背景信息
日志作为一种特殊的数据,对处理历史数据、诊断问题以及了解系统活动等有着非常重要的作用。对数据分析人员、开发人员或者运维人员而言,日志都是其工作过程中必不可缺的数据来源。
通常情况下,为节约成本,我们会将日志设定一定的保存时间,只分析该时间段内的日志,此类日志称之为“热”日志。这种做法,短期内可以满足使用需求,但从长期来看,大量的历史日志被搁置,无法发挥其价值。
对于许多企业而言,对日志分析的需求特征通常为低时效和低频率。并且在一个企业中,为偶发性的日志分析去构建一套完整的日志分析系统,无论在经济成本还是运维成本上都是不划算的。如何在降低存储成本的同时满足大批量日志的分析需求,是摆在企业面前的一道难题。
实施方案
阿里云从用户角度出发,研发了一整套小而精的历史日志数据分析方案。利用阿里云日志服务 LOG(Log Service,简称LOG/原SLS)来投递日志,阿里云对象存储服务(Object Storage Service,简称OSS)来存储日志,Data Lake Analytics(DLA)来分析日志。该方案有以下三个优势:
-
LOG是针对实时数据一站式服务,在阿里集团经历大量大数据场景锤炼而成。提供日志类数据采集、智能查询分析、消费与投递等功能,全面提升海量日志处理/分析能力。LOG强大的日志投递能力,能够从源头对接各种类型的日志格式,并且稳定地将日志投递到指定的位置。
-
OSS低廉的存储成本,能够让您的日志文件存储任意长的时间。
-
DLA强大的分析能力,Serverless的架构,按扫描量收费。DLA可以对投递到OSS上的日志按年、按月、按日进行多维度的分区,提高日志的命中率,降低扫描量,从而以极低的成本、极高的性能来完成大数据量历史日志分析。

例如,服务部署在云服务器ECS(Elastic Compute Service,简称ECS)集群上,该集群的每台机器上都有一个记录访问情况的日志access.log。希望能够对access.log进行信息抽取,并将过滤后的信息存储至OSS上。本文档将以此为例,详细为您介绍实施步骤。
前提条件
在开始实施步骤之前,需要先完成以下准备工作。
-
参考文档LOG快速入门,开通日志服务、创建项目、创建日志库。
实施步骤
步骤一:通过Logtail采集ECS日志。
详细操作请参见通过Logtail采集ECS日志。
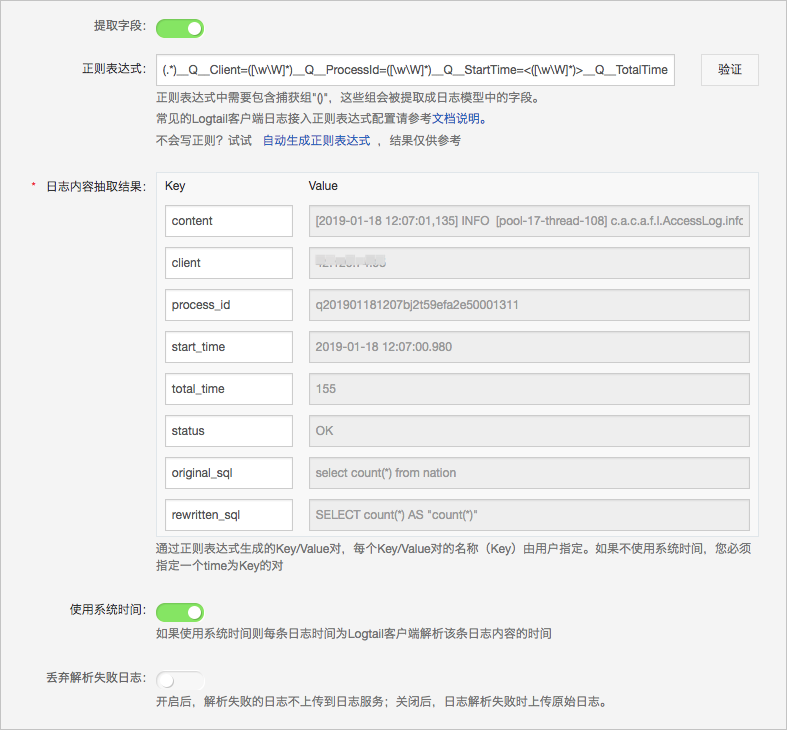
根据本示例中的日志文件特点,Logtail配置如下所示。

模式选择完整正则模式,需要提供完整正则表达式。
步骤二:投递日志到OSS
详细操作请参见投递日志到OSS,并且日志服务投递OSS使用Parquet存储的相关配置。
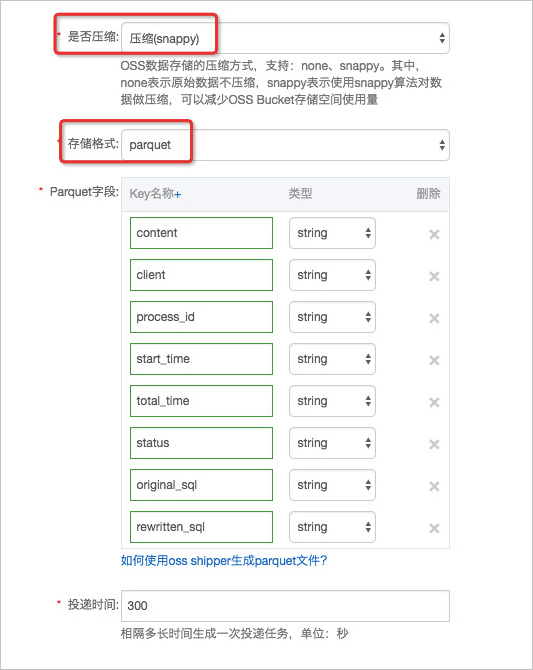
在OSS投递功能页面,配置各项参数:

参数说明:
-
OSS Bucket和OSS Prefix设置日志投递到OSS的哪个目录。
-
修改分区格式,将分区列的名字填入到目录中,格式为分区列名=分区列值。
如图所示,修改分区格式默认值,即一级分区列的列名为year,列值为%Y; 二级分区列的列名为month,列值为%m;三级分区列的列名为day,列值为%d。
-
存储格式设置为parquet。
-
压缩方式设置为snappy,使用snappy算法对数据做压缩,可以减少OSS Bucket存储空间使用量。
日志数据投递到OSS中以后,就可以通过DLA读取并分析OSS中的日志。
步骤三:在DLA中创建OSS连接
登录DLA控制台,登录DMS,在DLA中创建一个到OSS的连接。语法如下:
CREATE SCHEMA oss_log_schema with DBPROPERTIES(catalog='oss',location = 'oss://myappbucket/sls_parquet/');
location:日志文件所在的OSS Bucket的目录,需以/结尾表示目录。myappbucket是OSS Bucket名字。
步骤四:在DLA中创建指向OSS日志文件的外表(分区表)
CREATE EXTERNAL TABLE sls_parquet (content STRING,client STRING,process_id STRING,start_time STRING,total_time STRING,status STRING,original_sql STRING,rewritten_sql STRING) PARTITIONED BY (year STRING, month STRING, day STRING)STORED AS PARQUETLOCATION 'oss://myappbucket/sls_parquet/';
注意:
新建表中的列名要和生成的parquet文件中设置的列名一致。
分区列的名称、顺序需要和步骤二:投递日志到OSS中的分区列一致。更多创建分区表信息,请参见通过DLA创建OSS分区表。
步骤五:使用MSCK命令更新分区信息
外表创建成功后,执行MSCK REPAIR TABLE将分区信息同步到DLA中。MSCK命令只能识别符合DLA分区列命名规则的目录,即分区列的目录名为分区列名=分区列值。
步骤六:查询分区表数据
分区信息同步完成后,使用SELECT语句对日志进行查询分析。例如,得到某一天查询最慢的5条语句。
SELECT original_sql, total_timeFROM sls_parquetWHERE client!=''ORDER BY total_time DESCLIMIT 5;
后续操作
上述示例中,日志数据投递OSS的存储格式为Parquet格式,除了Parquet格式,LOG还可以将投递文件的格式设置为JSON和CSV。详细的配置,请参见JSON格式和CSV格式。
JSON格式
-
当投递文件的格式设置为JSON且无压缩时,建表语句为:
CREATE EXTERNAL TABLE sls_json (content STRING,client STRING,process_id STRING,start_time STRING,total_time STRING,status STRING,original_sql STRING,rewritten_sql STRING) PARTITIONED BY (year STRING, month STRING, day STRING)STORED AS JSONLOCATION 'oss://myappbucket/sls_json/';
-
当投递文件的格式设置为JSON且使用标准Snappy压缩时,建表语句为:
CREATE EXTERNAL TABLE sls_json_snappy (content STRING,client STRING,process_id STRING,start_time STRING,total_time STRING,status STRING,original_sql STRING,rewritten_sql STRING) PARTITIONED BY (year STRING, month STRING, day STRING)STORED AS JSONLOCATION 'oss://myappbucket/sls_json_snappy/'TBLPROPERTIES('text.compression'='snappy','io.compression.snappy.native'='true');
CSV格式
-
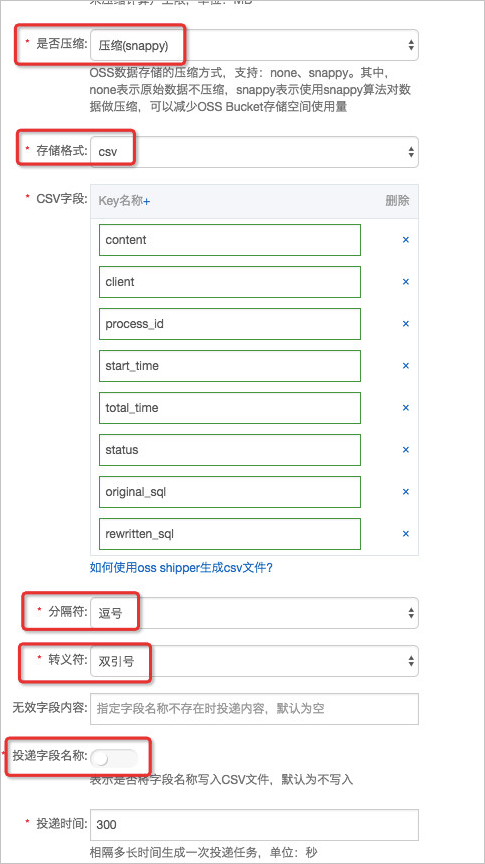
当投递文件的格式设置为CSV,不包含header,使用标准Snappy压缩时,建表语句为:
CREATE EXTERNAL TABLE sls_csv_snappy (content STRING,client STRING,process_id STRING,start_time STRING,total_time STRING,status STRING,original_sql STRING,rewritten_sql STRING) PARTITIONED BY (year STRING, month STRING, day STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES('separatorChar'=',','quoteChar'='"','escapeChar'='\\')STORED AS TEXTFILELOCATION 'oss://myappbucket/sls_csv_snappy/'TBLPROPERTIES('text.compression'='snappy','io.compression.snappy.native'='true','skip.header.line.count'='0');
-
当投递文件的格式设置为CSV无压缩,且包含header时,建表语句为:
CREATE EXTERNAL TABLE sls_csv (content STRING,client STRING,process_id STRING,start_time STRING,total_time STRING,status STRING,original_sql STRING,rewritten_sql STRING) PARTITIONED BY (year STRING, month STRING, day STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES('separatorChar'=',','quoteChar'='"','escapeChar'='\\')STORED AS TEXTFILELOCATION 'oss://myappbucket/sls_csv/'TBLPROPERTIES('skip.header.line.count'='1');