闲鱼技术-临耕
背景
小区是租房业务中很重要的信息,它能够反映房源的位置和品质。对租客而言,能否浏览到准确的小区信息是高效找房的关键。因此,收集和展示准确的小区信息是提高用户找房效率的重要方面。为了获得全面的小区信息,租房业务通常会依赖多种数据源获得小区数据,这些数据格式不一,信息杂乱无章,含有很多冗余信息。为了提高找房效率,必须把同一个小区的不同数据聚合到一起并理清小区信息之间的从属关系。本文抓住小区的独有特征并利用相似度算法,设计了一种基于文本匹配的方法来解决这个问题。
目标
现有的小区数据中重复小区很多,比如“福鼎家园”、“福鼎家园晓风苑”、“福鼎家园2幢3单元”、“西溪北苑西区”和“西溪北苑东区”等等。这些小区名虽然不完全一样,但是其中一些表示的同一个小区或者同一小区的子小区,我们把这些小区名叫做同义小区,比如“福鼎家园”、“福鼎家园晓风苑”、“福鼎家园2幢3单元”。表示整个小区的是父小区,比如福鼎家园、西溪北苑。表示小区下面的部分区域的叫做子小区,比如福鼎家园晓风苑、西溪北苑东区。而像“福鼎家园2幢3单元”这样的小区地址,称为楼栋地址。
为了房源信息搜索和展示的准确与效率,我们需要把解析出每条小区数据对应的小区信息,以及小区的层级关系,甚至补充一些小区信息。具体来说,一是把现有小区统一到子小区:子小区是期、区、苑一级,比如‘福鼎家园晓风苑’,‘福鼎家园雨露苑’:1. 子小区是单元、栋、幢的上一级:像单元、栋、幢、xx号楼这样的名称,属于小区楼栋;2. 每个子小区都有唯一的父小区,比如子小区“福鼎家园晓风苑”的父小区是“福鼎家园”;二是能够补充父小区、子小区信息:对于小区库中不存在的父小区或者子小区信息,可以补充进来;
思路
小区作为一个独特的地址单位,有下面这些特征:
- 子小区的父小区通常是多个子小区的最长公共前缀:小区的命名是一个层级结构,同一个父小区的子小区通常具有相同的前缀,这符合人对于位置的命名习惯;
- 子小区和小区楼栋的名称有独特的特征:比如子小区大多符合这样的模式:“PP[ww|xx|yy|zz]区”,“PP[ww|xx|yy]期”,“PP[ww|xx|yy]号”以及“PP[ww|xx|yy]座”等等。其中PP是公共前缀,也就是确定的虚拟父小区名,ww表示数字,xx表示代表数字的汉字,yy表示大写或者小写字母,zz表示方位词(比如东、西、南、北、东北、西北等)。而小区楼栋地址通常是下面的形式:“PP[ww|xx|yy]幢”,“PP[ww|xx|yy]楼”,“PP[ww|xx|yy]栋”,“PP[ww|xx|yy]单元”以及“PP[ww|xx|yy]号楼”等等
(PP是子小区名,ww,xx和yy代表的含义与上面一样); - 小区作为一个相对小的地址单位,范围是较小的,而且同一个小区的不同子小区的距离不可能太远;
- 同一个小区的不同子小区名称通常非常相似。
基于上述观察,我们提出一种以前缀匹配和文本相似度为基础的小区归一化方案。基本的想法是
- 使用前缀匹配算法对小区实施初步聚类,
- 然后通过计算文本相似度附加距离权重做进一步筛选,
- 最后识别父子小区识别。
数据预处理
我们按照市、区、小区名和经纬度信息确定一个小区。所有小区数据存储在一个表plot里:小区id、市、区、小区名称、小区gps、来源source(标记出小区的来源),类型type(0表示父小区,1表示虚拟父小区,2表示子小区,3表示楼栋地址),父小区id。我们需要对原始的小区数据做预处理:
- 需要对原始数据做数据处理:市区的格式,整理成类似:杭州,余杭区;有些小区gps是非高德gps,需要转换为高德gps
- 有些小区数据只有省市街道小区名,没有具体的区域和经纬度信息,需要使用地图提示进行校正,尽量补全区域和经纬度信息
- 小区名里还会夹杂很多标点符号,干扰我们的分析,我们会首先清除掉这些标点,只对中文字符进行匹配分析
归一化算法
小区信息归一化流程如下图所示:
主要的思路是先利用前缀匹配算法匹配小区得到近似小区树,然后在同一个近似小区树里面筛选掉不适合的小区,然后在小区树之间根据相似度算法匹配,接着合并同义小区树,得到最终的归一化小区树,在每一棵小区树中可以使用模式匹配识别父子小区。下面重点介绍前四步。
前缀匹配聚集小区
前面提到同一个父小区的大多数子小区都拥有相同的前缀。我们以这个作为切入点来识别近似的小区,具体方法如下:
对于同一城市同一区域里的每一个小区,开始搜索所有以其名称的前两个字开头的所有小区,这些小区拥有公共前缀,称为以该小区为根的近似小区树。找到所有的近似小区树,不断增加前缀的长度,近似小区树不断分裂成更小的树,在合适的时候停止前缀长度的增加,最后得到的每个小区树里面的小区都是近似小区,可以提取出父小区和子小区。但是如何确定前缀长度的最大值呢?分下面几种情况:
- 如果是能够判断出本小区的名称是子小区或者楼栋的,直接抽取出父小区名,如果没有同名的父小区则新建一个父小区名,然后搜索所有以该父小区名为前缀的小区,构成一棵以父小区为根的近似小区树;判断一个小区名代表的是不是子小区或者小区楼栋的方法是通过前文阐释的小区名进行正则匹配完成。
- 如果存在其他小区以本小区为前缀,那么认为本小区是一个父小区,并且把以本小区为前缀的所有小区都聚集在一起。下图展示了1、2两种情况的例子,其中蓝色是父小区,红色是楼栋地址,黄色是子小区:

- 对于其他的小区,那么前缀长度的确定有以下原则:以该长度为前缀的小区不超过20(除去重复的小区,以及市、区和小区名完全一样的小区)。一般来说一个小区的子小区不会太多,一个父小区的子小区数量超过20个是非常少见的。举例来说,如下图,小区“翡翠城木兰苑”无法被识别为子小区或者楼栋地址,依靠前缀得到了它的近似小区树,树的数量小于20,停止前缀增长。

对于每一个小区都做这样一个操作,就会得到每个小区对应的前缀树,也称为小区树(使用前缀树实现),这个小区称为小区树的根。容易知道一个小区可能在多个小区树中。在这个过程中也能够识别一部分小区楼栋、子小区和父小区。
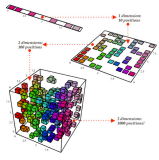
本质上讲,这一步是文本聚类的过程。如下图所示,文本聚类通常对文本分词,然后使用TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文本频率)统计出词频、设置词语权重,构建VSM(Vector Space Model,向量空间模型), 为每个文本构建等长向量,最后设置度量标准(欧氏距离、余弦相似度等),使用聚类算法对文本聚类。
这种方法不太适合我们的场景:1. 这种方法通常是针对具有多个特征词的文档进行聚类,然而小区名称短,很难提取出有效的特征词;2. 小区名称有一个特征比较明显,即父子小区以及楼栋号的名称按照顺序是有层级关系的,然而这个特征却不能在文本向量化聚类算法中体现并利用;3. 常用的聚类算法如K-Means等选择合适的k值需要技巧和摸索,而我们的方法利用子小区数量不会太多这一点规避了这个问题。
非同义小区过滤
上一步中得到的是拥有相同前缀的小区树。依靠前缀,我们圈选的小区是比较多的,很多不属于同一个父小区的小区被圈选到同一棵小区树中了。一般来说,一个小区的不同子小区之间的距离不会太远。因此,我们过滤掉地理位置较远的小区。具体来讲就是,如果近似小区树里面小区A和小区树的根小区的距离大于2km,那么把这个小区从小区树中删除。
近似小区再聚集
并不是所有的同义小区都有相同的后缀。所以,我们也通过文本相似度,来补充一些被遗漏的同义小区:
计算近似树前缀的编辑距离和gps距离,对于gps距离小于1km,而且相似度大于2的近似树可以合并为一棵同义小区树,其中相似度的计算如下:
其中a和b分别是两棵小区树的根小区的名称,max(a,b)是a和b的长度最大值,LevenshteinDistance(a, b)是编辑距离,similarity(a, b)越大表示a和b越相似。

如上图所示,“西溪风情”不是“大华西溪风情”的前缀,所以在第一步的前缀匹配聚集中,没有被加入到“大华西溪风情”的近似小区树。针对这种前缀覆盖不到的情况,我们计算“西溪风情”和“大华西溪风情”的相似度为3,这个相似度表示文本总长度是文本差异的倍数,越大说明相对差别越小。当这个相似度大于2时,我们把两棵相似树合并。
归一化
在以每个小区为根,聚集得到相应的小区树之后,小区树之间会有很多重叠。这一步把有交集的小区树合并得到最终的小区归一化结果。合并后的小区树中的小区可以认为是同义的小区,这一步可以说是最终的小区归一化。
评估
使用高德地图中准确区分了同义小区的数据以及人工识别,衡量小区归一化算法的准确度。主要从两个方面:
- 正误识(false positives): 本来归于父小区的子小区,未能被识别出来;
- 负误识(false negatives): 不归某一父小区的子小区,却被误识为这个父小区的子小区;
数据显示本文介绍的算法正误识比率低于8%,负误识比率低于5%,说明这种归一化方法的准确度有一定保证。
总结
本文通过观察小区名称和层级关系的规律,提出了一种使用文本匹配和近似度分析解决小区信息归一化问题的方法。方法实现简单,有较高的准确度,能够快速识别近似的小区,为提高房源搜索的效率和房源发布的准确度提供了基础数据保障。