
前言
Netflix(美国最大的PGC视频内容商)在18年下半年陆续发了几篇文章来讲述他们内部的NMDB系统的设计和实现,NMDB的全称是Netflix Media Database,用于解决Netflix内部视频结构化数据的统一存储和分析问题。NMDB是完全由其内部业务需求驱动而孵化出来的,Netflix内部有足够多的数据和最复杂的场景。所以NMDB是一个在视频结构化数据处理这个垂直领域内被大量数据和复杂场景锤炼过的一个产品,值得有相同场景需求的公司借鉴一下。
Netflix共发布了三篇文章来讲述NMDB,第一篇讲述NMDB的起源、解决的问题以及设计目标,第二篇讲述NMDB的数据模型,第三篇讲述NMDB的架构实现,而本文是对这三篇内容的一个综合解读。本人非视频分析和数据处理这个垂直领域的专家,不过拥有类似场景结构化数据存储的经验,如果有一些表述错误的地方,欢迎指正和交流。
附上原文链接:
- 《The Netflix Media Database》
- 《Netflix Media Database — the Media Timeline Data Model》
- 《Implementing the Netflix Media Database》
NMDB的起源
Netflix是全美最大的PGC视频内容提供商,其商业成功的核心是内容和产品,产品的核心是用户体验,而驱动其产品用户体验提升的关键是数据和算法。Netflix拥有庞大的视频内容数据和用户数据,如何利用这些数据通过算法来驱动用户体验提升,是Netflix产品和技术上的最大挑战。
友好的用户界面、精准的个性化推荐、流畅的播放流以及丰富的分类目录是Netflix用户体验最关键的几个组成部分,需要各种各样复杂的工作流结合在一起才能实现这种体验。源源不断越来越庞大的新的内容的产生和输入,促使Netflix去思考如何开发一个系统,能够帮助创意团队高效的对这些新内容进行处理,及时合成高质量的数字资产。
通过对不同业务、需求和工作流的抽象,Netflix萌生了构建一个基础平台的想法。这个基础平台提供统一的算法、计算工作流以及结构化元数据存储,让不同业务方能够共享算法和元数据,避免重复的计算来提升数据质量和提高工作效率。其中很重要的一个组件就是元数据存储,它是一个统一的存储平台,用于存储视频数据经过算法处理分析后产生的结构化元数据,持久化的同时提供高效索引,满足不同维度灵活快捷的查询和分析需求,这个统一的元数据库就是NMDB。
为了更好的理解这一产品存在的意义,文中给了几个实际应用场景的例子。
场景一:个性化推荐
上图是各大视频网站中常见的页面,内容推荐系统如何根据用户的喜好进行精准的个性化推荐,是提升访问量、用户留存和DAU的关键。个性化推荐系统以机器学习为核心,以媒体文件(视频、音频和字幕)和元数据(分配标签、概要)为输入。
场景二:视频和音频编码优化
高效的视频和音频编码能够大大提升媒体文件的压缩率,是保证更高质量流媒体流畅度的关键。对视频内容时间和空间维度的分析,例如监测场景变化、识别视频帧中的突出差异部分,这类数据是编码系统非常关键的输入。
场景三:源内容的质量审核

上图是一个典型的乌龙例子,画面中出现了一个不该出现的物体。这类问题目前是可以通过技术手段探测和解决的,算法能自动识别并标记特殊物体的位置。
以上是Netflix优化用户体验的几个典型场景,虽然看上去不相关的几个场景,但其实其底层依赖的数据和核心算法,是有很多重叠的。例如探测视频的『shot-change』,可以应用在视频编码优化,也可应用在视频剪辑。再例如视频文字识别,可应用于上述场景三,也可应用于电影海报挑选(自动规避包含文字的截图)。
综上,Netflix内部拥有非常多的业务场景,底层依赖相同的数据和核心算法,需要抽象这么一个底层产品:
- 提供统一的数据存储。
- 避免对同一份数据的重复的计算分析(视频分析的计算是非常非常昂贵的),统一存储分析结果。
- 统一的模型,抽象并通用。
这个底层产品就是NMDB - Netflix Media Database。
NMDB的设计目标
NMDB用于存储多媒体元数据(deeply technical metadata),并支持近实时(near real-time)查询和分析。设计目标主要包括:
- 为结构化数据服务(Affinity to structured data):可定义结构化数据的schema,对数据进行存储和索引,灵活支持查询、搜索和分析等不同需求。
- 时间线模型(Efficient media timeline modeling):支持对媒体的Timeline类数据进行建模,例如视频截帧、字幕等拥有时间线属性的数据。
- 时间和空间查询(Spatio-temporal query-ability):支持时间(截帧、字幕等数据)和空间(视频截帧部分区域数据)维度的查询。
- 多租户(Multi-tenancy)
- 高可扩展(Scalability)
NMDB就是Netflix底层多媒体数据的通用存储,可支持对数据的任意时间和空间维度的查询和分析,为Netflix内部不同的应用系统提供核心数据服务。
NMDB数据模型
NMDB提出的数据模型称之为『Media Document』,这是一个灵活的通用的数据模型,它的首要设计目标是能兼容不同类型Media数据对数据建模的需求,希望能通过同一套规范定义的数据模型来表达,并且具备灵活的可扩展性,来适应未来更多场景的建模需求。例如当前需要对视频、音频、字幕等数据建模,包含静态和动态的,层次复杂的数据。
基本要素
这套模型的设计关键点在于抽象,NMDB认为『Media Document』本质上就是用于描述Media的时间线数据,外加额外的空间属性。所以基于此理解,它提出了『Media Document』的三个基本要素:时间模型(Timing Model)、空间模型(Spatial Model)和嵌套结构(Nested Structure)。前面两个点是对核心数据类型的抽象,第三点是对复杂组织结构的一个抽象,下面我们来分别看下这三个点分别代表什么。
Timing Model
『Media Document』要建模的第一类数据是时间线数据,对这类数据的表示它提出了『Timed events』的概念。 『Timed events』即带有时间属性的事件,可以用来表示周期性连续的事件,也可用来表示零散的事件。例如连续的视频帧就是连续的事件,而视频中的『shot change』就是零散的事件,直接来看一个直观的例子就能理解清楚。


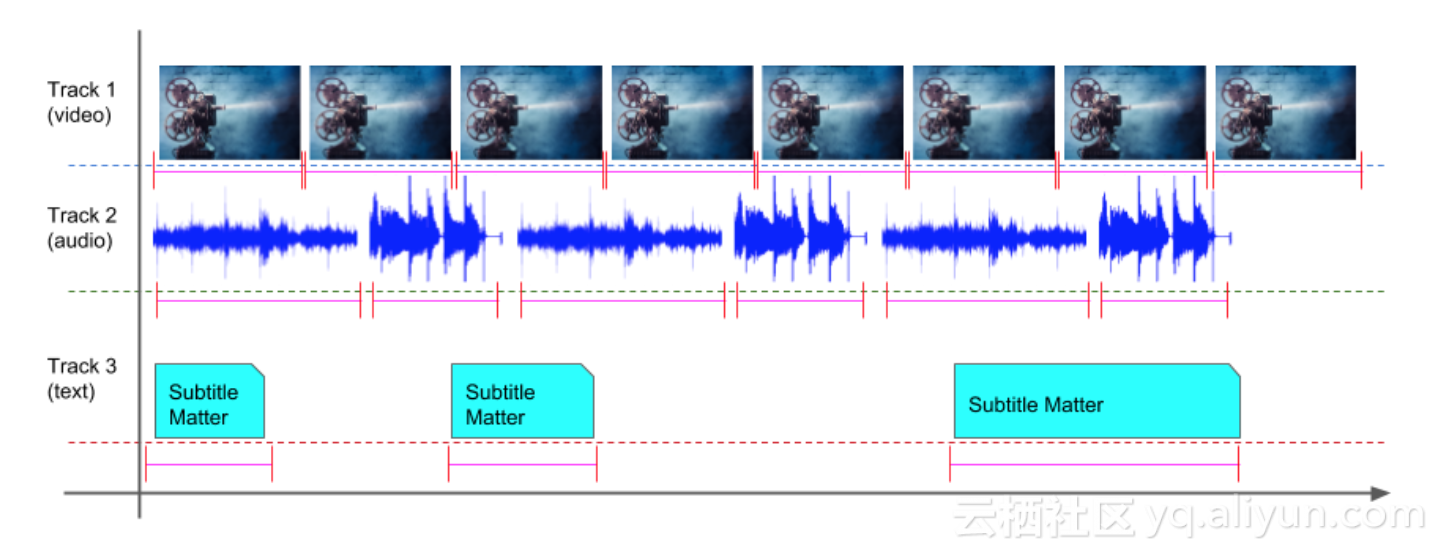
上图就是对字幕数据的一个表示,每段字幕为不同的事件,每个事件中包含覆盖的时间区域。『Media Document』对事件间的关系不做任何假设和约束,每个事件覆盖的时间区域可以是连续的、跳跃的或者是重叠的。定义了使用startTime和endTime来表示时间区域,使用metadata来表示事件内容,具备足够的灵活性。
Spatial Model
空间维度是基于时间维度的另一层次扩展,我们直接看一个例子。


Nested Structure
『Timing Model』和『Spatial Model』用于描述Media Document中的一系列事件,例如某一视频帧、某段字幕或者某个特征物体等。事件串起来构成事件流,Media中允许存在多类事件流,例如音频事件流、视频截帧事件流或者字幕事件流等。『Nested Structure』定义了这些事件流是如何组织的,Media Document定义了两层的嵌套结构,分别为『track』和『component』,来看下一些示例:
上述例子中视频、音频和字幕,分别由不同的track来表示,每个track内有一个component,component下就是时间和空间模型表示的事件流数据。
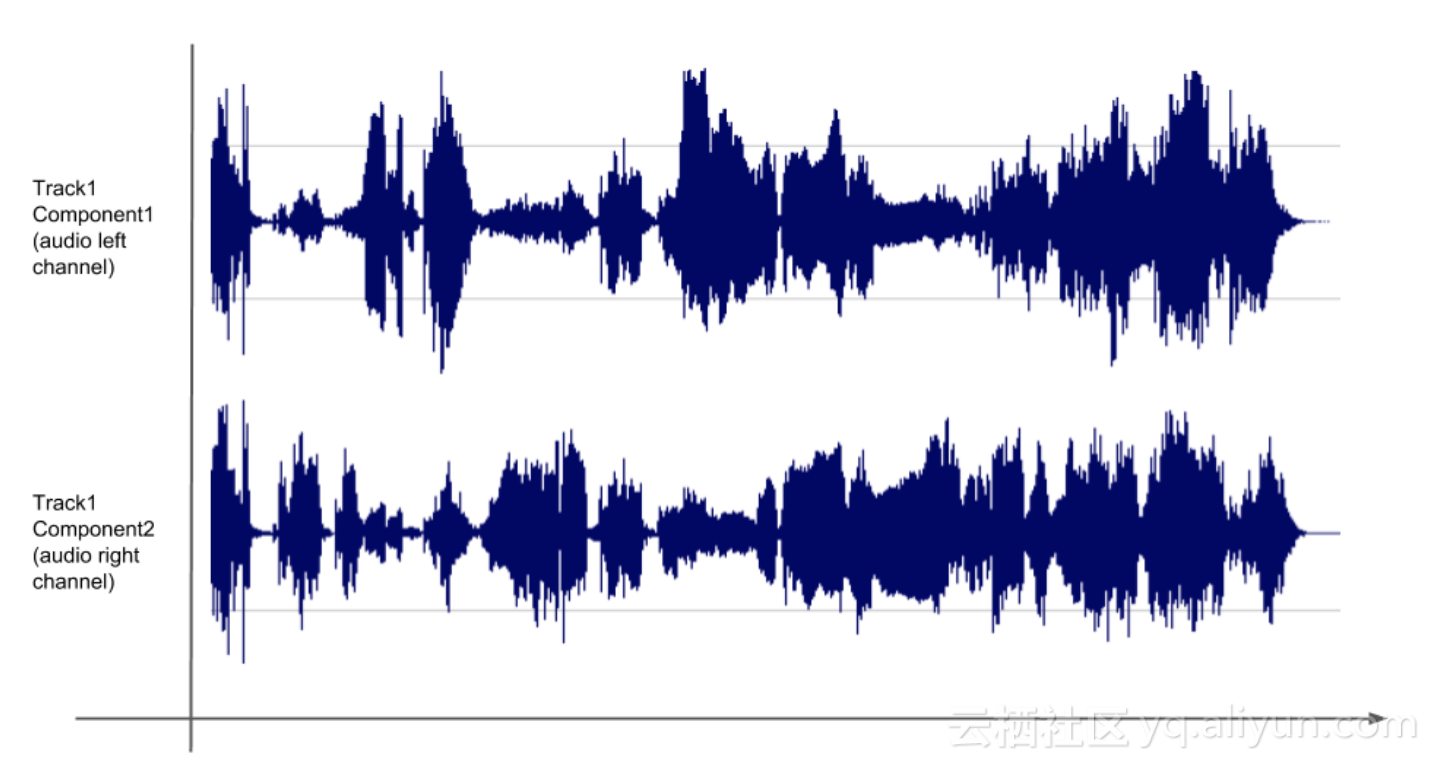
上述例子中双声道音频,用同一个track但是不同的component来分别记录左声道和右声道的记录。
不过『Media Document』对把哪类数据定义为『track』或『component』并没有限制,例如记录双声道的音频,可以有两种组织形式:
- 和上述例子相同,使用一个track代表音频,用两个component分别代表左声道和右声道。
- 分两个不同的track,一个是左声道,另一个是右声道。
Media Document
模型定义
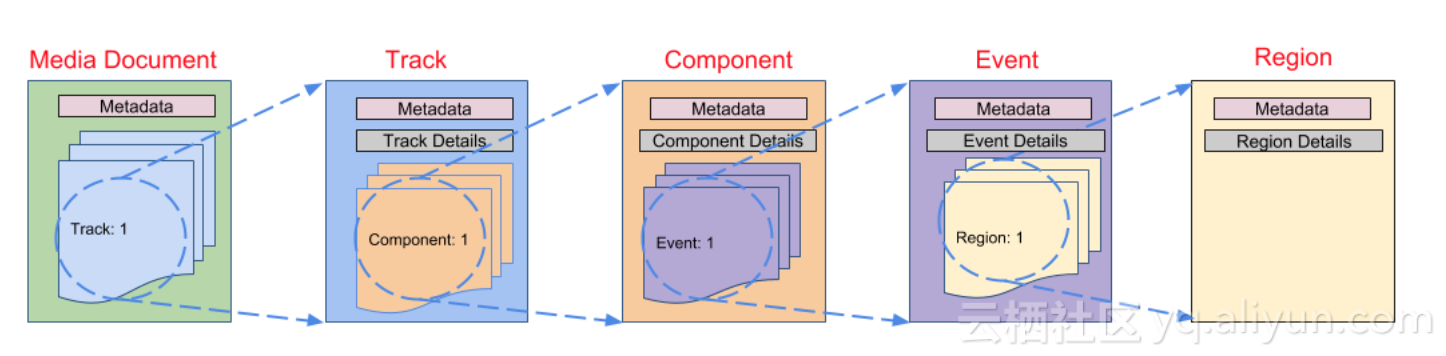
来看下『Media Document』的完整组成部分和各部分的组成关系:
- 一个Document由一个或多个Track组成
- 一个Track由一个或多个Component组成
- 一个Component由一个或多个Timed events组成
- 一个Event内可以包含零个或多个Region
另外还有一些强制性的约束:
- 每个Track和Component必须包含一个id属性,来做唯一标识。
- Component层必须包含一些静态信息,包括:时间精度(帧率)和空间精度(分辨率)。
- Event层必须包含时间属性:startTime和endTime。
- Region层面必须包含空间熟悉。
- 每一层都可以有metadata属性,用于存储自定义的元数据
NMDB选择用Json作为『Media Document』的表现格式,一个原因是已有一些开源的文档索引系统例如MongoDB和Elasticsearch,天然支持Json格式。一个完整的Json例子如下:

Document Schema
从上面关于『Media Document』的模型描述可以看到,NMDB提出了一些对这个模型的结构和约束的定义,就好比关系数据库对关系模型的的行、列、主键索引等的定义。关系数据库在创建表时需要定义Table Schema,NMDB也是一样,需要定义Document Schema。
Document Schema是一个嵌套的文档结构,它描述了具体字段的类型,例如可以明确哪个Event是字幕、某个字段的具体类型等,方便查询以及强类型校验。NMDB底层索引系统采用了Elasticsearch,索引的Schema也需要给定字段的明确的索引类型,例如对字幕数据需要指定全文索引,对空间数据需要指定空间索引等,依赖于Document Schema的定义。
NMDB支持Document Schema的动态更改,但是只允许增加optional字段,来同时保证向下和向上兼容。
最后
想了解NMDB的架构设计和实现,请看下一篇。
