监控,是运维的眼睛,是稳定性建设中最重要的一环。
一般来讲,基础监控系统的主要功能就是发现问题。
故障发生前,通过监控的看图巡检,发现隐患;故障发生时,通过实时的告警,快速发现问题,定位问题所在;故障发生后,使用过去的历史数据图表,进行事后复盘,避免下次发生。
本篇文章,我们不讨论根因定位、故障自愈之类的高端主题,只跟大家聊一下笔者关于基础监控系统的一些建设心得。
一、一般监控系统的功能
一般的基础监控系统,主要有看图和告警两大功能,通过这两大功能,满足上述的发现问题的需求。
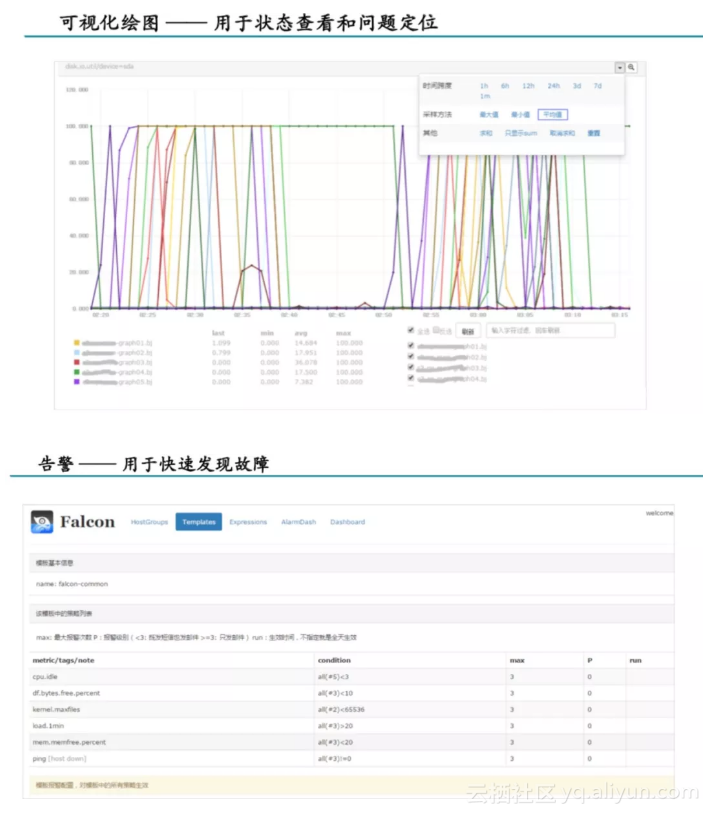
看图的功能,在看单张图的基础上,大部分监控系统会定制一个监控大盘的功能,将多张定义好的监控图,放在一个页面,记录一个URL,每次只要打开这个URL,就能看到自己定义好的所有监控图。
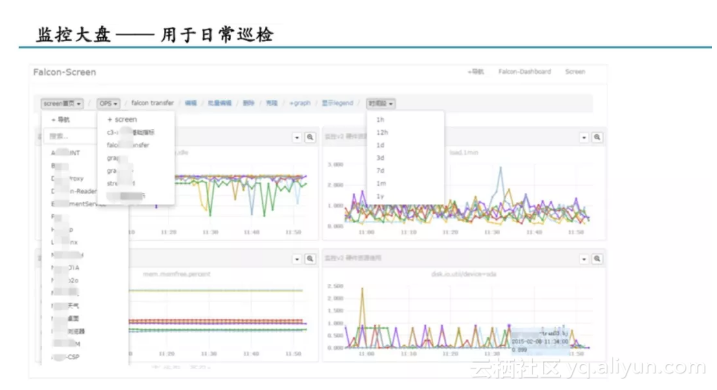
Open-Falcon监控大盘
监控大盘主要适合运维定时巡检的场景。比方说,运维同学把所有业务的核心指标都放在一个监控大盘里,每天早上只要打开这个页面,就可以看到自己业务最核心指标的情况,流量变化、稳定性隐患,一目了然。
二、监控系统模块拆解
我们以Open-Falcon架构图为例,其实这张图看起来复杂,拆解起来却很简单:
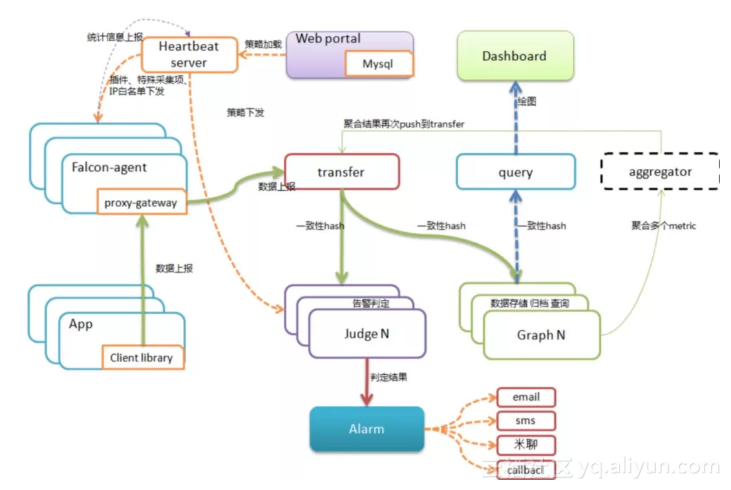
Open-Falcon架构图
绿色的实线是数据的上报流;橙色的虚线是策略的分发流;蓝色的虚线是看图的数据流。
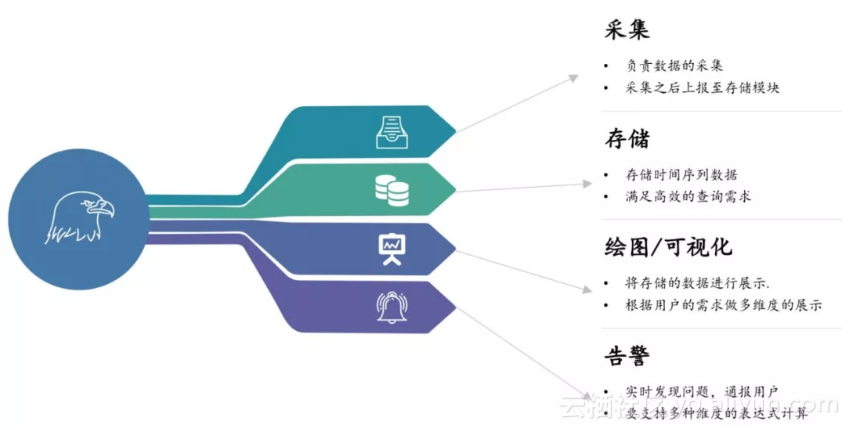
一般监控系统架构图
整体来看,一般的监控系统分为四部分:
● 采集: 对应Open-Falcon的Agent以及App library;● 存储: 对应Open-Falcon的Transfer、Query和Graph;
● 告警: 对应Open-Falcon的Judge、Alarm;
● 绘图:对应Open-Falcon的Dashboard。
1、数据采集的原则
数据采集,说起来比较简单,只要把数据报上来就行,具体怎么采集,那就八仙过海各显神通了。但是我们作为平台的设计者,必须要考虑标准化与规范化。
标准化,即抽象出统一的数据模型,用以支持各种自定义的采集数据。

Open-Falcon数据模型
这里值得一提的是,确定统一的数据模型,非但不会影响各种自定义的采集需求,反而能更灵活的支撑各种自定义的需求。
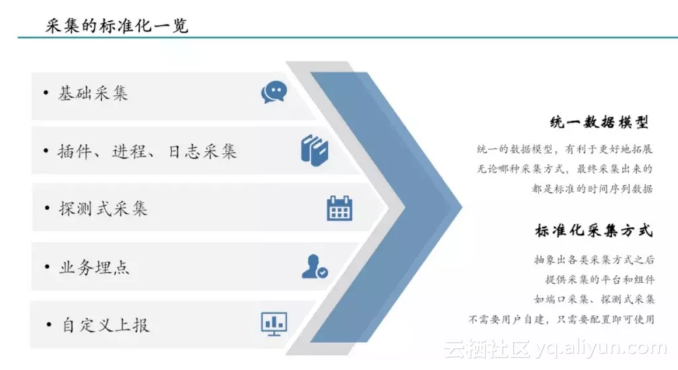
采集标准化一览
另一个需要注意的,就是采集方式的标准化。
我们采集端口、进程、日志、流量的各方面数据的方式,这个做好标准之后,监控的数据就会很规范。我们在一个业务线所做的稳定性建设方案,就可以无缝地迁移到另一个业务线,无需重复造轮子,而且是摸索很久之后的最佳实践。
2、存储建设的关键点
存储的建设,我觉得很重要的有三点:
功能
从功能上来讲,数据的存储比较简单,只要能存取时间序列数据即可,这一点,业界所有的时序数据库都可以做到。
但是,高端的绘图能力和强大的告警能力,大都会依赖动态的tag关联补全,这个索引能力要根据设计的功能来酌情建设。
Open-Falcon的索引是放在MySQL里的,而且数据结构比较固定,在这方面的能力还有待加强。笔者公司为了满足需求,是自建了一套索引模块的。
性能
一般来讲,我们自己建设一套时间序列存储,成本还是很高的。因此对于大多数同学来说,大家经历的都是时间序列数据库的选择。
大家在选择合适的时序数据库时,在性能上主要要考虑两点:
● 一是数据的读写性能,尤其是并发读写时的性能,在建设之出,要做好压测和QPS的容量规划。● 二是监控的时序数据必须要做好降采样,也就是数据的定时归档。将过去一段时间的N个点,聚合成一个粗时间粒度的点。这里要注意,千万不要做定时任务,InfluxDB的定时降采样会带来非常大的CPU高峰,对于要应对高并发查询和写入的监控存储来说,这种性能的潮汐是非常危险的。
降采样这一点,Open-Falcon底层的RRDTool技术就非常优秀,采用的是写时降采样,数据点在写入的过程中,降采样已经做好了,虽然会一定程度上带来一点性能消耗,但不会出现性能的瓶颈。
容量
无论什么样的存储,无论效率和压缩比有多高,总是会满的。这种时候,扩展就变成了一个绕不过去的命题。
关于容量方面,要强调的是,必须要有分布式的架构,可以随时扩容。
3、绘图功能的考量
绘图功能的定制,因人和业务而异。从笔者公司的建设经验来看,给大家三条建议:
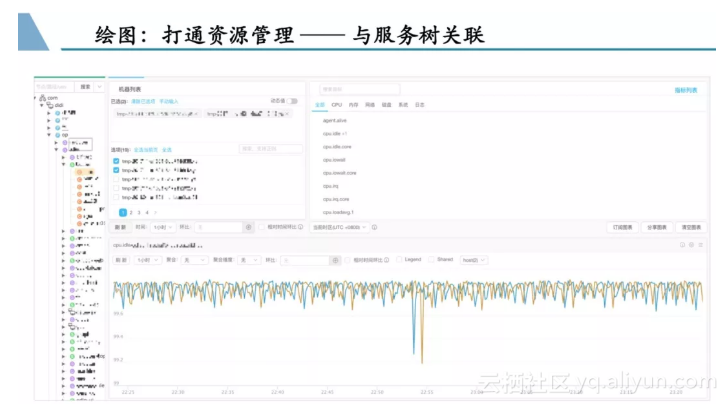
监控与服务树的打通
与资源管理(服务树系统)打通
监控系统,看的是机器的资源与运行的服务情况;资源管理,管理的是资源的归属情况。因此通过资源管理树,快速筛选出机器列表,进而一键查看监控图,可能是每个公司都会有的需求。
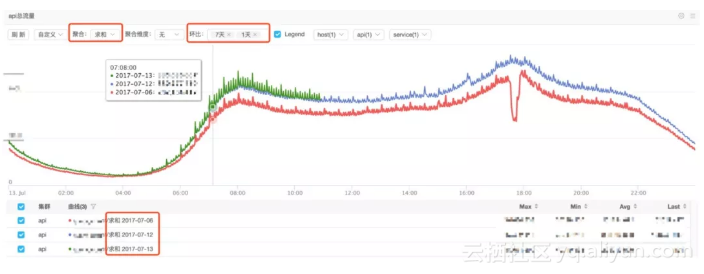
监控看图案例
数据横向的比较
在一张监控图中,同时显示当前与一段时间的环比,是一种发现问题的非常好的手段。
如上图,绿线代表今天的数据情况,蓝线代表一天前,红线代表7天前,通过对趋势的比较,可以很容易把握住服务的状态,哪里出问题一目了然。
数据纵向的聚合
假设我有一个节点,下有十台机器,我显示这十台机器的情况,就要有十条曲线。但我现在想要看一个整个节点的总体情况,那曲线的聚合就必不可少了。可以通过将多条曲线,同一时刻的数据相加或者求平均,来进行数据的聚合,用以体现出一个总体的情况。
4、如何让报警能力更加强大
告警一般来讲,需要两部分数据:
● 配置数据, 其获取见仁见智,不涉及性能问题,可以通过队列来通知,也可以定时拉取,只要保证好一致性和实时性就好了。● 监控数据, 其获取一般来讲,分为“推”和“拉”两种模式:
推模式——告警数据在上报时,自动推往告警模块
这种模式最大的一个优点就是实时性好,因为报警的模块可以第一时间拿到这个数据。
但是“推模式”有很致命的缺点:首先数据是全量灌过来的,解析和暂存会消耗大量的内存;而且这种模式,报警模块只能按照数据来进行分片,如果需要聚合场景计算,很可能这部分数据推往了不同的报警节点,就无法满足了。
拉模式——由告警模块定时从存储拉取监控数据
“拉”模式最大的好处在于,报警分片可以按照策略来分片,这样报警模块只需要拉取自己需要的数据即可,而且可以完美支持聚合场景,减少了很大一部分内存消耗。
而“拉模式”的缺点在于,监控的数据体量非常庞大,高并发的查询会对存储集群造成极大的压力。此处如果出现性能瓶颈,可以考虑监控数据的冷热分离。
三、监控的稳定性架构
监控系统,是稳定性工作的基石。如果监控系统都不够稳定,那我们依赖监控系统进行稳定性建设就无从谈起。
最后,给大家分享几个笔者公司在建设监控系统时的稳定性架构,有问题大家可以随时指出:
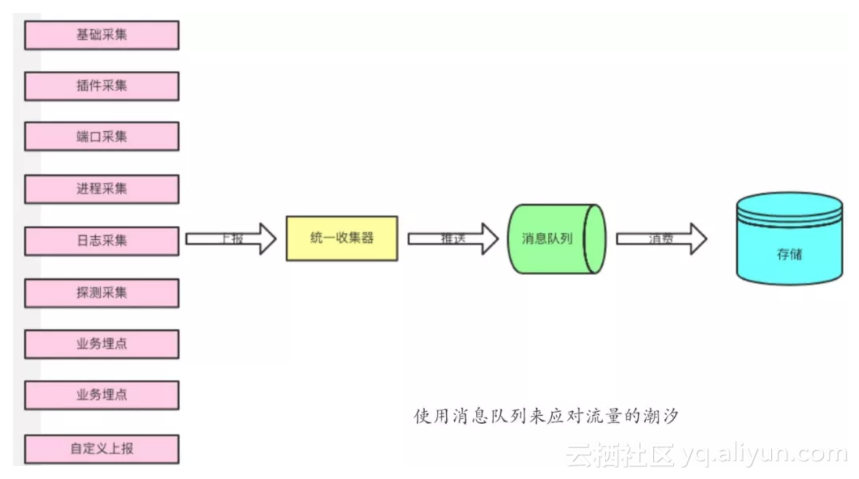
在数据上报的链路建设中,可以考虑使用消息队列来应对流量的潮汐。因为监控数据的上报,尤其是用户自定义数据的上报,很可能不是均匀的,会与流量、业务峰谷有关。此时通过一个消息队列来缓冲大批量的没有时间处理的数据,是一个不错的选择。
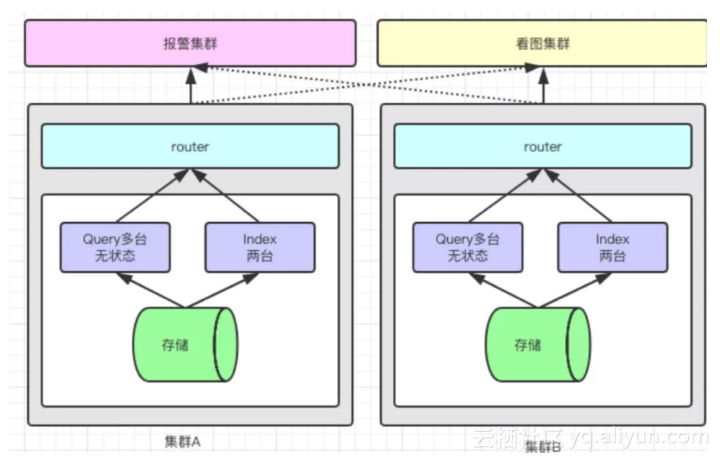
双活可应对实例故障与专线断开
存储的稳定性,可以考虑数据双写。两个集群分开部署。可以应对专线断开以及分片挂掉两种情况。
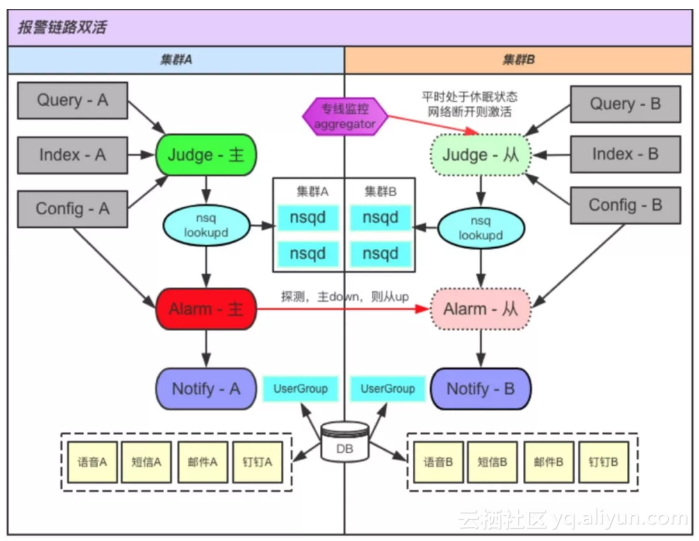
告警的稳定性可考虑主从模式
告警其实是比较难做双活的,尤其是Alarm这种报警的收敛模块。因为双活意味着两份,两份服务,也意味着同一条报警发两次。这明显不符合预期。
因此,对于告警体系,给大家推荐我们的主从模式:从集群平时处于休眠状态,会定时的对主集群进行探测,一旦发现主集群挂掉,或探测不通,就将自身拉起,达到一个故障时间内的双活。
以上就是笔者关于监控系统的一些建设心得的大纲,欢迎大家下方留言讨论交流。后续会针对每一个方向写一篇深入的专题,欢迎继续关注dbaplus社群内容分享。
Q & A
Q1:请问你们的服务器都在机房还是云?针对阿里云上的服务器有什么好的办法采集吗?
A:监控的标准化做好之后,无论是物理机还是云服务器,都是一样的。只是数据上报的通路可能需要费心建设。云主机理论上也可以通过部署Agent的方式来进行采集,监控系统也最好放在他们本机房内。或者如果网络资源允许,数据回源也是一个不错的选择。
Q2:对于中小企业监控建设有什么建议吗?比如从哪开始,如何进化?
A2:中小企业、人力资源、服务器资源都会有建设的掣肘。因此我建议前期先采用开源的解决方案,理论上可以支撑公司发展很长一段时间。开源的Open-Falcon和Zabbix都是不错的选择。当机器数量超过5k或者公司业务发展已经明显感觉到监控系统功能不够的时候,可以再进行一次全面的重构。
原文发布时间为:2018-11-15
本文作者:高家升