- 之前有一篇文章已经大概的说了一下HBase的基本的概念和内部的一些构成的意思,比如表啊,列族啊之类的,这一篇再简单的说一下HBase的架构
数据模型从大到小
-
namespace表空间:类似RDBMS中的库概念,当你想把一组表去统一的管理的时候可以使用得到,这种抽象为即将推出的多租户相关功能奠定了基础
- 配额管理:限制命名空间可以使用的资源量(即区域,表)。
- 命名空间安全管理:为租户提供另一级别的安全管理。
- 区域服务器组:可以将命名空间/表固定到RegionServers的子集上,从而保证粗略的隔离级别
- table表:就是有一个或者多个列族组成,加上之前的代码使用,这个表概念应该很熟了
- row行:一个行包括了多个列,这些列通过列族来分类
- column family列族:列族是多个列的集合,HBase会尽量的将一个列族的列放入同一个服务器内,这样可以提高存取性能,并且可以批量管理有关联的一堆列,所有的数据属性都是定义在列族上的.
- column qualifier列:多个列组成一行
- cell:一个列中可以存储多个版本的数据,每个版本就成为一个单元格cell
- timestamp:标识cell的版本号的,按递减顺序存储,因此从存储文件读取时,首先找到最新值

- rowkey的排序规则:每一个行都有一个类似主键的rowkey,而这个 rowkey在HBase中是严格按照字典排序,即row11>row2
- HBase不支持表关联
- HBase部分支持ACID
-
表空间增加属性和删除属性操作
#添加,修改一个属性 hbase> alter_namespace 'ns1', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'} #删除一个属性 hbase> alter_namespace 'ns1', {METHOD => 'unset', NAME=>'PROPERTY_NAME'} - 表命名空间的作用:主要是对表进行分组,满足可以分库的需求就像RDBMS一样
-
HBase保留的表空间
- HBase:系统表空间,用于HBase内部表
- default:默认没有定义命名空间的用户创建的表都存放在default中,即你不指定表空间的表都在这个下面
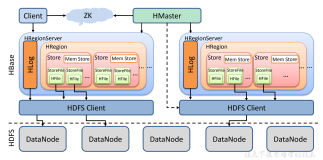
宏观架构

- 上面是HBase的宏观的架构图,一个HBase可以由一个Master多个RegionServer组成,右下角的是RegionServer的内部构造图
-
以上每个部分是做什么的呢?
- Master:负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,比如Region的分割,在HBase中Master并不是像Hadoop的namenode那么重要,因为数据的读取和写入和Master没什么关系,如果Master挂掉了,集群是可以正常的进行数据的操作的,但是对于建表和修改列族之类的定义操作就不行了
- RegionServer:RegionServer上有一个或者多个Region,数据就存放在Region上,如果他是基于HDFS的,那么所有的数据存储操作都是依靠HDFS的接口来实现的
- Region:表的部分数据,因为表可以拆分成多个Region,HBase是一个自动分片的数据库.一个Region就相当于关系数据库中分区表的一个分区
- HDFS:hadoop的组成部分,用于数据的存储和备份,HBase与HDFS交互,HDFS才是存储数据的载体
- zookeeper:之前介绍过他的重要性,因为缺了zookeeper你就不能够读取数据了,因为你读取数据所需要的元数据表,也就是HBase的保留空间中的HBase:meta是存储在Zookeeper上的
RegionSever内部
- Region server负责数据的读写
- 每一个Region server都在ZooKeeper中创建相应的ephemeral node.HMaster通过监控这些ephemeral node的状态来发现正常工作的或发生故障下线的Region server
- 如果Region server不能成功向ZooKeeper发送心跳信息,则其与ZooKeeper的连接超时之后与之相应的ephemeral node就会被删除

- 一个WAL:预写日志:WAL->Write-Ahead Log,当操作到达Region的时候,HBase先将操作作写入WAL里面,HBase再将数据放入基于内存实现的MemStore中,等数据到达一定量的时候,刷写道HFile中,如果在这个过程中出现意外(宕机),那么数据就丢失了,WAL是一个保险机制,数据在写到MemStore之前,先被写到WAL了,这样当出现故障的时候可以从WAL中恢复数据
- 多个Region:就是表拆分出来的Region,Region相当于表的一个数据分片,每一个Region都有start row 和end row代表其存储范围,所有这些信息将随着文件保存在region中,也会保存在hbase:meta中,通过这张表能够跟踪所有的region信息,当他们变得太大,region可以分裂,如果需要,还可以合并
- 出于本地化的考虑,RegionServer应该与Hadoop的DataNode存在一个节点上
Region内部
- HBase中的表是根据row key的值水平分割成所谓的region的,集群中负责管理Region的结点就是Region server

- 多个Store:每一个Region都包含多个Store,一个Store对应一个列族的数据,如果一个表有两个列族,那么在一个Region中就会有两个Store
Srore内部

- 一个store对应一个列族,一个store对象由一个memstore和零个或多个HFile组成,store是存储所有写入表中的信息的实体,并且当数据需要从表中读取时也会被用到
- MemStore:每个Store中有一个MemStore,数据写入WAL之后就会被放入MemStore,MemStore是内存的存储对象,只有当它满了之后才会被flush到HFile中
- HFile:一个Store中有很多HFile,当MemStore满了之后HBase就会在HDFS上生成一个新的HFile,然后把MemStore中的内容写到这个HFile中,HFile直接与HDFS打交道,HFile是数据的存储实体
-
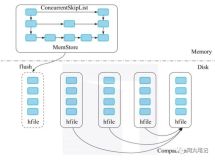
如上图可以看到:WAL先存入HDFS再后加载到内存,然后在刷写到HFile中,HFile还是存在HDFS上,数据为什么已经存放了一次,还要放入MemStore
- 学过Hadoop的知道,他是不支持随机插入数据的,只能是创建追加删除,不能修改.对HBase等一系列数据库产品来说,按顺序的存放数据是非常重要的,这是性能的保证,所以我们不能按照数据到来的顺序写入磁盘,MemStore就是干这个的,将数据放入MemStore先进行整理,然后再一起写入到硬盘.虽然MemStore是存储在内存中,HFile和WAL存在HDFS上,但由于数据在写入MemStore之前要先被写入WAL,所以增加MemStore并不能加快写入速度,MemStore存在是为了维护数据按照rowkey顺序排列,而不是做缓存
MemStore内部
- 数据被写入WAL之后就会被加载到MemStore中去,MemStore的大小超过一定阀值就会被flush到HDFS上,以HFile的形式持久化起来
-
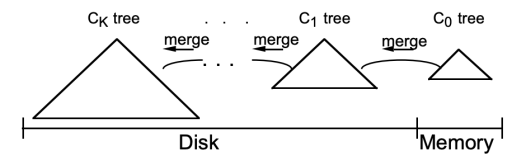
设计MemStore的原因
- 由于HDFS上的文件不可修改,为了让数据顺序存储从而提高读取效率,HBase使用了LSM树结构存储数据,数据会在MemStore中整理成LSM树,然后在刷写到HFile中,读取的时候有个专门的缓存叫做BlockCache,如果BlockCache开启了,就是先读BlockCache,读不到才读HFile和MemStore
- 优化数据的存储,如果你添加一个数据后马上删除了,这样就没必要刷到HFile中
- 由于HDFS不能修改数据,只能顺序追加,而HBase是一个随机读写的数据库,MemStore会在数据最终书写到HDFS上之前对文件进行排序处理,这样随机写入的数据就变成了顺序存储的数据,可以提高读取效率
- MemStore是实现LSM树存储的必须设计组件.在LSM树的实现方式中,有一个必经的步骤,就是在数据存储之前先对数据进行排序.而LSM树也是保证HBase能稳定地提供高性能的读能力的基本算法.LSM 树是Google BigTable和HBase的基本存储算法,它是传统关系型数据库 的B+树的改进.算法的关注重心是“如何在频繁的数据改动下保持系统 读取速度的稳定性”,算法的核心在于尽量保证数据是顺序存储到磁盘 上的,并且会有频率地对数据进行整理,确保其顺序性.而顺序性就可 以最大程度保证数据的读取性能稳定.
- 每一次的刷写都会产生一个全新的HFile文件,由于HDFS的特性,所以这个文件不可修改
HFile内部

- HFile是数据存储的实际载 体,我们创建的所有表,列等数据都存储在HFile里面,上面已经说过,当MemStore中积累足够多的数据的时候就会将其中的数据整个写入到HDFS中的一个新的HFile中.因为MemStore中的数据已经按照键排好序,所以这是一个顺序写的过程.由于顺序写操作避免了磁盘大量寻址的过程,所以这一操作非常高效
- 上图看出来HFile是由一个个块(Block)组成的,在HBase中一个块的默认大小为64KB,由列族上的BLOCAKSIZE定义的
- Data:数据块,每个HFile有多个Data,这个就是存放数据用的,Data是可选的,但是几乎没有HFile不包含Data的
- Meta:元数据块:Meta是可选的,Meta块只有在文件关闭的时候才会写入.Meta块存储了该HFile文件的元数据信息
- FileInfo:文件信息,其实也是一种数据存储块,FileInfo是HFile的必要组成部分,是必选的,它只有在文件关闭的时候写入,存储的是这个文件的信息,比如最后的key,key的平均长度等
- DataIndex:存储Data块索引信息的块文件,索引信息其实也是Data块的偏移量,DataIndex也是可选的,有Data才有DataIndex
- MetaIndex:存储Meta块索引信息的块文件,MetaIndex块也是可选的,有Meta才有MetaIndex
- Trailer:必选的,它存储了FileInfo,DataIndex,MetaIndex块的偏移量
Block
- HFile由block组成,这些block和HDFS的block不一样,一个HDFS的block可以有包含很多HFile block,HFile block一般在8KB到1MB之间,默认为64KB.如果一个表配置了压缩,HBase依旧会产生64KB大小的Block,然后压缩block,根据数据的大小以及压缩的格式,压缩后的block存储在磁盘大小也不一样大,大的block将会创建较少的数据索引,这有助于顺序表访问,而小一点的block将创建更多的索引值,这有助于随机访问
- 如果block size配置的很小,就会产生很多block索引,这样会给内存带来很大的压力,将会取得与预期相反的效果,同时,由于压缩的数据很小,压缩效率也低,将会出现数据容量增大的情况
Data内部

- Data数据块的第一位存储的是块的类型,后面存储的是多个 KeyValue键值对,也就是单元格(Cell)的实现类.Cell是一个接口, KeyValue是它的实现类
-
BlockType块类型
DATA 一个数据块将包括压缩了或未被压缩的数据,但不是两者的组合,数据块包含删除和插入标记 ENCODED_DATA LEAF_INDEX BLOOM_CHUNK 这些数据块是用来存储数据块索引相关信息的,当查询指定key,使用这个块索引来跳过文件解析 META INTERMEDIATE_INDEX ROOT_INDEX FILE_INFO 当查询指定的行时,HBase将会使用索引块来快速跳转到相应的HFile地址 GENERAL_BLOOM_META DELETE_FAMILY_BLOOM_META TRAILER INDEX_V1 包含了文件的其他可变大小的部分的偏移量,它也包含HFile版本信息 - 数据块采用逆序存储,这就意味着,数据块也按照逆序写入,而不是先在文件开头加入索引后将其他数据写入,先存储数据块然后存储数据块索引,Trailer数据块存储在最后
- 对于上面的块类型,自己感觉没必要弄懂,之后学习完总结的时候再来看
- 如果你感兴趣,可以访问 HBase Guide,搜索
block type即可
KeyValue内部

- 这是单元格最重要的实现类KeyValue类的结构,是最小的不可分割的数据结构
- 一个KeyValue类里面最后一个部分是存储数据的Value,而前面的 部分都是存储跟该单元格相关的元数据信息.如果你存储的value很 小,那么这个单元格的绝大部分空间就都是rowkey、column等元数据,所以列族和列的名字如果很长,大部分的空 间就都被拿来存储这些数据了.
- 不过如果采用适当的压缩算法就可以极大地节省存储列族,列等信 息的空间了,所以在实际的使用中,可以通过指定压缩算法来压缩这些 元数据,不过压缩和解压必然带来性能损耗,所以使用压缩也需要根据实际情况来取舍.如果你的数据主要是归档数据,不太要求读写性能, 那么压缩算法就比较适合你.
-
key type代表的不同的HBase操作
- put
- delete
- deletefamilyversion
- deletecolumn
- deletefamily
增删查改的真正面目
- 之前一直有说到HDFS的实现特性决定了HFile基本是不可以执行修改操作的,那么HBase是怎么实现增删改查的?
-
HBase几乎总是在做新增操作
- 当增加一个单元格的时候,HBase在HDFS上增加一条数据
- 当修改一个单元格的时候,HBase在HDFS上增加一条数据,只是版本号比之前的大
- 当你删除一个单元格的时候,HBae又在HDFS上增加了一条数据,只是这条数据没有value,类型为DELETE,这条数据叫做墓碑标记(Tombstone)
-
真正删除发生在什么时候
- 由于数据库在使用过程中积累了很多增删改查操作,数据的连续性和顺序性必然会被破坏,所以为了提升性能,HBase每间隔一段时间都会进行一次合并(Compaction),合并的对象为HFile文件,在进行合并的时候,他会将多个HFile合并成一个HFile,在这个过程中,只要有DELETE标记的在合并的过程中就会被排除,这时候才是真正的删除了
数据写入

- 数据发出后第一时间写入WAL,由于WAL也是存放在HDFS上的所以说cell已经持久化好了,但是WAL只是一个暂存的日志,他是不区分Store的,这些数据是不能被直接读取和使用的
- 数据之后加载到MemStore中整理:它会按照LSM树结构来存放数据
- HFile:直到MemStore认为太大了,或者到了刷写间隔,HBase就会把这个MemStore的内容刷写到HDFS系统上,称为一个存储在硬盘上的HFile文件,到这就算是真的持久化好了
数据读取
- 首先读取BlockCache,如果找不到了再去MemStore和HFile中查找数据
-
删除标记和数据不在一个地方
- 删除标记是标记数据是否删除的,如果删除标记不和数据在一起,那读取数据的时候怎么知道这个数据要删除呢?如果这个数据比删除标记更早的被读到,这时候是不知道这个数据是否被删除了,只有当扫描器接着往下读到删除标记,才知道这个数据是被删除了,是不需要返回给客户端的,所以HBase的SCan操作在取到所需要的所有行键对应的信息之后还会继续扫描下去,直到被扫描的数据大于给定的限定条件为止,这样他才能直到哪些数据应该被返回给用户,所以Scan增加过滤条件效率会明显增加
- 在Scan扫描的时候Store会创建StoreScanner实例,这个实例会把MemStore和HFile结合起来扫描,当StoreScanner打开的时候会先定位到起始行键上,然后开始往下扫描

- 红色部分就是制定的范围数据,Scan要将所有符合条件的StoreScanner扫描一遍后再返回数据
Region的定位

- 如上Client先去Zookeeper查询HBase的Meta表在那个RegionServer上(ZooKeeper中会保存META table的位置),因为HBase:meta记录了所有Region的行键范围信息即保存集群region的地址信息,通过这个表就可以查询出来要存取的rowkey是属于哪个Region的范围里面,以及这个Region又是属于哪个RegionServer,哪台RegionServer上有hbase:meta表的信息存储在Zookeeper的/hbase/meta-region-server节点
- 客户端连接含有HBase:meta表的RegionServer,查询出需要的信息,比如哪个Region的rowkey范围有自己需要的rowkey数据
- 获取信息后,客户端直连找到的RegionServer服务器,并对其进行操作
- 客户端会把meta信息缓存起来,下次操作就不需要进行以上步骤了
- 在未来的读写操作中,客户会根据缓存寻找相应的Region server地址。除非该Region server不再可达。这时客户会重新访问META table并更新缓存
关于WAL
- WAL是设计来解决宕机之后的操作恢复问题的,数据到达region的时候先写入WAL,然后在被加载到MemStore,就算 Region的机器当掉了,由于WAL已经存在HDFS上了,所以数据不会丢失
- WAL可以关闭,默认是开启的,但是最好别这样,因为出问题的时候数据会丢失
- 由于这篇是真正的自学文章,所以总结的并不是很全,我反复核实了一些概念,如果有错请及时指正谢谢