热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
fuzzywuzzy,一个好用的 Python 库!
pyautogui,一个超酷的 Python 库!
six,一个神奇的 Python 版本兼容工具库!
toapi,一个强大的 Python Web API库!
MechanicalSoup,一个非常实用的 Python 自动化浏览器交互工具库!
每天解析一个脚本(51)
vulture,一个有趣的 Python 死代码清除库!
var let const 的区别和使用场景
什么是事件代理?什么是事件委托?
什么是全局污染?如何避免全局污染
js操作字符串的相关方法
Python中starmap有什么用的?
函数声明与函数表达式的区别
js 操作数组的方法
document.write和innerHTML和innerText的区别
lida,一个超级厉害的 Python 库!
jQuery 选择器有几种,分别是什么
JavaScript如何设置定时器,怎么清除定时器
构建未来:云原生架构在现代企业中的应用与挑战
箭头函数和普通函数的区别
Python 弱引用全解析:深入探讨对象引用机制!
document.write和innerHTML、innerText 的区别
aiofiles,一个超酷的 Python 异步编程库!
给input框设置成选择日期,并且精确到时分秒
Python 多线程编程实战:threading 模块的最佳实践
datalist 是什么?以及作用是什么?
node实战——后端koa结合jwt连接mysql实现权限登录(node后端就业储备知识)
bashplotlib,一个有趣的 Python 数据可视化图形库
探秘Python的Pipeline魔法
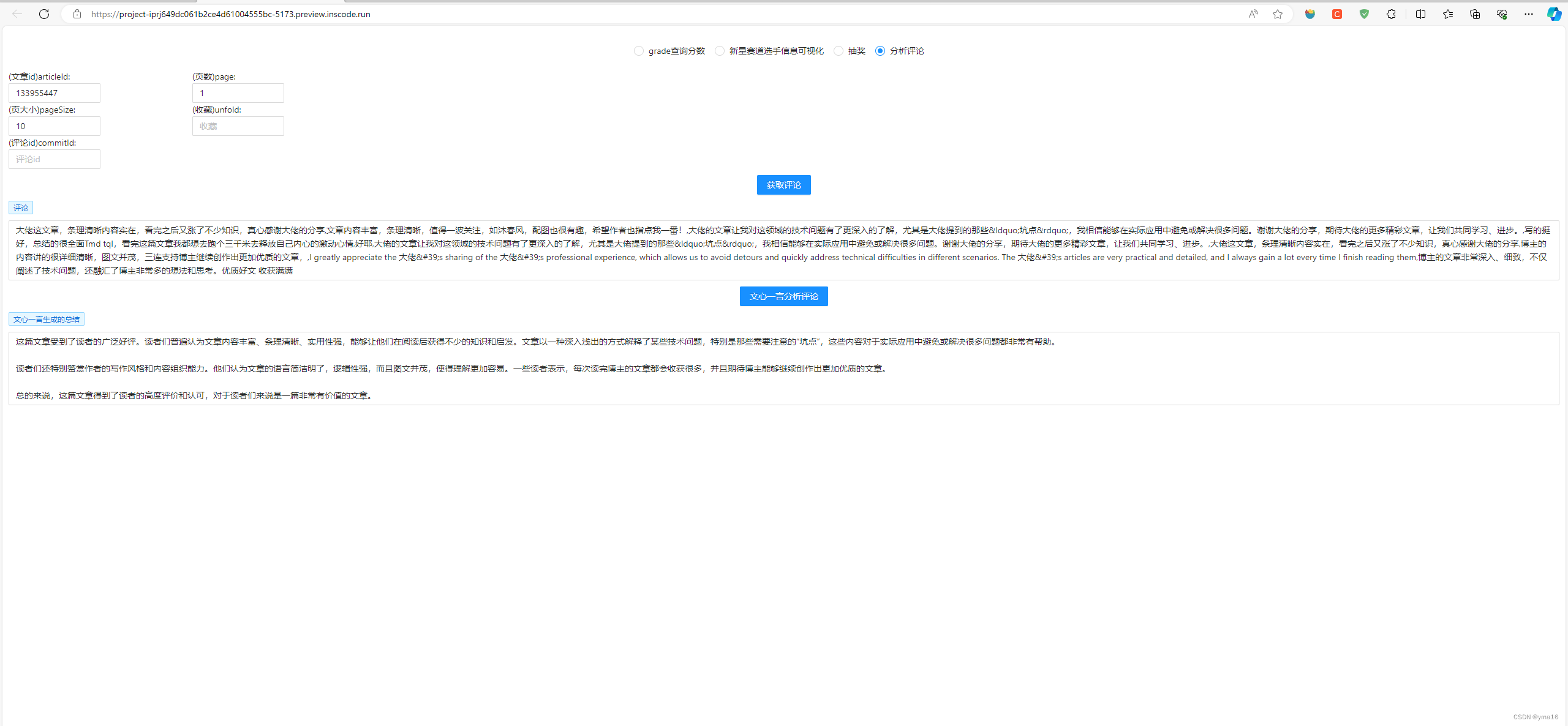
让大模型分析csdn文章质量 —— 提取csdn博客评论在文心一言分析评论区内容
网络防御先锋:洞悉网络安全漏洞与加固信息防线
beets,一个有趣的 Python 音乐信息管理工具!
网络安全与信息安全:防护之道与加密技术的深度剖析
每天解析一个脚本(50)
Python复合型数据避坑指南
5款最受欢迎的邮件营销系统有什么?
scons,一个实用的 Python 构建工具!
AI图像放大器:自媒体时代的利器
如何使用 Pandas 删除 DataFrame 中的非数字类型数据?
深入理解PHP中的命名空间
maven仓库的版本列举
Python中检查一个数字是否是科技数的完整指南
未来交织:新兴技术在数字化转型中的融合与应用
pycallgraph,一个好用的 Python 代码可视化库!
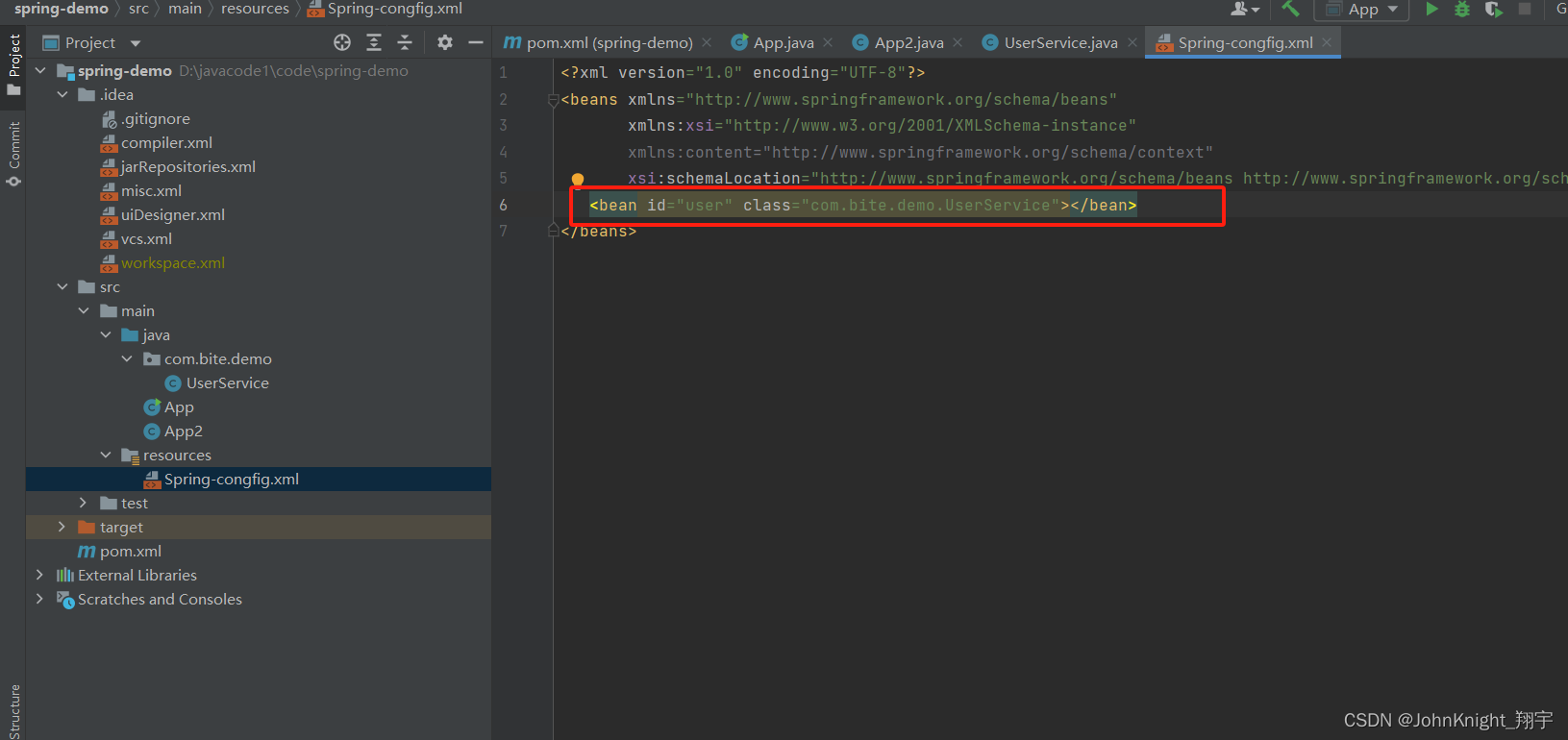
Spring简单的存储和读取
每天解析一个脚本(49)