在DataWorks中实现指定资源被指定账户访问
背景
之前写过一篇文章是关于“DataWorks和MaxCompute内部权限体系的区别”有兴趣的朋友可以点击阅读查看详情。但是还是有些同学会问,我如何在DataWorks中实现我的具体某个Resource,Table还是UDF只能被我指定的用户所使用的权限管控。这个UDF可能涉及到数据的加解密算法,属于数据安全管控范围了。
常见方案
- package方案,通过打包授权进行权限精细化管控。
- DataWorks上新建角色(管理>MaxCompute高级配置>自定义用户角色)来进行高级管控。
- Role policy方案,通过role policy来自定义role的权限集合。
可选方案
(1)package方案,通过打包授权进行权限精细化管控。
package基本知识,通常是为了解决跨项目空间的共享数据及资源的用户授权问题。当通过package后会发现给予其DataWorks开发者角色后用户拥有了所有权限。不可控。
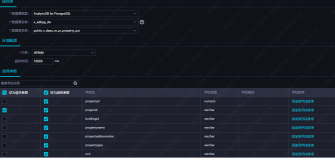
- 首先,普及大家熟知的DataWorks开发者角色的权限如下:

从权限配置上看明显不符合我们的要求,明显看出来其对project中的package、functions、resources和table默认有全部权限。A projects/sz_mc/packages/*: *A projects/sz_mc/registration/functions/*: *A projects/sz_mc/resources/*: *A projects/sz_mc/tables/*: *
- 其次,通过DataWorks添加了子账号并赋予了开发者角色,具体如下:

上述的普及应该让大家明白,通过打package和DataWorks默认的角色都不能够满足我们的需求。比如我将子账号RAM$yangyi.pt@aliyun-test.com:ramtest并给予开发者角色,那么他就默认拥有这个当前项目里所有Object的所有action权限,具体详见。
(2)DataWorks上新建角色(管理>MaxCompute高级配置>自定义用户角色)来进行高级管控。但是在DataWorks-MaxCompute高级配置中只能针对某个表/某个项目进行授权,不能对resource和udf进行授权。
(3)role policy方案,通过policy可以精细化的管理到具体用户针对具体资源的具体权限粒度,可以满足我们的场景需求。但是policy机制的官方文档一直没有公开,主要考虑到用户是否熟悉policy否则使用起来会造成一定的困扰和问题,耽误开发效率。
Role policy方案
为了安全起见,建议初学者找个测试项目来验证policy。以下操作都是通过MaxCompute console完成,具体详见:console配置。
① 创建默认拒绝访问UDF角色
step1:创建一个role denyudfrole,如下:odps@ sz_mc>create role denyudfrole;
step2:创建policy授权文件,如下:
{
"Version": "1", "Statement":
[{
"Effect":"Deny",
"Action":["odps:Read","odps:List"],
"Resource":"acs:odps:*:projects/sz_mc/resources/getaddr.jar"
},
{
"Effect":"Deny",
"Action":["odps:Read","odps:List"],
"Resource":"acs:odps:*:projects/sz_mc/registration/functions/getregion"
}
] }step3:设置和查看role policy。如下:odps@ sz_mc>put policy /Users/yangyi/Desktop/role_policy.json on role denyudfrole;
step4:添加用户至role denyudfrole。odps@ sz_mc>grant denyudfrole to RAM$yangyi.pt@aliyun-test.com:ramtest;
至此我们验证下,以子账号RAM$yangyi.pt@aliyun-test.com:ramtest登录MaxCompute console。
1、登录console确认角色。
2、show grants查看当前登录用户权限。
可以看出来,该RAM子账号有两个角色,一个是role_project_dev其实就是DataWorks默认的开发者角色,一个是我们刚自定义创建的denyudfrole。
3、验证自建UDF以及依赖的包的权限。

验证成功,该子账号在拥有了DataWorks开发者角色的前提下并没有自建UDF:getregion的读权限。但是离我们期望只能指定某个用户来访问该UDF还差最后一步。需要结合project policy来解决此需求。
配置project policy
step1:编写policy。
{
"Version": "1", "Statement":
[{
"Effect":"Allow",
"Principal":"RAM$yangyi.pt@aliyun-test.com:yangyitest",
"Action":["odps:Read","odps:List","odps:Select"],
"Resource":"acs:odps:*:projects/sz_mc/resources/getaddr.jar"
},
{
"Effect":"Allow",
"Principal":"RAM$yangyi.pt@aliyun-test.com:yangyitest",
"Action":["odps:Read","odps:List","odps:Select"],
"Resource":"acs:odps:*:projects/sz_mc/registration/functions/getregion"
}] }step2:设置和查看policy。odps@ sz_mc>put policy /Users/yangyi/Desktop/project_policy.json;

验证下:
跑一个SQL看看:
查看依赖的包:
--->到此为止,我们完成了需求。指定项目下只有指定的RAM子账号能够访问指定的UDF和依赖的包。
总结
有些同学到这里可能清晰的认识了DataWorks和MaxCompute的安全体系,但是有些同学可能还比较晕。总结如下:
- 不想其访问具体资源的,在DataWorks中添加数据开发者权限后再在MaxCompute console上按照role policy配置为拒绝访问权限。
- 指定账户访问资源的,在DataWorks配置数据数据开发者权限后再再MaxCompute console上按照project policy配置为允许访问权限。
- 具体实例详见上述,可以满足我们的精细化管理需求。