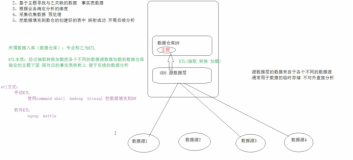
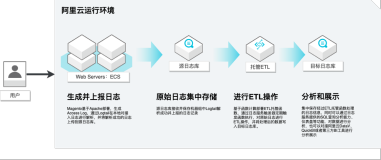
背景
CLI的命令中,可以看到有一个重要的参数config进行ETL的规则配置。这其实是一个Python模块,通过使用内置的模块对事件进行编排和处理。本篇介绍CLI ETL规则配置文件的使用细则,
编排和转换
一个例子
这里我们举一个服务器上多钟复杂日志格式的混合通过syslog发送给日志服务后的ETL的例子:
# 丢弃所有无关的元字段,例如__tag:...___等
DROP_FIELDS_f1 = [F_TAGS, "uselss1", "useless2"]
# 分发:根据正则表达式规则,设置__topic__的值
DISPATCH_EVENT_data = [
({"data": "^LTE_Information .+"}, {"__topic__": "let_info"}),
({"data": "^Status,.+"}, {"__topic__": "machine_status"}),
({"data": "^System Reboot .+"}, {"__topic__": "reboot_event"}),
({"data": "^Provision Firmware Download start .+"}, {"__topic__": "download"}),
(True, {"__topic__": "default"})] # 不匹配的默认__topic__值
# 转换:根据特定__topic__使用特定正则表达式,对字段`data`进行字段提取
TRANSFORM_EVENT_data = [
({"__topic__": "let_info"}, ("data", r"LTE_Information (?P<RSPR>[^,]+),(?P<SINR>[^,]+),(?P<global_cell_id>[^,]+),")),
({"__topic__": "machine_status"}, ("data", r"Status,(?P<cpu_usage_usr>[\d\.]+)% usr (?P<cpu_usage_sys>[\d\.]+)% sys,(?P<memory_free>\d+)(?P<memory_free_unit>[a-zA-Z]+),")),
({"__topic__": "reboot_event"}, ("data", r"System Reboot \[(?P<reboot_code>\d+)\]")),
({"__topic__": "download"}, ("data", r"Provision Firmware Download start \[(?P<firmware_version>[\w\.]+)\]"))
]这里虽然是Python文件,但并没有任何编程内容,但却可以借助于Python的工具进行语法校验。
编排规则
- 保留事件:
KEEP_EVENT_xxx = 条件列表 - 丢弃事件:
DROP_EVENT_xxx = 条件列表 - 保留字段:
KEEP_FIELDS_xxx = 字符串列表 - 丢弃字段:
DROP_FIELDS_xxx = 字符串列表 - 自动提取KV
KV_FIELDS_xxx =字符串列表 - 重命名字段
RENAME_FIELDS_xxx = {"field1": "new_field1","field2": "new_field2"} - 分派转换
DISPATCH_EVENT_xxx = 条件式转换列表
对于多个条件-转换,最多指向其中一组
- 串联转换
TRANSFORM_EVENT_xxx = 条件式转换列表
顺序指向多个条件-转换列表
条件列表
可以看到以上需要传入条件列表,可以有以下形式:
- 简单匹配: 字段值是否等于某个值
KEEP_EVENT_xxx = {"result": "pass"}
KEEP_EVENT_xxx = {"result": NOT("pass")}- 正则匹配: 字段值是否匹配某个正则表达式(完整匹配)
KEEP_EVENT_xxx = {"result": "(?i)ok|pass"}
KEEP_EVENT_xxx = {"result": NOT("(?i)ok|pass")}- UDF函数匹配 (Python):
KEEP_EVENT_xxx = {"status": lambda v: int(v) > 200}
KEEP_EVENT_xxx = lambda e: int(e['status']) > 200- 多条件And关系
KEEP_EVENT_xxx = {"result": "pass","status": "200" }
KEEP_EVENT_xxx = {"result": "pass","status": NOT("200") }- 多条件OR关系:
KEEP_EVENT_xxx = [{"result": "fail"},{"status": "400" },lambda e: int(e['retime']) > 1000 ]- 内置辅助工具:
DROP_EVENT_xxx = [EMPTY("user_input"),EXIST("error")]其他方法: NO_EMPTY, NONE, ANY, ALL, True
字符串列表
可以看到以上需要传入字符串列表,可以有以下形式:
- 字符串或数组:
DROP_FIELDS_xxx = "internal_field"
KV_FIELDS_xxx = ["data","message"]- 正则表达式:
DROP_FIELDS_xxx = r"internal_\w+"
KV_FIELDS_xxx = [r"data_\w+","message"]- 内置域:
KEEP_FIELDS_xxx = [F_TAGS,F_META,F_TIME,"f1","f2"]TAG: 所有__tag__:的字段, META: tag + topic + time字段
条件式转换列表
可以看到以上需要传入条件式转换列表,可以有以下形式:
-
条件列表,转换
满足条件的,进行转换(可以是多个) -
条件列表,[转换1, 转换2, ...]
满足条件式,串联进行多个转换
如下是一个转换的列表的样例:
[ {"result": V("ret") },
{"new_field1": "some value"},
{"resp_time_s": lambda e: int(e["resp_time_ms"])/1000 },
("msg",r"\d{1,3}\. \d{1,3}\. \d{1,3}\. \d{1,3}","ip")
]-
[(条件列表1,转换1), (条件列表2,转换2), (条件列表3,[转换3, 转换4, ...]), ...]
多个条件-转换的集合
样例:
# 根据字段data值特征,设定特定的topic:
DISPATCH_LIST_data = [ ({"data": "^LTE_Information "},{"__topic__": "etl_info"}), ({"data": "^Status,"},{"__topic__": "machine_status"}), ({"data": "^System Reboot "},{"__topic__": "reboot_event"}), ({"data": "^Provision Firmware Download start"},{"__topic__": "download"}), (True,{"__topic__": "unknown"})]内置数据转换模块
CLI ETL内置了大部分的主要ETL模块,并深度提供完整功能与定制:
- 设置列值(静态/复制/UDF):各种函数计算支持
- 正则提取列:正则的完整支持,包括动态提取字段名等
- CSV格式提取:CSV标准的支持
- 字典映射:直接字段映射
- 外部CSV多列映射:从外部CSV关联对数据进行富化,支持宽匹配等。
- 自动KV:自动提取KV,也支持自定义分隔符、auto-escape场景
- JSON自动展开:支持自动展开JSON内容,包括数组,支持展开过程的定制。
- JSON-JMES过滤:支持基于JMES的动态选择与计算后再处理。
- 分裂事件(基于JSON数组或字符串):基于字符串数组或JSON数组进行事件分裂
- 多列合并(基于JSON数组或字符串):基于字符串数组或JSON数组进行多字段合并
事件元处理
- 丢弃/保留事件:
DROP/ KEEP - 重命名字段:
ALIAS, RENAME
RENAME({"field1": "new_field1","field2": "new_field2"})- 丢弃/保留字段:
DROP_F/KEEP_F
格式: DROP_F/KEEP_F(字符串列表)
- 提取字段中KV:
KV_F
格式: KV_F(字符串列表)
- 样例:
TRANSFORM_LIST_data = [
({"data": "^LTE_Information "},DROP),
({"data": "^Download Event…."},RENAME({"f1": "f1_new"})),
({"data": "^Start event…."},DROP_F(["f3","f4"])),
({"data": "^Start event…."},KV_F(["f5","f6"])),
"…"]字段提取 - 关键字检查与覆盖模式
- 关键字字符集
字段提取时,一些内置方式会对关键字字符集做检查,不满足的会忽略:
- 执行此策略的模块有:REGEX(动态Key名),JSON、KV
- 默认:
[\u4e00-\u9fa5\u0800-\u4e00a-zA-Z][\w\-\.]* - 不符合规范的例子:
123=abc # KV, REGEX
1k=200 # KV, Regex
{“123”: “456”} # JSON- 设置覆盖模式
字段提取后,也会根据源时间是否包含次字段以及是否为空,提取的值本身是否为空等进行策略判断,不满足的会忽略:
- 执行此策略的模块有:REGEX、KV、CSV, Lookup, JSON
("msg",REGEX(r"(\w+):(\d+)",{r"k_\1": r"v_\2"}, mode="fill-auto")- 通过参数
mode进行配置,默认是fill-auto -
其他的参数意义:
- fill – 当原字段不存在或者值为空时
- add –当原字段不存在时设置
- overwrite – 总是设置
- fill/add/overwrite-auto – (当新值非空时才操作)
字段转换 – 映射列
有如下形式:
- 固定值:
{"new_field1": "some value"}- 复制列 V:
{"result": V("ret") }- 多个列中选择第一个非NULL的值复制( coalesce)
{"result": V("ret", "return_code", "result") }- 合并字段 ZIP:
{"result": ZIP("f1", "f2") }- UDF (Python):
传入事件本身,计算得出对应字段的值(返回None则忽略)
{"resp_time_s": lambda e: int(e["resp_time_ms"])/1000 }合并字段赋值– ZIP
- 两个字段合并:
{"combine": ZIP("f1", "f2")}- 支持数组:
{"f1": '["a","b","c"]', "f2":'["x","y","z"]'})
# >>
{…'combine': 'a#x,b#y,c#z'}- 支持字符串:
{"f1": 'a,b,c', "f2":'x,y,z'}) {…'combine': 'a#x,b#y,c#z'}- CSV读取:
{"f1": '"a,a", b, "c,c"', "f2":'x, "y,y", z'}
# >>>
{… 'combine': '"a,a#x","b#y,y","c,c#z"'}- 设置合并拼接分隔符/分隔符/quote
{"combine": ZIP("f1", "f2", combine_sep="@", sep="#", quote='|')}
# >>
{…'combine': 'a@x# b@y# c@z'}- 设置解析字段CSV的分隔符/quote
{"combine": ZIP("f1", "f2", lparse=("#", '"'), rparse=("|", '"') )}
# >>
{"f1": "a#b#c", "f2": "x|y|z"}字段转换 – 正则提取列
- 正则表达式 – 单值提取:
"msg",r"\d{1,3}\. \d{1,3}\. \d{1,3}\. \d{1,3}","ip"
"msg",REGEX(r"\d{1,3}\. \d{1,3}\. \d{1,3}\. \d{1,3}","ip”)- 正则表达式 – 多值提取:
"msg",r"\d{1,3}\. \d{1,3}\. \d{1,3}\. \d{1,3}",["server_ip","client_ip"]- 正则表达式 – 捕获:
"msg",r"start sys version: (\w+),\s*err: (\d+)",["version","error"]- 正则表达式 – 命名捕获:
"msg",r"start sys version: (?P<version>\w+),\s*err: (?P<error>\d+)"注意:如果运行环境是Python2的话,命名不支持中文。
- 正则表达式 – 动态字段名:
"msg",r"(\w+):(\d+)",{r"k_\1": r"v_\2"}字段提取 – CSV
- 设置字段列表
("input_field",CSV("F1,F2,F3,F4"))
("input_field",CSV(["F1","F2","F3","F4"]))- 设置字段列表 (TSV-'t', PSV-'|')
("input_field",TSV("F1,F2,F3,F4"))
("input_field",PSV("F1,F2,F3,F4"))- 设置分隔符/包括符 (单字符)
("input_field",CSV(["F1","F2","F3","F4"],sep="#",quote='|'))- 配置匹配严格度(个数匹配要一致, 否则跳过)
("input_field",CSV(["F1","F2","F3","F4"],restrict=True) )字段提取 – 字典
- 单值映射
("pro",LOOKUP({"1": "TCP","2": "UDP","3": "HTTP"},"protocol"))- 多字段映射 (依次映射,如果字段存在)
(["pro","protocol"],LOOKUP({"1": "TCP","2": "UDP","3": "HTTP"},"protocol")) - 设置默认值
("pro",LOOKUP({"1": "TCP","2": "UDP","3": "HTTP","*": "Unknown"},"protocol"))- 设置匹配时大小写敏感 (默认不敏感)
("pro",LOOKUP({"http": "tcp","dns": "udp","https": "tcp","*": "Unknown"},"type", case_insensitive=False))字段提取 – Lookup
- 多值映射 – 表格
(["f1",'f2','f3'],LOOKUP("./data.csv",['out1','data2’])- 多值映射 – 别名调整
([("f1","f1_alias"),("f2","f2_alias"),'f3'],LOOKUP("./data.csv",[('out1','out1_alias'),'data2']))- CSV加载设置 – 分隔符/quote
("city",LOOKUP("./data.csv",["province","pop"],sep='#' , quote=‘|’)- CSV加载设置 – 设置头
(“city”,LOOKUP(“./data.csv”,[“province”,“pop”], headers=“city, pop, province”)
(“city”,LOOKUP(“./data.csv”,[“province”,“pop”], headers=[“city”, “pop”, “province”])- 设置匹配大小写敏感
("pro", LOOKUP(csv_path, "type", case_insensitive=False))- 支持默认匹配
例如CSV格式如下,其中*可以匹配任意值:
CSV: c1,c2,d1,d2\nc1,*,1,1\nc2,*,2,2,*,*,0,0- 内置缓存机制
字段提取 – 自动KV
- 自动提取KV
("f1",KV )
KV_F("f1")- 指定多个字段
(["f1", "f2"],KV )
KV_F(r"f1_\w+")- 设置新字段前后缀
("f1",KV(prefix="f1_",suffix="")- 设置分隔符(正则), Quote(单字符)
("f1",KV(sep="(?:=|:)", quote="|")- 设置值反转(escape)
("f1",KV(escape=True) # key="abc\"xyz" 值是 abc"xyz
("f1",KV(quote="’", escape=True) # key=‘abc\’xyz’ 值是 abc’xyz字段自动展开 – JSON
- 支持自动展开JSON对象
("json_data_filed",JSON)- 展开的关键字格式化方式:
- 设置节点Key的前后缀:
("data", JSON(prefix="__", suffix="__"))- 关键字简单展开:
("data", JSON(fmt=‘simple')) # 默认格式化方式- 关键字完整展开:
("data", JSON(fmt=‘full')) # 默认分隔符是 '.'- 关键字父节点+当前节点展开:
("data", JSON(fmt=‘parent', sep="_"))- 其他展开方式: root, 可传入自定义字符串甚至格式化函数
- 支持数组展开:
- 默认开启, 可关闭:
("json_data_filed",JSON(expand_array=False))- 默认关键字命名规则:
{parent}_{index}- 可定制Key格式:
("json_data_filed",JSON(fmt_array="{parent_rlist[0]}-{index}"))字段展开 – JSON
- 展开深度
默认最大100层,如下设置展开深度(第一层):
("json_data_filed", JSON(depth=1)- 展开节点关键字名设置
- 默认白名单:
[\u4e00-\u9fa5\u0800-\u4e00a-zA-Z][\w\-\.]* - 白名单(正则):
("json_data_filed", JSON(include_node=r'key\d+')- 黑名单(正则):
("json_data_filed", JSON(exclude_node=r'key\d+')- 设置了白名单, 必须在白名单中才可能会放入结果.
- 设置了黑名单, 必须不在黑名单中才会放入结果中.
- 展开节点路径:
- 同上, 正则方式,通过参数
include_path与exclue_path - 开头匹配. 从路径开头匹配. 匹配路径是以
.分隔.
字段提取 – JSON
- 使用JMES提取, 查询, 过滤字段:
- 选择:
("data",JSON(jmes="cve.vendors[*].product",output="product"))- 计算:
("data",JSON(jmes="join(`,`, cve.vendors[*].name",output="vendors"))- 计算:
("data",JSON(jmes="max(words[*].score)",output="hot_word"))- 不忽略null:
("data",JSON(jmes="max(words[*].score)",output="hot_word", jmes_ignore_none=False))- 支持JMES提取后, 再展开
- 未设置
output的情况下, 自动打开:
("data",JSON(jmes="cve.vendors[*].product",))- 设置了
output字段时,需要配置expand才打开:
("data",JSON(jmes="cve.vendors[*].product",output="product", expand=True))分裂事件 - SPLIT
提供将一条日志分裂为多条的功能。
- 基于值进行分裂:
- 基于CSV的字符串:
("data", SPLIT) # data: "a,b,c"- 自定义分隔符与Quote:
("data", SPLIT(sep='#', quote='|') ) # data: "a#b#|c#d|"- 基于JSON数组分裂:
("data", SPLIT) # data: ["a", "b", "c"]- 设置输出:
- 默认覆盖原字段, 可设置:
("data", SPLIT(output="sub_data"))- 使用JMES提取后的再分裂:
- 选择:
("data", SPLIT(jmes="cve.vendors[*].product"))- 计算:
("data", SPLIT(jmes="join(`,`, cve.vendors[*].name",output="vendors"))- 计算:
("data", SPLIT(jmes="max(words[*].score)",output="hot_word"))- 提取后的字段可以是数组或者字符串
进一步资料
相关链接
- 日志服务SLS命令行工具(CLI)
- 依赖的模块Python SDK
- Github上的ETL的配置代码案例
- 扫码加入官方钉钉群 (11775223):