In-Memory Compaction 是 HBase2.0 中的重要特性之一,通过在内存中引入 LSM 结构,减少多余数据,实现降低 flush 频率和减小写放大的效果。本文根据 HBase2.0 中相关代码以及社区的讨论、博客,介绍 In-Memory Compaction 的使用和实现原理。
1. 原理
1.1 概念和数据结构
In-Memory Compaction 中引入了 MemStore 的一个新的实现 类 CompactingMemStore 。顾名思义,这个类和默认 memst。 CompactingMemStore 中,数据以 segment 作为单位进行组织,一个 memStore 中包含多个 segment。数据写入时首先进入一个被称为 active 的 segment,这个 segment 是可修改的。当 active 满之后,会被移动到 pipeline 中,这个过程称 为 in-memory flush 。pipeline 中包含多个 segment,其中的数据不可修改。 CompactingMemStore 会在后台将 pipeline 中的多个 segment 合并为一个更大、 更紧凑的 segment,这就是 compaction 的过程。
如果 RegionServer 需要把 memstore 的数据 flush 到磁盘,会首先选择其他类型 的 memstore,然后再选择 CompactingMemStore。这是因为 CompactingMemStore 对内存的管理更有效率,所以延长 CompactingMemStore 的生命周期可以减少总的 I/O。当 CompactingMemStore 被 flush 到磁盘时, pipeline 中的所有 segment 会被移到一个 snapshot 中进行合并然后写入 HFile。

在默认的 MemStore 中,对 cell 的索引使用 ConcurrentSkipListMap,这种结构支持动态修改,但是其中存在大量小对象,内存浪费比较严重。而在 CompactingMemStore 中,由于 pipeline 里面的数据是只读的,就可以使用更紧凑的数据结构来存储索引,减少内存使用。代码中使用 CellArrayMap 结构来存 储 cell 索引,其内部实现是一个数组。

1.2 Compaction 策略
当一个 active segment 被 flush 到 pipeline 中之后,后台会触发一个任务对 pipeline 中的数据进行合并。合并任务会对 pipeline 中所有 segment 进行 scan,将他们 的索引合并为一个。有三种合并策略可供选择:Basic,Eager,Adaptive。
Basic compaction 策略和 Eager compaction 策略的区别在于如何处理 cell 数据。 Basic compaction 不会清理多余的数据版本,这样就不需要对 cell 的内存进行拷 贝。而 Eager compaction 会过滤重复的数据,并清理多余的版本,这意味着会 有额外的开销:例如如果使用了 MSLAB 存储 cell 数据,就需要把经过清理之后 的 cell 从旧的 MSLAB 拷贝到新的 MSLAB。basic 适用于所有写入模式,eager 则 主要针对数据大量淘汰的场景:例如消息队列、购物车等。
Adaptive 策略则是根据数据的重复情况来决定是否使用 Eager 策略。在 Adaptive 策略中,首先会对待合并的 segment 进行评估,方法是在已经统计过不重复 key 个数的 segment 中,找出 cell 个数最多的一个,然后用这个 segment 的 numUniqueKeys / getCellsCount 得到一个比例,如果比例小于设定的阈值,则使 用 Eager 策略,否则使用 Basic 策略。
2. 使用
2.1 配置
2.0 中,默认的 In-Memory Compaction 策略为 basic。可以通过修改 hbase- site.xml 修改:
<property>
<name>hbase.hregion.compacting.memstore.type</name>
<value><none|basic|eager|adaptive></value>
</property>
也可以单独设置某个列族的级别:
create ‘<tablename>’,
{NAME => ‘<cfname>’, IN_MEMORY_COMPACTION =>
‘<NONE|BASIC|EAGER|ADAPTIVE>’}
2.2 性能提升
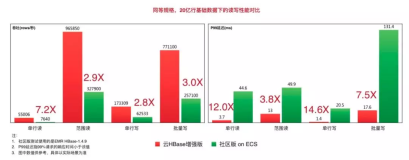
社区的博客中给出了两个不同场景的测试结果。使用 YCSB 测试工具,100-200 GB 数据集。分别在 key 热度符合 Zipf 分布和平均分布两种情况下,测试了只有写操作情况下写放大、吞吐、GC 相比默认 Memstore 的变化,以及读写各占 50% 情况下尾部读延时的变化。测试结果如下表:

作者:陆豪 阿里巴巴 技术专家