有时我们的数据里充满了各种简写或标记,而在处理、展示数据的过程中,我们需要的是数据各字段的详细名称,因此就需要对我们的数据集进行清洗与处理。前些天遇到一个某图书馆借阅数据,给出的要求是统计借阅图书的类别,数据里有每次借阅书籍的中图分类号,如"A122",'A'表示马列毛邓,'A1'表示马克思恩格斯著作,'A12'表示单行著作,'A122'表示1848~1863年间。每一本书都有一个独立的分类号,按照需求只需要对分类号的第一个字母,也即分类号一级索引进行统计,并将统计结果里的字母用中文替换。因此这是一个入门级别的小任务,用Python就可以轻易的实现。
一、文件导入
1.1 源文件
源文件是一个80万行的Excel(囧),索引号在某一列下,我需要处理的数据大概有四万行。将其导入至sourceData.csv文件,便于读取,数据格式如下图。

1.2 分类号-中文映射文件
在百度上查询得到各分类号与中文名称之间的对应关系,存放在'中图分类法.txt'文件中。

1.3 源代码
-
with open('中图分类法.txt', 'r',encoding='GBK', errors='ignore') as f:
-
bookFile = f.readlines()
-
# print(bookFile)
-
-
with open('sourceData.csv', 'r',encoding='GBK', errors='ignore') as f:
-
dataFile = f.readlines()
-
# print(dataFile)
二、词频统计
2.1 提取一级索引号
我们按行读取的数据形如"I267/121",而我们只需要最开始的字母,因此提取每行第一个元素即可。统计词频我们可以声明一个字典变量,将每一个一级索引作为一个key,如果字典里有该key,则值+1,否则创建key.
-
newdict = {}
-
for line in dataFile:
-
# print(line[0])
-
if line[0] in newdict:
-
newdict[line[0]] += 1
-
else:
-
newdict[line[0]] = 1
2.2 字典排序
为了后面能直观地看出各类别图书借阅数量的异同,我们在此将该字典按照值的大小降序排列。在此需要用上sorted(dic,value,reverse)函数。由于sorted函数并不改变原字典,所以需要接受该函数的返回值——排列后的列表。
-
sortedDict = sorted(newdict.items(),key = lambda x:x[1],reverse = True)
三、映射关系的替换
3.1 分类号数据字典化
由于分类号及其对应关系的数据为一行以逗号','隔开的文本,所以需要将其转换成字典。该数据行形如'A,马列毛邓',结尾还有一个换行符,为了将其变为字典,就需要在剔除换行符的情况下以逗号将其分隔为两个字符串。
-
dict = {}
-
for line in bookFile:
-
#print(line.strip().split(','))
-
dict[line.strip().split(',')[0]] = line.strip().split(',')[1]
-
print(dict)
3.2 字符与文本的映射
所以我们现在有两个变量,一个是存储了分类号与其对应中文的字典:{'A': '马列毛邓', 'B': '哲学宗教'...},一个是排序好的列表,列表元素为索引号及出现次数。我们现在需要将索引号替换为字典中对应索引号的值,将结果用两个变量表示(方便后面画图)。
-
attr = []
-
v1 = []
-
-
for class2 in sortedDict:
-
# print(class2[0]+str(class2[1]))
-
if class2[0] in dict:
-
attr.append(dict[class2[0]])
-
v1.append(class2[1])
-
-
print(attr)
-
print(v1)
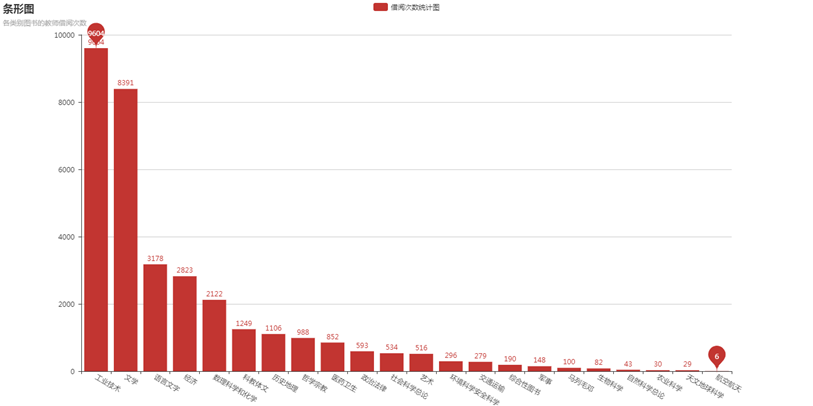
结果如下(部分):
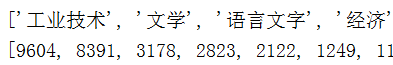
四、数据可视化
这里我用到了第三方库pyecharts,这个库是一个生成Echarts图表的python类库,功能强大,图表也美观。利用该库画图除了可参考官方文档之外,还可参考这篇——各种图表的详细代码。
-
bar = Bar("条形图","各类别图书的教师借阅次数",width=1400, height=700)
-
bar.add("借阅次数统计图",attr,v1,mark_point=["min", "max"],is_label_show=True,xaxis_interval=0,xaxis_rotate=-30,is_more_utils=True)
-
bar.render()
第二、三个参数为坐标轴的值。运行后在源码所在目录生成一个网页,里面就是动态的可视化图表。