背景
性能诊断是软件工程师在日常工作中需要经常面对和解决的问题,在用户体验至上的今天,解决好应用的性能问题能带来非常大的收益。Java 作为最流行的编程语言之一,其应用性能诊断一直受到业界广泛关注。可能造成 Java 应用出现性能问题的因素非常多,例如线程控制、磁盘读写、数据库访问、网络I/O、垃圾收集等。想要定位这些问题,一款优秀的性能诊断工具必不可少。本文将介绍 Java 性能诊断过程中的常用工具,并重点介绍其中的优秀代表 JProfiler 的基本原理和最佳实践(本文所作的调研基于jprofiler10.1.4)。
Java 性能诊断工具简介
在 Java 的世界里,有许多诊断工具可供选择,既包括像 jmap、jstat 这样的简单命令行工具,又包括 JVisualvm、JProfiler 等图形化综合诊断工具,同时还有 SkyWalking、ARMS 这样的针对分布式应用的性能监控系统。下面分别对其进行介绍。
简单命令行工具
JDK 内置了许多命令行工具,它们可用来获取目标 JVM 不同方面、不同层次的信息。
- jinfo - 用于实时查看和调整目标 JVM 的各项参数。
- jstack - 用于获取目标 Java 进程内的线程堆栈信息,可用来检测死锁、定位死循环等。
- jmap - 用于获取目标 Java 进程的内存相关信息,包括 Java 堆各区域的使用情况、堆中对象的统计信息、类加载信息等。
- jstat - 一款轻量级多功能监控工具,可用于获取目标 Java 进程的类加载、JIT 编译、垃圾收集、内存使用等信息。
- jcmd - 相比 jstat 功能更为全面的工具,可用于获取目标 Java 进程的性能统计、JFR、内存使用、垃圾收集、线程堆栈、JVM 运行时间等信息。
图形化综合诊断工具
使用上述命令行工具或组合能帮您获取目标 Java 应用性能相关的基础信息,但它们存在下列局限:
- 无法获取方法级别的分析数据,如方法间的调用关系、各方法的调用次数和调用时间等(这对定位应用性能瓶颈至关重要)。
- 要求用户登录到目标 Java 应用所在的宿主机上,使用起来不是很方便。
- 分析数据通过终端输出,结果展示不够直观。
下面介绍几款图形化的综合性能诊断工具。
JVisualvm
JVisualvm 是 JDK 内置的可视化性能诊断工具,它通过 JMX、jstatd、Attach API 等方式获取目标 JVM 的分析数据,包括 CPU 使用率、内存使用量、线程堆栈信息等。此外,它还能直观地展示 Java 堆中各对象的数量和大小、各 Java 方法的调用次数和执行时间等。
JProfiler
JProfiler 是由 ej-technologies 公司开发的一款 Java 应用性能诊断工具。它聚焦于四个重要主题上。
- 方法调用 - 对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法。
- 内存分配 - 通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄漏问题,优化内存使用。
- 线程和锁 - JProfiler 提供多种针对线程和锁的分析视图助您发现多线程问题。
- 高级子系统 - 许多性能问题都发生在更高的语义级别上。例如,对于JDBC调用,您可能希望找出执行最慢的 SQL 语句。JProfiler 支持对这些子系统进行集成分析。
分布式应用性能诊断
如果只需要诊断单机 Java 应用的性能瓶颈,上面介绍的诊断工具就已经够用了。但随着现代系统架构逐渐从单体转变为分布式、微服务,单纯使用上述工具往往无法满足需求,这时就需要借助 Jaeger、ARMS、SkyWalking 这些分布式追踪系统提供的全链路追踪功能。分布式追踪系统种类繁多,但实现原理都大同小异,它们通过代码埋点的方式记录 tracing 信息,通过 SDK 或 agent 将记录的数据传输至中央处理系统,最后提供 query 接口对结果进行展示和分析,想了解更多分布式追踪系统的原理可参考文章开放分布式追踪(OpenTracing)入门与 Jaeger 实现。
JProfiler 简介
核心组件
JProfiler 包含用于采集目标 JVM 分析数据的 JProfiler agent、用于可视化分析数据的 JProfiler UI、提供各种功能的命令行工具,它们之间的关系如下图所示。
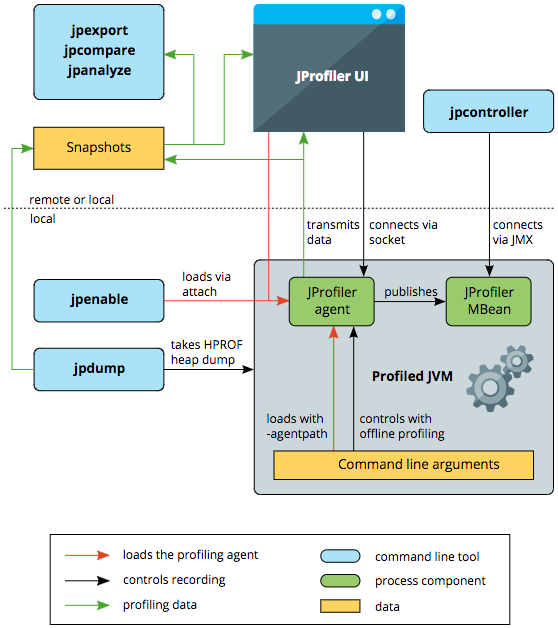
JProfiler agent
JProfiler agent 是一个本地库,它可以在 JVM 启动时通过参数-agentpath:<path to native library>进行加载或者在程序运行时通过 JVM Attach 机制进行加载。Agent 被成功加载后,会设置 JVMTI 环境,监听虚拟机产生的事件,如类加载、线程创建等。例如,当它监听到类加载事件后,会给这些类注入用于执行度量操作的字节码。
JProfiler UI
JProfiler UI 是一个可独立部署的组件,它通过 socket 和 agent 建立连接。这意味着不论目标 JVM 运行在本地还是远端,JProfiler UI 和 agent 间的通信机制都是一样的。
JProfiler UI 的主要功能是展示通过 agent 采集上来的分析数据,此外还可以通过它控制 agent 的采集行为,将快照保存至磁盘,展示保存的快照。
命令行工具
JProfiler 提供了一系列命令行工具以实现不同的功能。
- jpcontroller - 用于控制 agent 的采集行为。它通过 agent 注册的 JProfiler MBean 向 agent 传递命令。
- jpenable - 用于将 agent 加载到一个正在运行的 JVM 上。
- jpdump - 用于获取正在运行的 JVM 的堆快照。
- jpexport & jpcompare - 用于从保存的快照中提取数据并创建 HTML 报告。
安装配置
JProfiler 同时支持诊断本地和远程 Java 应用的性能。如果您需要实时采集并展示远程 JVM 的分析数据,需要完成以步骤:
- 在本地安装 JProfiler UI。
- 在远程宿主机上安装 JProfiler agent 并让其被目标 JVM 加载。
- 配置 UI 到 agent 的连接。
具体步骤可参考文档 Installing JProfiler 和 Profiling A JVM。
最佳实践
本章将以高性能写 LogHub 类库 Aliyun LOG Java Producer 为原型,带您了解如何使用 JProfiler 剖析它的性能。如果您的应用或者您在使用 producer 的过程中遇到了性能问题,也可以用类似的方式定位问题根因。如果您还不了解 producer 的功能,建议先阅读文章日志上云利器 - Aliyun LOG Java Producer。本章使用的样例代码参见 SamplePerformance.java。
JProfiler 设置
数据采集模式
JProfier 提供两种数据采集模式 Sampling 和 Instrumentation。
- Sampling - 适合于不要求数据完全精确的场景。优点是对系统性能的影响较小,缺点是某些特性不支持(如方法级别的统计信息)。
- Instrumentation - 完整功能模式,统计信息也是精确的。缺点是如果需要分析的类比较多,对应用性能影响较大。为了降低影响,往往需要和 Filter 一起使用。
由于我们需要获取方法级别的统计信息,这里选择了 Instrumentation 模式。同时配置了 Filter,让 agent 只记录位于 Java 包com.aliyun.openservices.aliyun.log.producer下的类和类com.aliyun.openservices.log.Client的 CPU 分析数据。
应用启动模式
通过为 JProfiler agent 指定不同的参数可以控制应用的启动模式。
- 等待模式 - 只有在 Jprofiler GUI 和 agent 建立连接并完成分析配置设置后,应用才会真正启动。在这种模式下,您能够获取应用启动时期的分析数据。对应的命令为
-agentpath:<path to native library>=port=8849。 - 立即启动模式 - 应用会立即启动,Jprofiler GUI 会在需要时和 agent 建立连接并设置分析配置。这种模式相对灵活,但会丢失应用启动初期的分析数据。对应的命令为
-agentpath:<path to native library>=port=8849,nowait。 - 离线模式 - 通过触发器记录数据、保存快照供事后分析。对应的命令为
-agentpath:<path to native library>=offline,id=xxx,config=/config.xml。
因为是在测试环境,同时对应用启动初期的性能也比较关注,这里选择了默认的等待模式。
使用 JProfiler 诊断性能
在完成 JProfiler 的设置后,便可以对 Producer 的性能进行诊断。
Overview
在概览页我们可以清晰的看到内存使用量、垃圾收集活动、类加载数量、线程个数和状态、CPU 使用率等指标随时间变化的趋势。
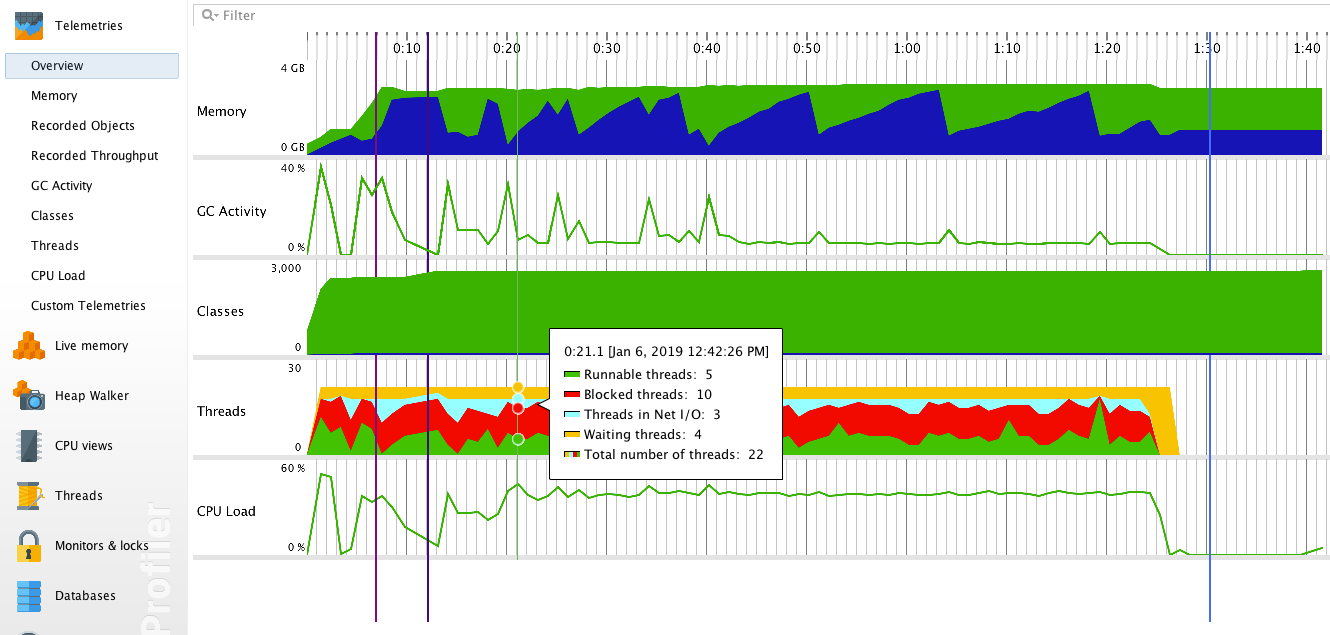
通过此图,我们可以作出如下基本判断:
- 程序在运行过程中会产生大量对象,但这些对象生命周期极短,大部分都能被垃圾收集器及时回收,不会造成内存无限增长。
- 加载类的数量在程序初始时增长较快,随后保持平稳,符合预期。
- 在程序运行过程中,有大量线程处于阻塞状态,需要重点关注。
- 在程序刚启动时,CPU 使用率较高,需要进一步探究其原因。
CPU views
CPU views 下的各个子视图展示了应用中各方法的执行次数、执行时间、调用关系等信息,能帮我们定位对应用性能影响最大的方法。
Call Tree
Call tree 通过树形图清晰地展现了方法间的层次调用关系。同时,JProfiler 将子方法按照它们的执行总时间由大到小排序,这能让您快速定位关键方法。
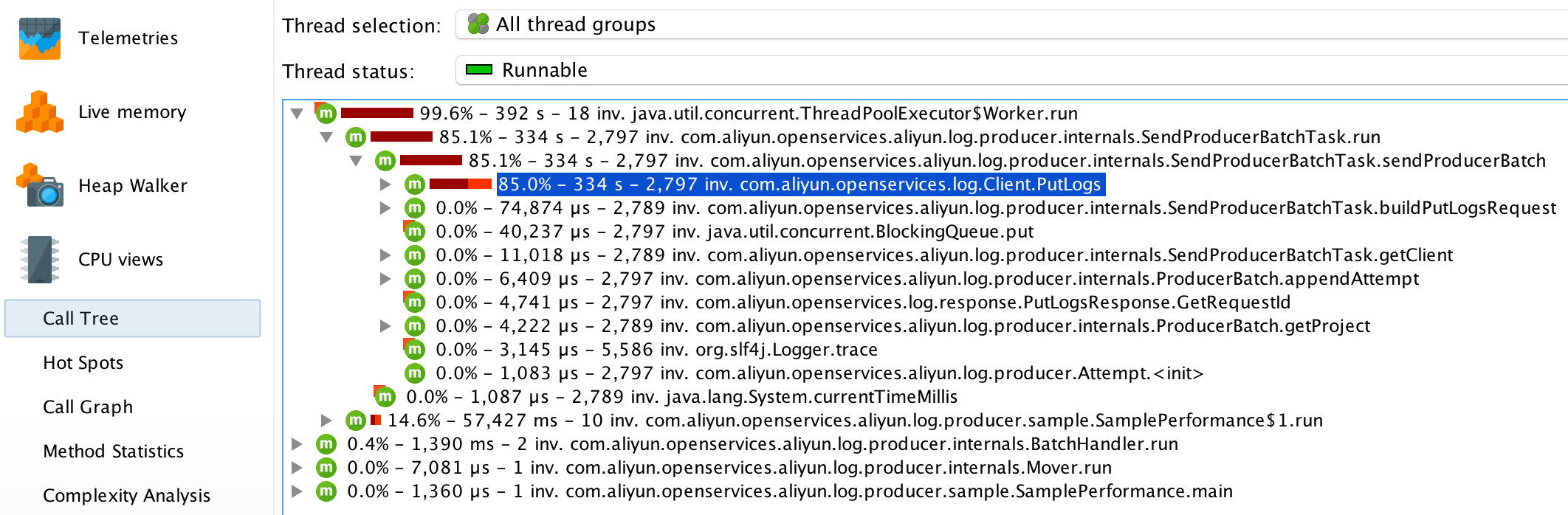
对于 Producer 而言,方法SendProducerBatchTask.run()耗时最多,继续向下查看会发现该方法的主要时间消耗在了执行方法Client.PutLogs()上。
Hot Spots
如果您的应用方法很多,且很多子方法的执行时间比较接近,使用 hot spots 视图往往能助您更快地定位问题。该视图能根据方法的单独执行时间、总执行时间、平均执行时间、调用次数等属性对它们排序。其中,单独执行时间等于该方法的总执行时间减去所有子方法的总执行时间。
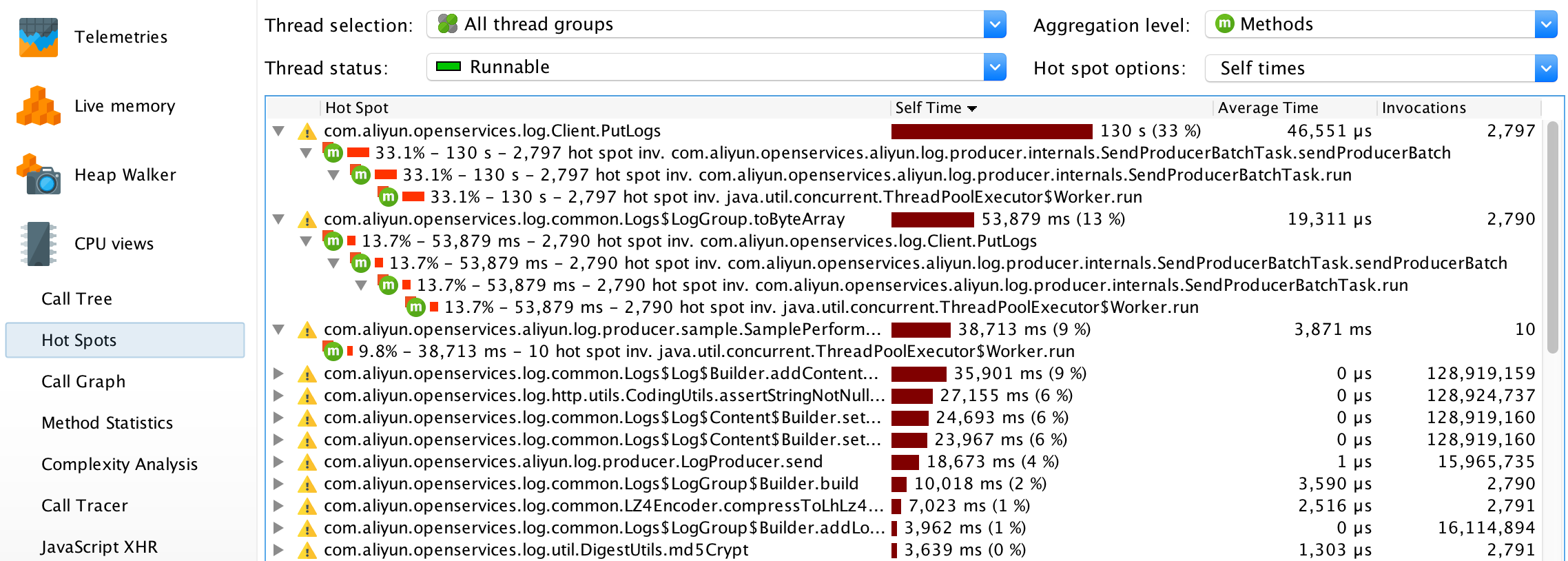
在该视图下,可以看到Client.PutLogs(),LogGroup.toByteArray(),SamplePerformance$1.run()是单独执行时间耗时最多的三个方法。
Call Graph
找到了关键方法后,call graph 视图能为您呈现与该方法直接关联的所有方法。这有助于我们对症下药,制定合适的性能优化策略。
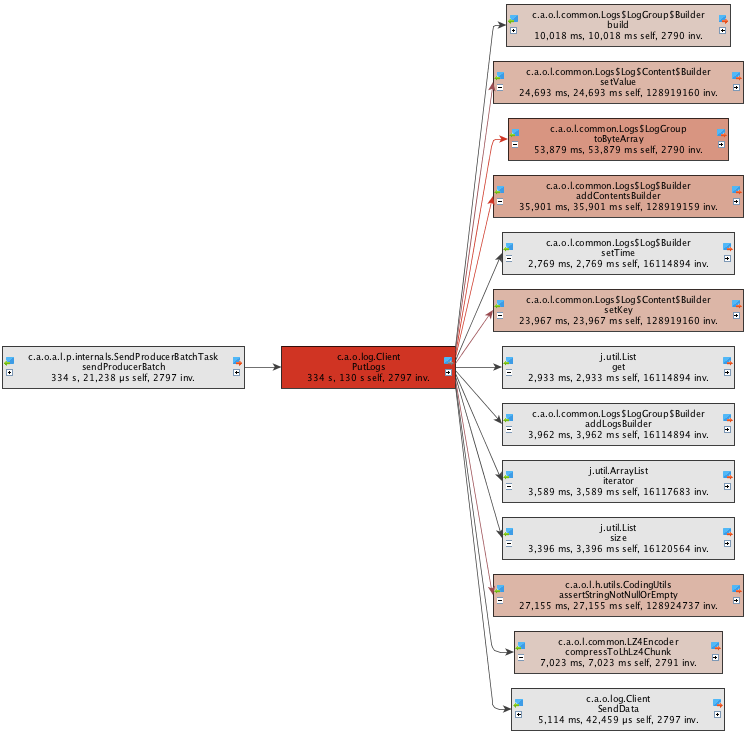
这里,我们观察到方法Client.PutLogs()执行的主要时间花费在了对象序列化上,因此性能优化的关键是提供执行效率更高的序列化方法。
Live memory
Live memory 下的各个子视图能让您掌握内存的具体分配和使用情况,助您判断是否存在内存泄漏问题。
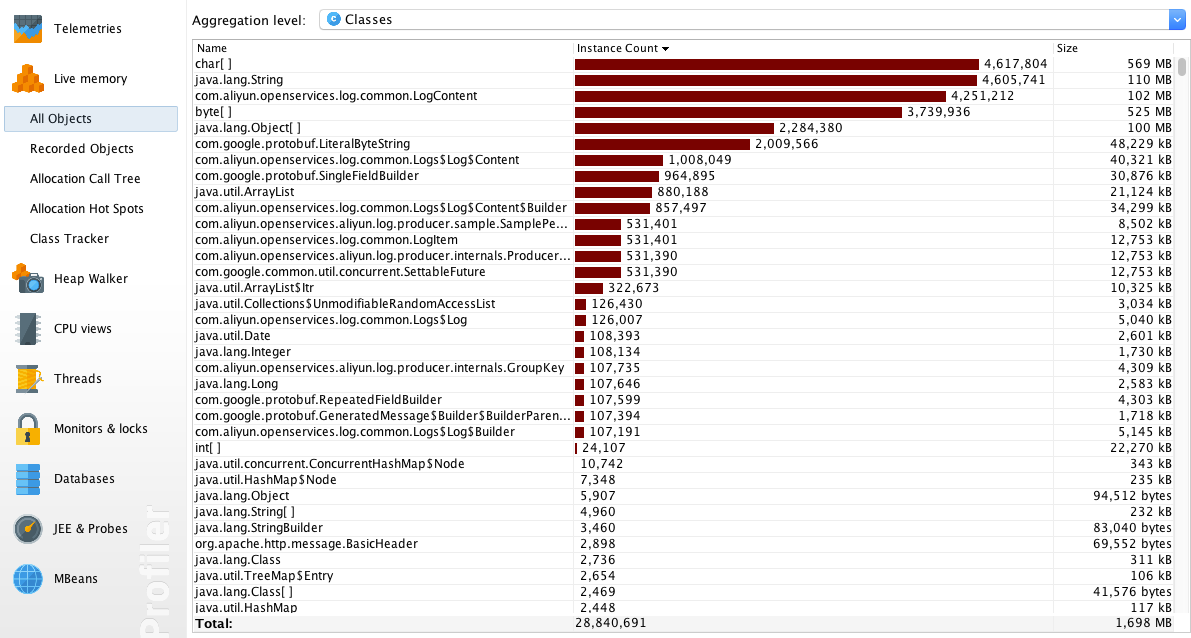
All Objects
All Objects 视图展示了当前堆中各种对象的数量和总大小。由图可知,程序在运行过程中构造出了大量 LogContent 对象。
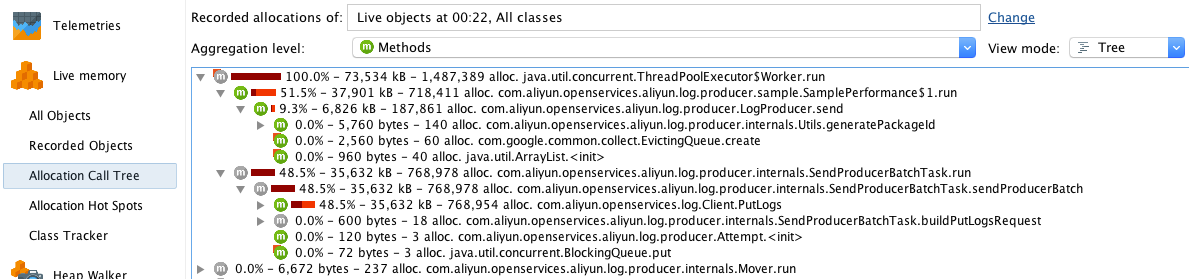
Allocation Call Tree
Allocation Call Tree 以树形图的形式展示了各方法分配的内存大小。可以看到,SamplePerformance$1.run()和SendProducerBatchTask.run()是内存分配大户。
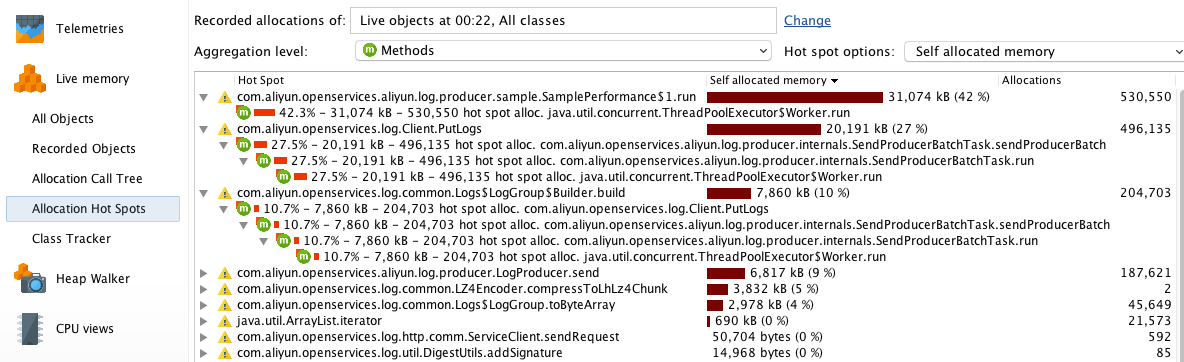
Allocation Hot Spots
如果方法比较多,您还可以通过 Allocation Hot Spots 视图快速找出分配对象最多的方法。
Thread History
线程历史记录视图直观地展示了各线程在不同时间点的状态。
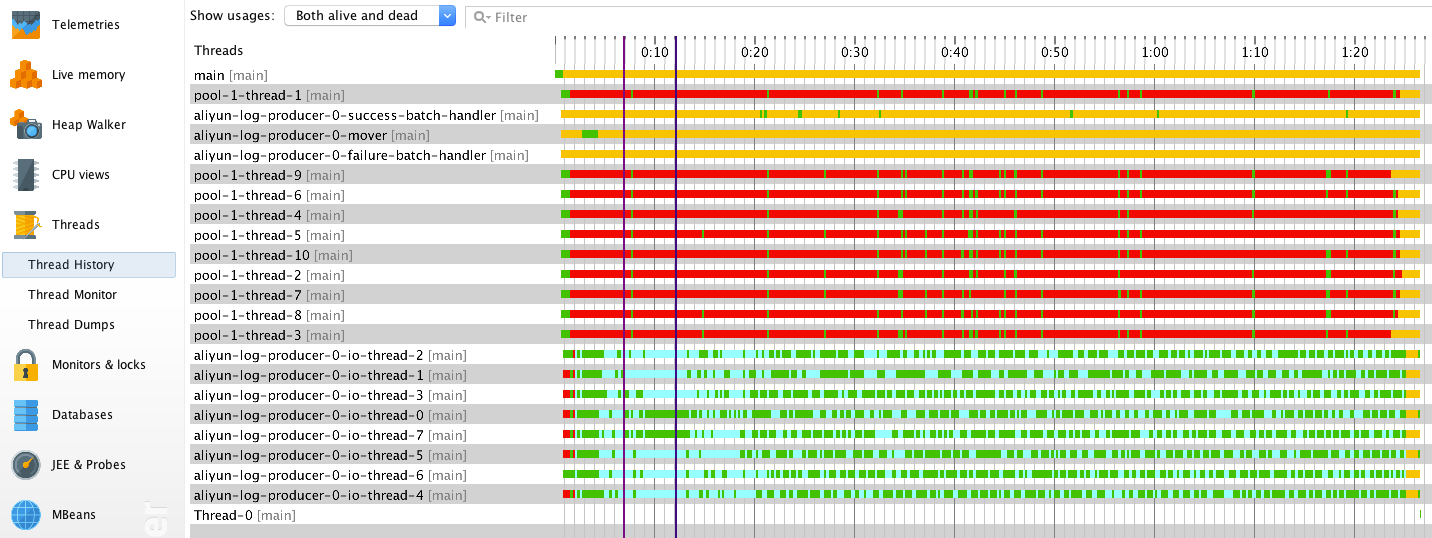
不同线程执行的任务不同,所展现的状态特征也不同。
- 线程
pool-1-thread-<M>会循环调用producer.send()方法异步发送数据,它们在程序刚启动时一直处于运行状态,但随后在大部分时间里处于阻塞状态。这是因为 producer 发送数据的速率低于数据的产生速率,且单个 producer 实例能缓存的数据大小有限。在程序运行初始,producer 有足够空间缓存待发送数据,所以pool-1-thread-<M>一直处于运行状态,这也就解释了为何程序在刚启动时 CPU 使用率较高。随着时间的推移,producer 的缓存被逐渐耗尽,pool-1-thread-<M>必须等到 producer “释放”出足够的空间才有机会继续运行,这也是为什么我们会观察到大量线程处于阻塞状态。 -
aliyun-log-producer-0-mover负责将超时 batch 投递到发送线程池中。由于发送速率较快,batch 会因缓存的数据达到了上限被pool-1-thread-<M>直接投递到发送线程池中,因此 mover 线程在大部分时间里都处于等待状态。 -
aliyun-log-producer-0-io-thread-<N>作为真正执行数据发送任务的线程有一部分时间花在了网络 I/O 状态。 -
aliyun-log-producer-0-success-batch-handler用于处理发送成功的 batch。由于回调函数比较简单,执行时间短,它在大部分时间里都处于等待状态。 -
aliyun-log-producer-0-failure-batch-handler用于处理发送失败的 batch。由于没有数据发送失败,它一直处于等待状态。
通过上述分析可知,这些线程的状态特征都是符合预期的。
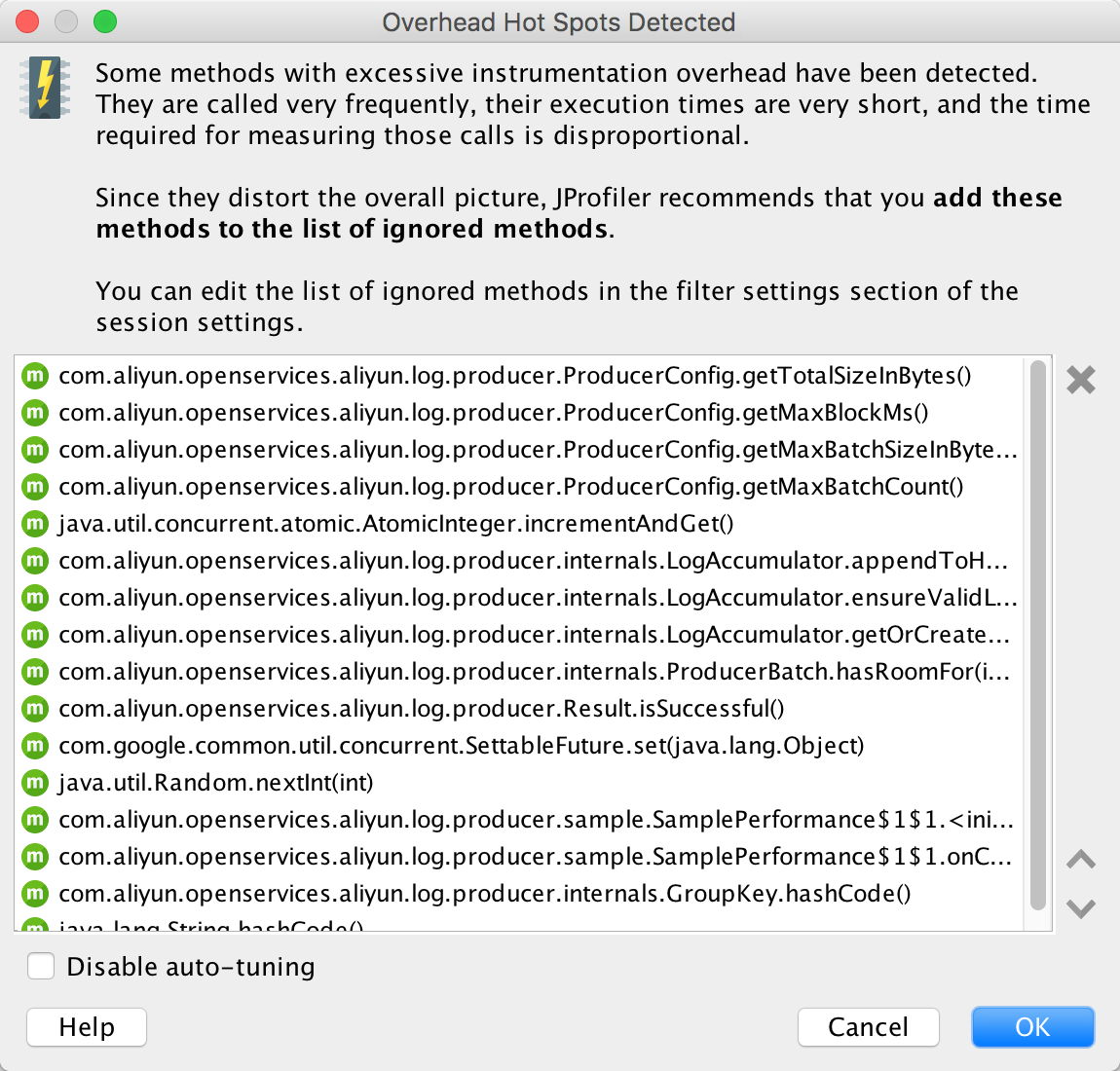
Overhead Hot Spots Detected
当程序运行结束后,JProfiler 会弹出一个对话框展示那些频繁被调用,但执行时间又很短的方法。在下次诊断时,您可以让 JProfiler agent 在分析过程中忽略掉这些方法以减轻对应用性能的影响。
小结
通过 JProfiler 的诊断可知应用不存在大的性能问题,也不存在内存泄漏。下一步的优化方向是提升对象的序列化效率。