是特别高,则可以使用 not project:xxx 这样的查询语句将它们过滤掉。类似地,有些日志提供了 logstore 字段,能够帮助我们进一步地缩小关注范围。
使用 alarm_count 字段
在 logtail\_alarm 日志中,有一个 alarm\_count 字段,它表示在时间窗口(即相邻两次上报之间)内该类型错误的数量,我们可以基于它进行一些监控。
以 SEND\_QUOTA\_EXCEED\_ALARM 为例,它表示当前日志写入流量超出限制。对于正常业务来说,偶尔的流量突增可能会带来少量的此错误,因此可以忽略,但是一旦短时间内此错误数量(alarm\_count)超过了一定阈值,则说明当前可能存在其他的问题,比如:
- 业务出现问题,大量错误日志引起写入流量激增,需要排查问题。
- 其他业务和此业务共享 project,占用了 project 整体的 quota,需要上调 project 级别的 quota。
- ...
小结
在本文中,我们首先按照分层的思想对 Logtail 状态进行了划分,并对各层的状态内容进行了分析和简要介绍。接着,我们自底向上地介绍了各层中一些常用的状态监控场景,并给出了配置它们所需要的代码、查询语句以及操作的步骤,方便大家可以直接构建出所需的监控和告警。最后,我们简单地说明了一下如何利用预设的仪表盘以及服务日志的其他字段来进行一些自定义的需求配置。
更多阅读
- 服务日志功能简介
- Logtail 日志采集错误类型
- 日志服务 CLI 使用文档
- 欢迎加入钉钉群进行讨论交流