热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
保障数字世界的安全壁垒:网络安全与信息安全探究
未来智能家居技术的发展趋势与应用前景
Python文件与目录操作:面试中的高频考点
未来AI技术的发展与应用前景
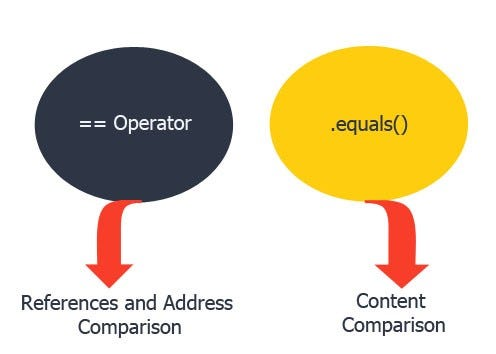
Java equals()方法与==运算符有何不同?
什么是Java泛型类型?
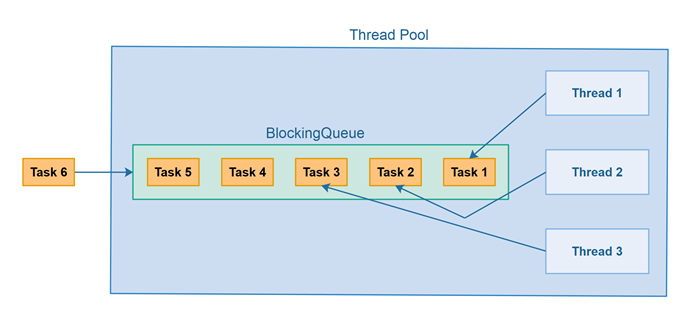
如何创建Java线程?
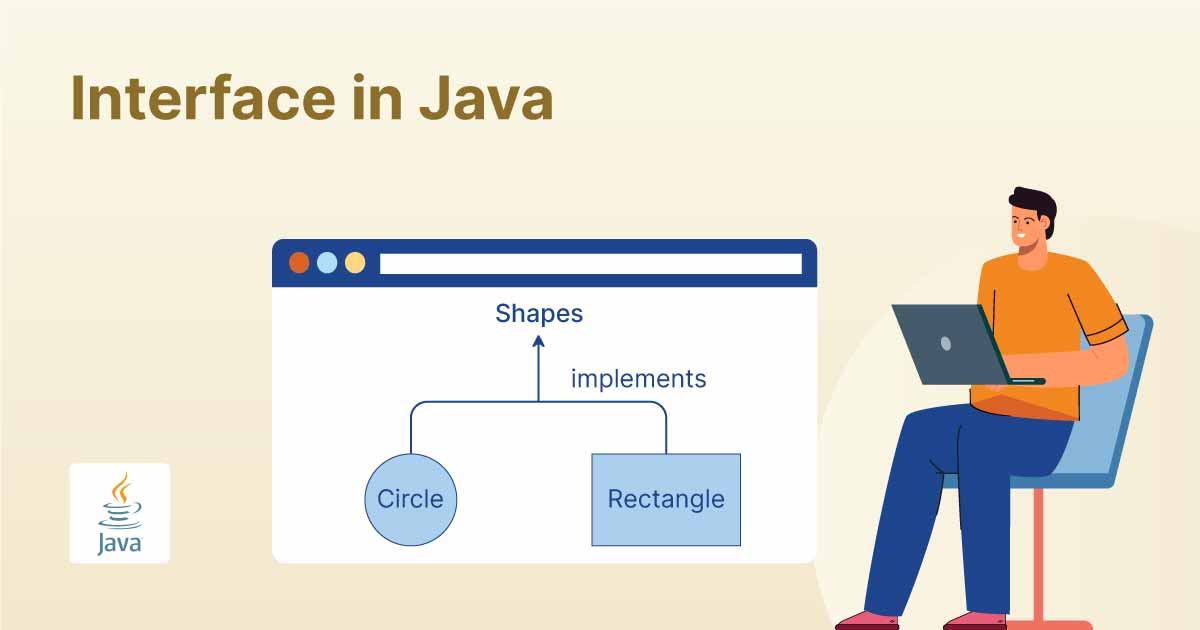
Java接口中可以定义哪些方法?
什么是Java函数式接口?
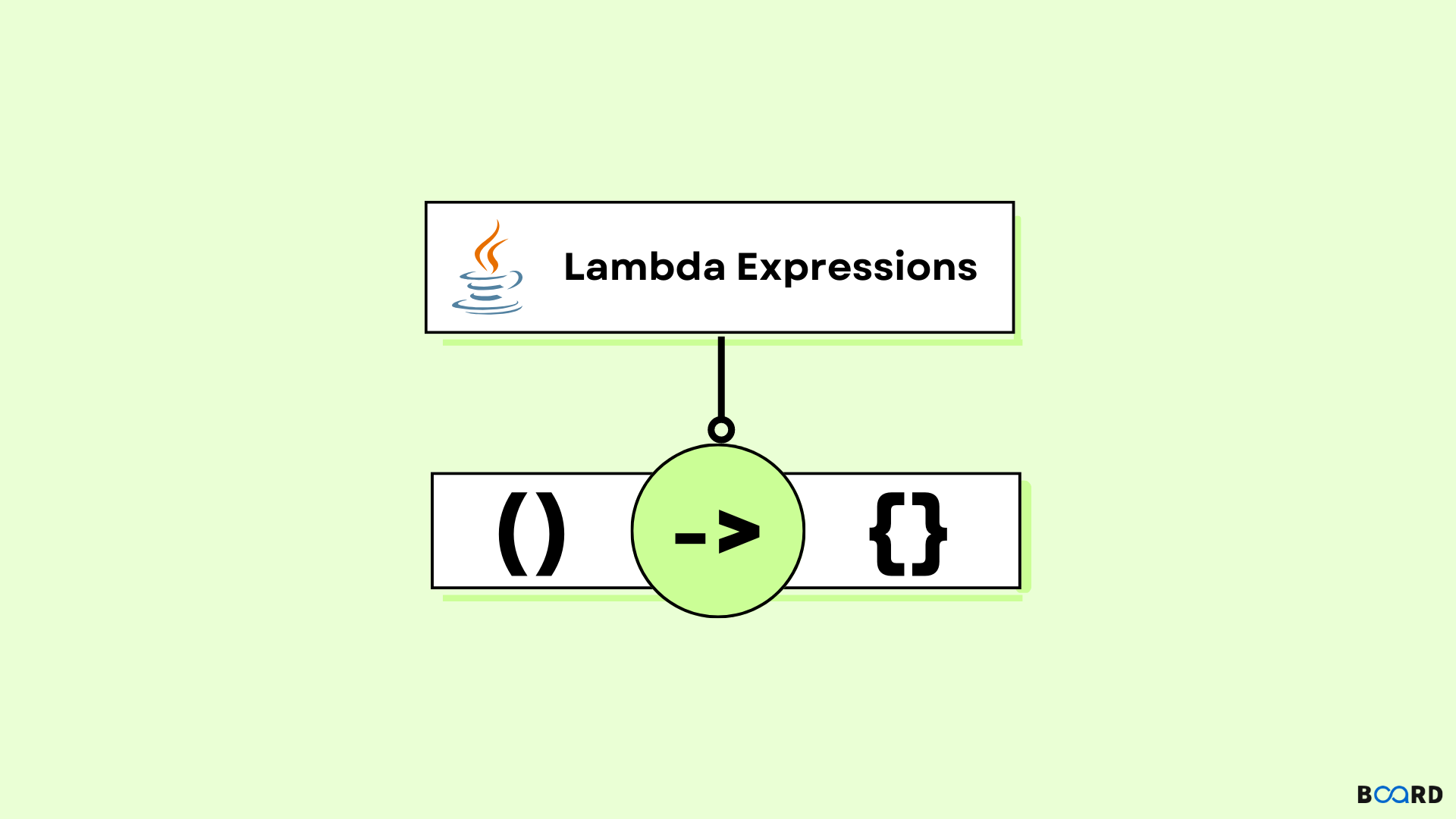
什么是Java Lambda表达式?
在 Java lambda 中使用时,什么类型的变量必须是最终变量或有效最终变量?
未来智能城市中的人脸识别技术发展趋势
Java中如何克隆一个对象?
什么是Java内部类,为什么使用它?
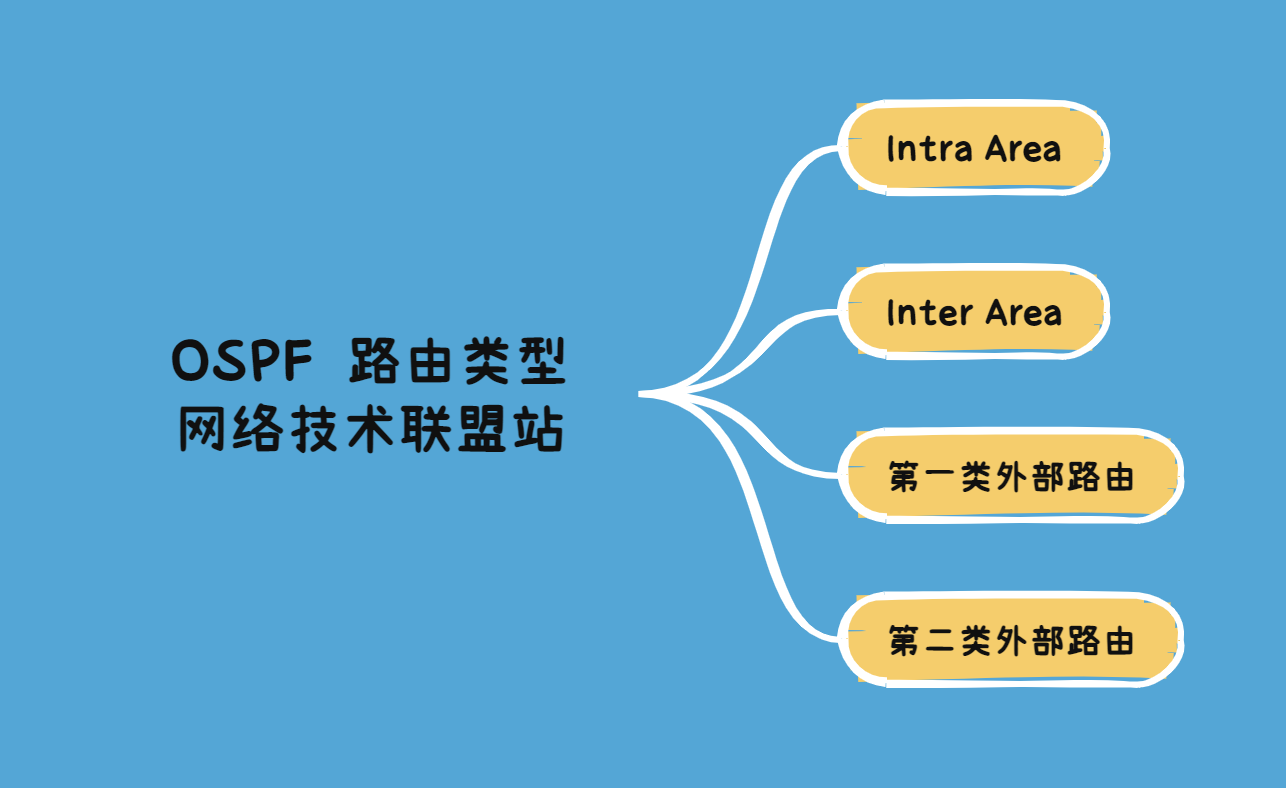
OSPF 四种路由类型:Intra Area、Inter Area、第一、二类外部路由
技术创新与人性:找到平衡的关键
未来智能家居技术的前沿探索
Python网络编程面试题精讲
邮件营销ROI大揭秘:让你的邮件成为投资的利器
【Docker项目实战】使用Docker部署FileGator文件管理器
软件体系结构 - Redis 技术架构
怎样设置邮件过滤?提升工作效率的必杀技
Vue是如何实现响应式系统的
Vue是如何实现的
谈谈springboot里面的守护线程与本地线程
你知道 React 和 Vue 的区别?
代理服务器拒绝连接怎么办
常见ip被限制的原因以及解决办法
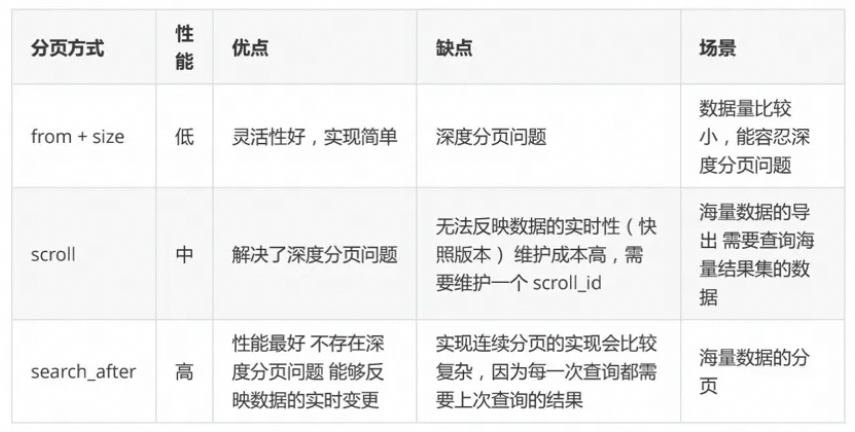
这些年背过的面试题——ES篇
为什么用了代理ip访问网站还是被限制了
正向代理和反向代理的区别
Vue的缓存组件 | 详解KeepAlive
论代理ip池的重要性
代理ip全局代理是什么且如何设置
代理ip的用途及是否可以降低延迟
智能制造领域智能问答系统
面向对象的C++题目以及解法2
动态规划:小美的元素删除
友元函数、成员函数和普通函数使用上的不同
模拟与高精度:最大乘积
蓝桥杯(基础题)
蓝桥杯:握手问题和小球反弹问题
顺序结构(入门题)
数据结构:线性表
深度优化搜索,字典树
二叉树和数据结构
高精度:[NOIP1999]回文数
小红的白色字符串